[SPARK-26667][DOC] Add Scanning Input Table to Performance Tuning Guide#23593
Conversation
|
Can one of the admins verify this patch? |
docs/sql-performance-tuning.md
Outdated
There was a problem hiding this comment.
This at least needs some proofreading, like hadoop -> Hadoop, Max -> max, we scanning -> scanning.
This seems fairly niche and not so SQL related.
There was a problem hiding this comment.
Proofread. I added it in SQL Tuning because we can set it before executing a SQL. I'd appreciate it if you could give more suggestions.
|
Could you attach the screenshot of newly added documentation part? |
|
I don't think a screenshot helps? it's just text, not a UI change. |
Added a screenshot. |
docs/sql-performance-tuning.md
Outdated
There was a problem hiding this comment.
I think this only applies when we read Hive table from Spark. BTW, is it something we should document at Spark side if so?
There was a problem hiding this comment.
Done, I think we can optimize the input format at Spark side (#23506). Maybe we can document these configurations to tell those who want to tune Spark SQL?
Scanning Input Table to Performance Tuning GuideScanning Input Table to Performance Tuning Guide
|
Hi, @Deegue . Are you still working on this PR? |
Yes, I'm waiting for more reviews or I think maybe, we could merge this one. |
 srowen
left a comment
srowen
left a comment
There was a problem hiding this comment.
I don't disagree with the general comments here, but I'm not sure it adds enough concise and precise information to be worthwhile. It would need to be significantly rewritten. It's also fairly specific to HDFS, right?
Yes, you are right. I will rewrite the docs and make it concise and precise. |
|
Rewrote the doc and updated the screenshot, could you please review again? @srowen @dongjoon-hyun |
|
I am with @srowen. I feel like it should better be in HDFS and users should read that. |
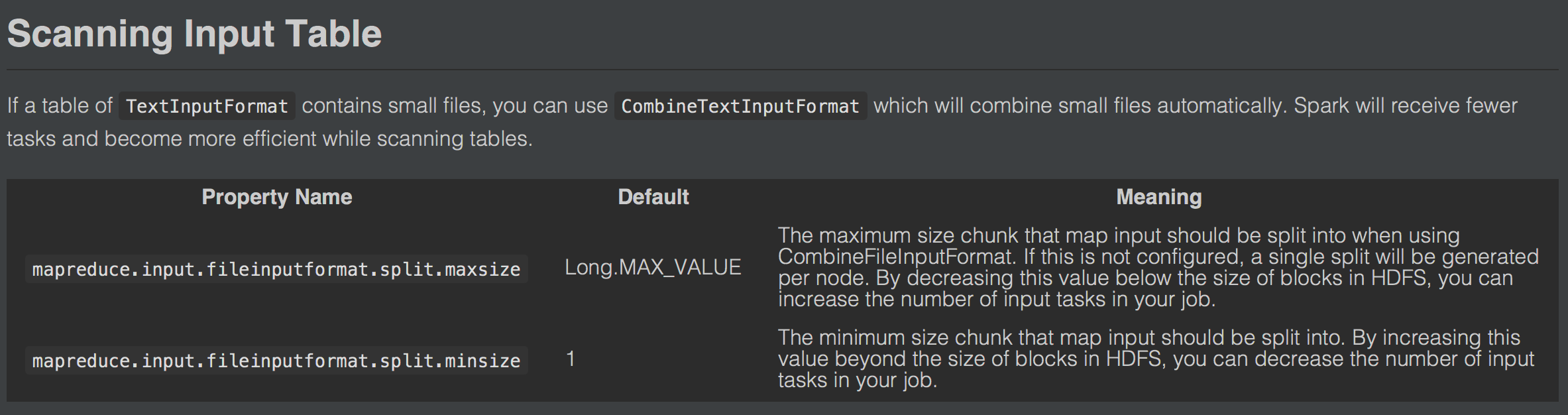
What changes were proposed in this pull request?
We can use
CombineTextInputFormatinstead ofTextInputFormatand set configurations to increase the speed when reading tables.There's no need to add spark configurations, so add it to the Performance Tuning.
This part of the document will be like :
Linked to #23506
How was this patch tested?
Manually tested