[SPARK-26625] Add oauthToken to spark.kubernetes.authenticate.submission.oauthToken#23554
Closed
vinooganesh wants to merge 1453 commits intoapache:masterfrom
Closed
[SPARK-26625] Add oauthToken to spark.kubernetes.authenticate.submission.oauthToken#23554vinooganesh wants to merge 1453 commits intoapache:masterfrom
vinooganesh wants to merge 1453 commits intoapache:masterfrom
Conversation
Update to upstream
…torizerModel ## What changes were proposed in this pull request? Adding test for default params for `CountVectorizerModel` constructed from vocabulary. This required that the param `maxDF` be added, which was done in SPARK-23615. ## How was this patch tested? Added an explicit test for CountVectorizerModel in DefaultValuesTests. Author: Bryan Cutler <cutlerb@gmail.com> Closes apache#20942 from BryanCutler/pyspark-CountVectorizerModel-default-param-test-SPARK-15009.
## What changes were proposed in this pull request? Kubernetes driver and executor pods should request `memory + memoryOverhead` as their resources instead of just `memory`, see https://issues.apache.org/jira/browse/SPARK-23825 ## How was this patch tested? Existing unit tests were adapted. Author: David Vogelbacher <dvogelbacher@palantir.com> Closes apache#20943 from dvogelbacher/spark-23825.
…utor cores ## What changes were proposed in this pull request? As mentioned in SPARK-23285, this PR introduces a new configuration property `spark.kubernetes.executor.cores` for specifying the physical CPU cores requested for each executor pod. This is to avoid changing the semantics of `spark.executor.cores` and `spark.task.cpus` and their role in task scheduling, task parallelism, dynamic resource allocation, etc. The new configuration property only determines the physical CPU cores available to an executor. An executor can still run multiple tasks simultaneously by using appropriate values for `spark.executor.cores` and `spark.task.cpus`. ## How was this patch tested? Unit tests. felixcheung srowen jiangxb1987 jerryshao mccheah foxish Author: Yinan Li <ynli@google.com> Author: Yinan Li <liyinan926@gmail.com> Closes apache#20553 from liyinan926/master.
## What changes were proposed in this pull request? This PR implemented the following cleanups related to `UnsafeWriter` class: - Remove code duplication between `UnsafeRowWriter` and `UnsafeArrayWriter` - Make `BufferHolder` class internal by delegating its accessor methods to `UnsafeWriter` - Replace `UnsafeRow.setTotalSize(...)` with `UnsafeRowWriter.setTotalSize()` ## How was this patch tested? Tested by existing UTs Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com> Closes apache#20850 from kiszk/SPARK-23713.
…Server test. It was possible that the disconnect() was called on the handle before the server had received the handshake messages, so no connection was yet attached to the handle. The fix waits until we're sure the handle has been mapped to a client connection. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes apache#20950 from vanzin/SPARK-23834.
## What changes were proposed in this pull request? Introduce `handleInvalid` parameter in `VectorAssembler` that can take in `"keep", "skip", "error"` options. "error" throws an error on seeing a row containing a `null`, "skip" filters out all such rows, and "keep" adds relevant number of NaN. "keep" figures out an example to find out what this number of NaN s should be added and throws an error when no such number could be found. ## How was this patch tested? Unit tests are added to check the behavior of `assemble` on specific rows and the transformer is called on `DataFrame`s of different configurations to test different corner cases. Author: Yogesh Garg <yogesh(dot)garg()databricks(dot)com> Author: Bago Amirbekian <bago@databricks.com> Author: Yogesh Garg <1059168+yogeshg@users.noreply.github.com> Closes apache#20829 from yogeshg/rformula_handleinvalid.
These tests can fail with a timeout if the remote repos are not responding, or slow. The tests don't need anything from those repos, so use an empty ivy config file to avoid setting up the defaults. The tests are passing reliably for me locally now, and failing more often than not today without this change since http://dl.bintray.com/spark-packages/maven doesn't seem to be loading from my machine. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes apache#20916 from vanzin/SPARK-19964.
## What changes were proposed in this pull request? Easy fix in the markdown. ## How was this patch tested? jekyII build test manually. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: lemonjing <932191671@qq.com> Closes apache#20897 from Lemonjing/master.
## What changes were proposed in this pull request? Address apache#20924 (comment), show block manager id when remove RDD/Broadcast fails. ## How was this patch tested? N/A Author: Xingbo Jiang <xingbo.jiang@databricks.com> Closes apache#20960 from jiangxb1987/bmid.
## What changes were proposed in this pull request? Add interpreted execution for `MapObjects` expression. ## How was this patch tested? Added unit test. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes apache#20771 from viirya/SPARK-23587.
## What changes were proposed in this pull request? Currently, the active spark session is set inconsistently (e.g., in createDataFrame, prior to query execution). Many places in spark also incorrectly query active session when they should be calling activeSession.getOrElse(defaultSession) and so might get None even if a Spark session exists. The semantics here can be cleaned up if we also set the active session when the default session is set. Related: https://github.com/apache/spark/pull/20926/files ## How was this patch tested? Unit test, existing test. Note that if apache#20926 merges first we should also update the tests there. Author: Eric Liang <ekl@databricks.com> Closes apache#20927 from ericl/active-session-cleanup.
…esolved state ## What changes were proposed in this pull request? Add cast to nulls introduced by PropagateEmptyRelation so in cases they're part of coalesce they will not break its type checking rules ## How was this patch tested? Added unit test Author: Robert Kruszewski <robertk@palantir.com> Closes apache#20914 from robert3005/rk/propagate-empty-fix.
## What changes were proposed in this pull request? In TestHive, the base spark session does this in getOrCreate(), we emulate that behavior for tests. ## How was this patch tested? N/A Author: gatorsmile <gatorsmile@gmail.com> Closes apache#20969 from gatorsmile/setDefault.
## What changes were proposed in this pull request?
This pr added a new optimizer rule `UpdateNullabilityInAttributeReferences ` to update the nullability that `Filter` changes when having `IsNotNull`. In the master, optimized plans do not respect the nullability when `Filter` has `IsNotNull`. This wrongly generates unnecessary code. For example:
```
scala> val df = Seq((Some(1), Some(2))).toDF("a", "b")
scala> val bIsNotNull = df.where($"b" =!= 2).select($"b")
scala> val targetQuery = bIsNotNull.distinct
scala> val targetQuery.queryExecution.optimizedPlan.output(0).nullable
res5: Boolean = true
scala> targetQuery.debugCodegen
Found 2 WholeStageCodegen subtrees.
== Subtree 1 / 2 ==
*HashAggregate(keys=[b#19], functions=[], output=[b#19])
+- Exchange hashpartitioning(b#19, 200)
+- *HashAggregate(keys=[b#19], functions=[], output=[b#19])
+- *Project [_2#16 AS b#19]
+- *Filter isnotnull(_2#16)
+- LocalTableScan [_1#15, _2#16]
Generated code:
...
/* 124 */ protected void processNext() throws java.io.IOException {
...
/* 132 */ // output the result
/* 133 */
/* 134 */ while (agg_mapIter.next()) {
/* 135 */ wholestagecodegen_numOutputRows.add(1);
/* 136 */ UnsafeRow agg_aggKey = (UnsafeRow) agg_mapIter.getKey();
/* 137 */ UnsafeRow agg_aggBuffer = (UnsafeRow) agg_mapIter.getValue();
/* 138 */
/* 139 */ boolean agg_isNull4 = agg_aggKey.isNullAt(0);
/* 140 */ int agg_value4 = agg_isNull4 ? -1 : (agg_aggKey.getInt(0));
/* 141 */ agg_rowWriter1.zeroOutNullBytes();
/* 142 */
// We don't need this NULL check because NULL is filtered out in `$"b" =!=2`
/* 143 */ if (agg_isNull4) {
/* 144 */ agg_rowWriter1.setNullAt(0);
/* 145 */ } else {
/* 146 */ agg_rowWriter1.write(0, agg_value4);
/* 147 */ }
/* 148 */ append(agg_result1);
/* 149 */
/* 150 */ if (shouldStop()) return;
/* 151 */ }
/* 152 */
/* 153 */ agg_mapIter.close();
/* 154 */ if (agg_sorter == null) {
/* 155 */ agg_hashMap.free();
/* 156 */ }
/* 157 */ }
/* 158 */
/* 159 */ }
```
In the line 143, we don't need this NULL check because NULL is filtered out in `$"b" =!=2`.
This pr could remove this NULL check;
```
scala> val targetQuery.queryExecution.optimizedPlan.output(0).nullable
res5: Boolean = false
scala> targetQuery.debugCodegen
...
Generated code:
...
/* 144 */ protected void processNext() throws java.io.IOException {
...
/* 152 */ // output the result
/* 153 */
/* 154 */ while (agg_mapIter.next()) {
/* 155 */ wholestagecodegen_numOutputRows.add(1);
/* 156 */ UnsafeRow agg_aggKey = (UnsafeRow) agg_mapIter.getKey();
/* 157 */ UnsafeRow agg_aggBuffer = (UnsafeRow) agg_mapIter.getValue();
/* 158 */
/* 159 */ int agg_value4 = agg_aggKey.getInt(0);
/* 160 */ agg_rowWriter1.write(0, agg_value4);
/* 161 */ append(agg_result1);
/* 162 */
/* 163 */ if (shouldStop()) return;
/* 164 */ }
/* 165 */
/* 166 */ agg_mapIter.close();
/* 167 */ if (agg_sorter == null) {
/* 168 */ agg_hashMap.free();
/* 169 */ }
/* 170 */ }
```
## How was this patch tested?
Added `UpdateNullabilityInAttributeReferencesSuite` for unit tests.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes apache#18576 from maropu/SPARK-21351.
## What changes were proposed in this pull request? Migrate foreach sink to DataSourceV2. Since the previous attempt at this PR apache#20552, we've changed and strictly defined the lifecycle of writer components. This means we no longer need the complicated lifecycle shim from that PR; it just naturally works. ## How was this patch tested? existing tests Author: Jose Torres <torres.joseph.f+github@gmail.com> Closes apache#20951 from jose-torres/foreach.
Small upstream bump
## What changes were proposed in this pull request? This pr added interpreted execution for `Invoke`. ## How was this patch tested? Added tests in `ObjectExpressionsSuite`. Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com> Closes apache#20797 from kiszk/SPARK-28583.
….imagePullSecrets ## What changes were proposed in this pull request? Pass through the `imagePullSecrets` option to the k8s pod in order to allow user to access private image registries. See https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/ ## How was this patch tested? Unit tests + manual testing. Manual testing procedure: 1. Have private image registry. 2. Spark-submit application with no `spark.kubernetes.imagePullSecret` set. Do `kubectl describe pod ...`. See the error message: ``` Error syncing pod, skipping: failed to "StartContainer" for "spark-kubernetes-driver" with ErrImagePull: "rpc error: code = 2 desc = Error: Status 400 trying to pull repository ...: \"{\\n \\\"errors\\\" : [ {\\n \\\"status\\\" : 400,\\n \\\"message\\\" : \\\"Unsupported docker v1 repository request for '...'\\\"\\n } ]\\n}\"" ``` 3. Create secret `kubectl create secret docker-registry ...` 4. Spark-submit with `spark.kubernetes.imagePullSecret` set to the new secret. See that deployment was successful. Author: Andrew Korzhuev <andrew.korzhuev@klarna.com> Author: Andrew Korzhuev <korzhuev@andrusha.me> Closes apache#20811 from andrusha/spark-23668-image-pull-secrets.
… SQL tab ## What changes were proposed in this pull request? A running SQL query would appear as completed in the Spark UI:  We can see the query in "Completed queries", while in in the job page we see it's still running Job 132. 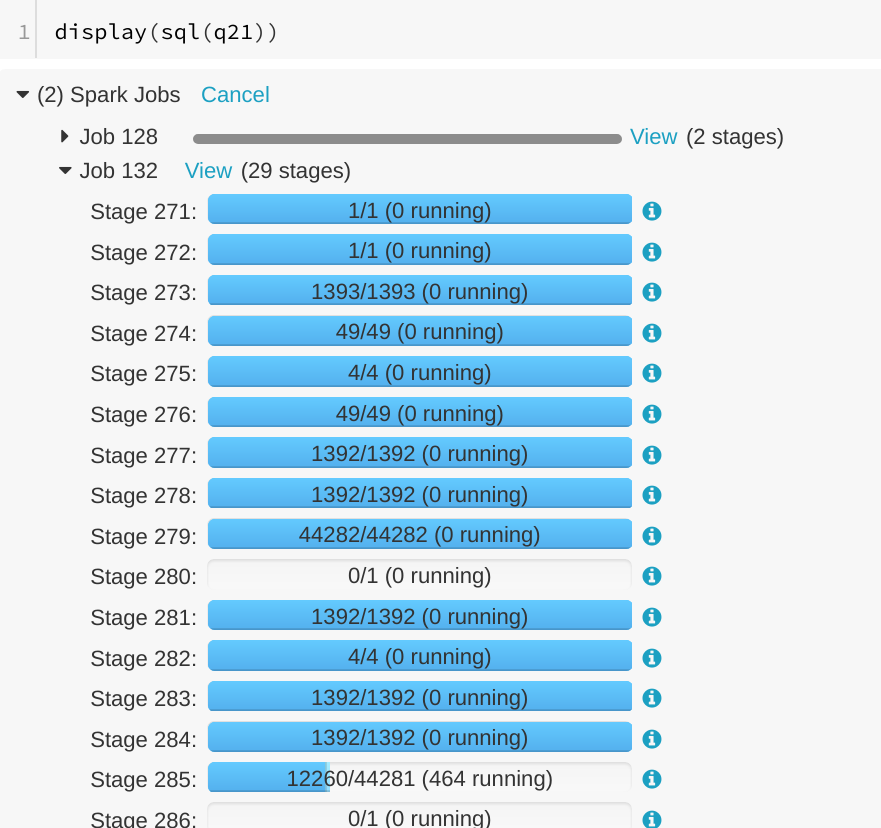 After some time in the query still appears in "Completed queries" (while it's still running), but the "Duration" gets increased.  To reproduce, we can run a query with multiple jobs. E.g. Run TPCDS q6. The reason is that updates from executions are written into kvstore periodically, and the job start event may be missed. ## How was this patch tested? Manually run the job again and check the SQL Tab. The fix is pretty simple. Author: Gengliang Wang <gengliang.wang@databricks.com> Closes apache#20955 from gengliangwang/jobCompleted.
{kind=link}
{kind=link}
{kind=link}
…tor is killed multiple times. ## What changes were proposed in this pull request? `YarnAllocator` uses `numExecutorsRunning` to track the number of running executor. `numExecutorsRunning` is used to check if there're executors missing and need to allocate more. In current code, `numExecutorsRunning` can be negative when driver asks to kill a same idle executor multiple times. ## How was this patch tested? UT added Author: jinxing <jinxing6042@126.com> Closes apache#20781 from jinxing64/SPARK-23637.
…xpression ## What changes were proposed in this pull request? Add interpreted execution for `InitializeJavaBean` expression. ## How was this patch tested? Added unit test. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes apache#20756 from viirya/SPARK-23593.
## What changes were proposed in this pull request? This pr added interpreted execution for `StaticInvoke`. ## How was this patch tested? Added tests in `ObjectExpressionsSuite`. Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com> Closes apache#20753 from kiszk/SPARK-23582.
…vaBean expression" This reverts commit c5c8b54.
…xpression ## What changes were proposed in this pull request? Add interpreted execution for `InitializeJavaBean` expression. ## How was this patch tested? Added unit test. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes apache#20985 from viirya/SPARK-23593-2.
…veral types of memory block ## What changes were proposed in this pull request? This PR allows us to use one of several types of `MemoryBlock`, such as byte array, int array, long array, or `java.nio.DirectByteBuffer`. To use `java.nio.DirectByteBuffer` allows to have off heap memory which is automatically deallocated by JVM. `MemoryBlock` class has primitive accessors like `Platform.getInt()`, `Platform.putint()`, or `Platform.copyMemory()`. This PR uses `MemoryBlock` for `OffHeapColumnVector`, `UTF8String`, and other places. This PR can improve performance of operations involving memory accesses (e.g. `UTF8String.trim`) by 1.8x. For now, this PR does not use `MemoryBlock` for `BufferHolder` based on cloud-fan's [suggestion](apache#11494 (comment)). Since this PR is a successor of apache#11494, close apache#11494. Many codes were ported from apache#11494. Many efforts were put here. **I think this PR should credit to yzotov.** This PR can achieve **1.1-1.4x performance improvements** for operations in `UTF8String` or `Murmur3_x86_32`. Other operations are almost comparable performances. Without this PR ``` OpenJDK 64-Bit Server VM 1.8.0_121-8u121-b13-0ubuntu1.16.04.2-b13 on Linux 4.4.0-22-generic Intel(R) Xeon(R) CPU E5-2667 v3 3.20GHz OpenJDK 64-Bit Server VM 1.8.0_121-8u121-b13-0ubuntu1.16.04.2-b13 on Linux 4.4.0-22-generic Intel(R) Xeon(R) CPU E5-2667 v3 3.20GHz Hash byte arrays with length 268435487: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative ------------------------------------------------------------------------------------------------ Murmur3_x86_32 526 / 536 0.0 131399881.5 1.0X UTF8String benchmark: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative ------------------------------------------------------------------------------------------------ hashCode 525 / 552 1022.6 1.0 1.0X substring 414 / 423 1298.0 0.8 1.3X ``` With this PR ``` OpenJDK 64-Bit Server VM 1.8.0_121-8u121-b13-0ubuntu1.16.04.2-b13 on Linux 4.4.0-22-generic Intel(R) Xeon(R) CPU E5-2667 v3 3.20GHz Hash byte arrays with length 268435487: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative ------------------------------------------------------------------------------------------------ Murmur3_x86_32 474 / 488 0.0 118552232.0 1.0X UTF8String benchmark: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative ------------------------------------------------------------------------------------------------ hashCode 476 / 480 1127.3 0.9 1.0X substring 287 / 291 1869.9 0.5 1.7X ``` Benchmark program ``` test("benchmark Murmur3_x86_32") { val length = 8192 * 32768 + 31 val seed = 42L val iters = 1 << 2 val random = new Random(seed) val arrays = Array.fill[MemoryBlock](numArrays) { val bytes = new Array[Byte](length) random.nextBytes(bytes) new ByteArrayMemoryBlock(bytes, Platform.BYTE_ARRAY_OFFSET, length) } val benchmark = new Benchmark("Hash byte arrays with length " + length, iters * numArrays, minNumIters = 20) benchmark.addCase("HiveHasher") { _: Int => var sum = 0L for (_ <- 0L until iters) { sum += HiveHasher.hashUnsafeBytesBlock( arrays(i), Platform.BYTE_ARRAY_OFFSET, length) } } benchmark.run() } test("benchmark UTF8String") { val N = 512 * 1024 * 1024 val iters = 2 val benchmark = new Benchmark("UTF8String benchmark", N, minNumIters = 20) val str0 = new java.io.StringWriter() { { for (i <- 0 until N) { write(" ") } } }.toString val s0 = UTF8String.fromString(str0) benchmark.addCase("hashCode") { _: Int => var h: Int = 0 for (_ <- 0L until iters) { h += s0.hashCode } } benchmark.addCase("substring") { _: Int => var s: UTF8String = null for (_ <- 0L until iters) { s = s0.substring(N / 2 - 5, N / 2 + 5) } } benchmark.run() } ``` I run [this benchmark program](https://gist.github.com/kiszk/94f75b506c93a663bbbc372ffe8f05de) using [the commit](apache@ee5a798). I got the following results: ``` OpenJDK 64-Bit Server VM 1.8.0_151-8u151-b12-0ubuntu0.16.04.2-b12 on Linux 4.4.0-66-generic Intel(R) Xeon(R) CPU E5-2667 v3 3.20GHz Memory access benchmarks: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative ------------------------------------------------------------------------------------------------ ByteArrayMemoryBlock get/putInt() 220 / 221 609.3 1.6 1.0X Platform get/putInt(byte[]) 220 / 236 610.9 1.6 1.0X Platform get/putInt(Object) 492 / 494 272.8 3.7 0.4X OnHeapMemoryBlock get/putLong() 322 / 323 416.5 2.4 0.7X long[] 221 / 221 608.0 1.6 1.0X Platform get/putLong(long[]) 321 / 321 418.7 2.4 0.7X Platform get/putLong(Object) 561 / 563 239.2 4.2 0.4X ``` I also run [this benchmark program](https://gist.github.com/kiszk/5fdb4e03733a5d110421177e289d1fb5) for comparing performance of `Platform.copyMemory()`. ``` OpenJDK 64-Bit Server VM 1.8.0_151-8u151-b12-0ubuntu0.16.04.2-b12 on Linux 4.4.0-66-generic Intel(R) Xeon(R) CPU E5-2667 v3 3.20GHz Platform copyMemory: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative ------------------------------------------------------------------------------------------------ Object to Object 1961 / 1967 8.6 116.9 1.0X System.arraycopy Object to Object 1917 / 1921 8.8 114.3 1.0X byte array to byte array 1961 / 1968 8.6 116.9 1.0X System.arraycopy byte array to byte array 1909 / 1937 8.8 113.8 1.0X int array to int array 1921 / 1990 8.7 114.5 1.0X double array to double array 1918 / 1923 8.7 114.3 1.0X Object to byte array 1961 / 1967 8.6 116.9 1.0X Object to short array 1965 / 1972 8.5 117.1 1.0X Object to int array 1910 / 1915 8.8 113.9 1.0X Object to float array 1971 / 1978 8.5 117.5 1.0X Object to double array 1919 / 1944 8.7 114.4 1.0X byte array to Object 1959 / 1967 8.6 116.8 1.0X int array to Object 1961 / 1970 8.6 116.9 1.0X double array to Object 1917 / 1924 8.8 114.3 1.0X ``` These results show three facts: 1. According to the second/third or sixth/seventh results in the first experiment, if we use `Platform.get/putInt(Object)`, we achieve more than 2x worse performance than `Platform.get/putInt(byte[])` with concrete type (i.e. `byte[]`). 2. According to the second/third or fourth/fifth/sixth results in the first experiment, the fastest way to access an array element on Java heap is `array[]`. **Cons of `array[]` is that it is not possible to support unaligned-8byte access.** 3. According to the first/second/third or fourth/sixth/seventh results in the first experiment, `getInt()/putInt() or getLong()/putLong()` in subclasses of `MemoryBlock` can achieve comparable performance to `Platform.get/putInt()` or `Platform.get/putLong()` with concrete type (second or sixth result). There is no overhead regarding virtual call. 4. According to results in the second experiment, for `Platform.copy()`, to pass `Object` can achieve the same performance as to pass any type of primitive array as source or destination. 5. According to second/fourth results in the second experiment, `Platform.copy()` can achieve the same performance as `System.arrayCopy`. **It would be good to use `Platform.copy()` since `Platform.copy()` can take any types for src and dst.** We are incrementally replace `Platform.get/putXXX` with `MemoryBlock.get/putXXX`. This is because we have two advantages. 1) Achieve better performance due to having a concrete type for an array. 2) Use simple OO design instead of passing `Object` It is easy to use `MemoryBlock` in `InternalRow`, `BufferHolder`, `TaskMemoryManager`, and others that are already abstracted. It is not easy to use `MemoryBlock` in utility classes related to hashing or others. Other candidates are - UnsafeRow, UnsafeArrayData, UnsafeMapData, SpecificUnsafeRowJoiner - UTF8StringBuffer - BufferHolder - TaskMemoryManager - OnHeapColumnVector - BytesToBytesMap - CachedBatch - classes for hash - others. ## How was this patch tested? Added `UnsafeMemoryAllocator` Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com> Closes apache#19222 from kiszk/SPARK-10399.
…bler to handle invalid values in non-string columns ## What changes were proposed in this pull request? `handleInvalid` Param was forwarded to the VectorAssembler used by RFormula. ## How was this patch tested? added a test and ran all tests for RFormula and VectorAssembler Author: Yogesh Garg <yogesh(dot)garg()databricks(dot)com> Closes apache#20970 from yogeshg/spark_23562.
By storing previous environments that are the same within a single Java executor process, we are able to reuse environments that we know are exactly the same. This cache needs to be protected by a lock to prevent concurrent modifications since we do not want extra copies of the environment on disk.
[SPARK-25891][PYTHON] Upgrade to Py4J 0.10.8.1
Allows dynamically scaling executors up and down without external shuffle service. Tracks shuffle locations to know if executors can be safely scaled down.
It's impossible to use zipTree or fileTree to deploy files out of the resources folder. To make matters cleaner, build the resources into a zip file in the jar, then use a simple stream copy to write the zip file to disk. Then use a sync task to actually unpack the zip file. The result is avoiding any need to do any zip-specific magic to extract the files.
###### _excavator_ is a bot for automating changes across repositories.
Changes produced by the roomba/latest-gradle-wrapper-oss check.
{runtimeCheckDesc}
To enable or disable this check, please contact the maintainers of Excavator.
Need to figure out how to merge the checkstyles because otherwise we will end up with a lot of mess
###### _excavator_ is a bot for automating changes across repositories.
Changes produced by the versions-props/upgrade-all check.
{runtimeCheckDesc}
To enable or disable this check, please contact the maintainers of Excavator.
## Upstream SPARK-XXXXX ticket and PR link (if not applicable, explain) Not filed in upstream, touches code for conda. ## What changes were proposed in this pull request? rLibDir contains a sequence of possible paths for the SparkR package on the executor and is passed on to the R daemon with the SPARKR_RLIBDIR environment variable. This PR filters rLibDir for paths that exist before setting SPARKR_RLIBDIR, retaining existing functionality to preferentially choose a YARN or local SparkR install over conda if both are present. See daemon.R: https://github.com/palantir/spark/blob/master/R/pkg/inst/worker/daemon.R#L23 Fixes #456 ## How was this patch tested? Manually testing cherry picked on older version Please review http://spark.apache.org/contributing.html before opening a pull request.
…SPARK-21608" This reverts commit 89d748b.
This PR is to add back `unionAll`, which is widely used. The name is also consistent with our ANSI SQL. We also have the corresponding `intersectAll` and `exceptAll`, which were introduced in Spark 2.4. Added a test case in DataFrameSuite Closes apache#23131 from gatorsmile/addBackUnionAll. Authored-by: gatorsmile <gatorsmile@gmail.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
Add SafeLogging (similar to #425) to more classes that can be useful: - k8s classes - CoarseGrainedSchedulerBackend - SparkContext - MemoryStore - Executor - CoarseGrainedExecutorBackend - TorrentBroadCast and Broadcast
…only parent of the dist (#467)
…RK-21608" This reverts commit 9cf9a83.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
20 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
The regex (spark.redaction.regex) that is used to decide which config properties or environment settings are sensitive should also include oauthToken to match spark.kubernetes.authenticate.submission.oauthToken
How was this patch tested?
Simple regex addition - happy to add a test if needed.