[SPARK-26566][PYTHON][SQL] Upgrade Apache Arrow to version 0.12.0 #23657
Conversation
|
Test build #101698 has finished for PR 23657 at commit
|
 srowen
left a comment
srowen
left a comment
There was a problem hiding this comment.
Seems like a good idea to keep Arrow up to date for Spark 3
| import pyarrow | ||
| from distutils.version import LooseVersion | ||
| # As of Arrow 0.12.0, date_as_objects is True by default, see ARROW-3910 | ||
| if LooseVersion(pyarrow.__version__) < LooseVersion("0.12.0") and type(data_type) == DateType: |
There was a problem hiding this comment.
Not a big deal, but does this get called a lot and would it be better to check if Arrow is < 0.12 once and save that?
There was a problem hiding this comment.
Yup, it will be called a lot (but not per record at least but per batch), and I also think it should be called once ideally.
I roughly guess that this has been done in this way so far because I guess we're not sure about the versions in worker side and driver side .. For instance, both versions in both codes can be different as far as I know because we don't have a check for it (correct me if I am mistaken).
Probably we should add a check like we do for Python version check between driver and worker, and have few global checks. Of course, we could do it separately I guess.
There was a problem hiding this comment.
BTW, I was thinking about targeting to upgrade minimum PyArrow version in Spark 3.0.0 since the codes are being complicated for those if-else.
There was a problem hiding this comment.
Yes, these are called per-batch and wouldn't add overhead that would be noticeable. I think these check will be temporary and could be removed once we change the minimum version and as Arrow gets more mature. For now, it's probably best to just make sure these kind of checks are easy to track.
There was a problem hiding this comment.
Probably we should add a check like we do for Python version check between driver and worker, and have few global checks. Of course, we could do it separately I guess.
Yeah, we could do this but it might not really be too big of deal. I think eventually it will be sort of like Pandas versions, if they are close there will probably be no issues. But with major versions might not be completely compatible.
|
Will our Jenkin run Arrow 0.12? |
|
For PyArrow 0.12.0, I don't think so but it will run with Arrow 0.12.0 + PyArrow 0.8.0 combination. I needs to manual upgrade. Currently, IIRC, the version is 0.8.0 to test minimum PyArrow version. I was thinking about bumping up the minimal PyArrow version at Spark 3.0 so that we can reduce such if-else branches, and reduce such overhead. |
|
probably a good idea - arrow moves quickly; 0.10 is kinda "dated" |
Sounds good to me, we might want to double-check on what dependencies 0.12.0 requires though |
|
Test build #101773 has finished for PR 23657 at commit
|
|
retest this please |
|
Test build #101783 has finished for PR 23657 at commit
|
|
Test build #101784 has finished for PR 23657 at commit
|
|
Merged to master. I need to test SPARK-26759 against arrow upgrade as well. |
|
Thanks @HyukjinKwon @felixcheung and @srowen ! |
## What changes were proposed in this pull request? Upgrade Apache Arrow to version 0.12.0. This includes the Java artifacts and fixes to enable usage with pyarrow 0.12.0 Version 0.12.0 includes the following selected fixes/improvements relevant to Spark users: * Safe cast fails from numpy float64 array with nans to integer, ARROW-4258 * Java, Reduce heap usage for variable width vectors, ARROW-4147 * Binary identity cast not implemented, ARROW-4101 * pyarrow open_stream deprecated, use ipc.open_stream, ARROW-4098 * conversion to date object no longer needed, ARROW-3910 * Error reading IPC file with no record batches, ARROW-3894 * Signed to unsigned integer cast yields incorrect results when type sizes are the same, ARROW-3790 * from_pandas gives incorrect results when converting floating point to bool, ARROW-3428 * Import pyarrow fails if scikit-learn is installed from conda (boost-cpp / libboost issue), ARROW-3048 * Java update to official Flatbuffers version 1.9.0, ARROW-3175 complete list [here](https://issues.apache.org/jira/issues/?jql=project%20%3D%20ARROW%20AND%20status%20in%20(Resolved%2C%20Closed)%20AND%20fixVersion%20%3D%200.12.0) PySpark requires the following fixes to work with PyArrow 0.12.0 * Encrypted pyspark worker fails due to ChunkedStream missing closed property * pyarrow now converts dates as objects by default, which causes error because type is assumed datetime64 * ArrowTests fails due to difference in raised error message * pyarrow.open_stream deprecated * tests fail because groupby adds index column with duplicate name ## How was this patch tested? Ran unit tests with pyarrow versions 0.8.0, 0.10.0, 0.11.1, 0.12.0 Closes apache#23657 from BryanCutler/arrow-upgrade-012. Authored-by: Bryan Cutler <cutlerb@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
|
Currently only spark 3.0 is supported, and can support spark 2.4? |
|
nope this change only goes into Spark 3.0 but I think Arrow 0.12.x is still supported in Spark 2.4 too |
|
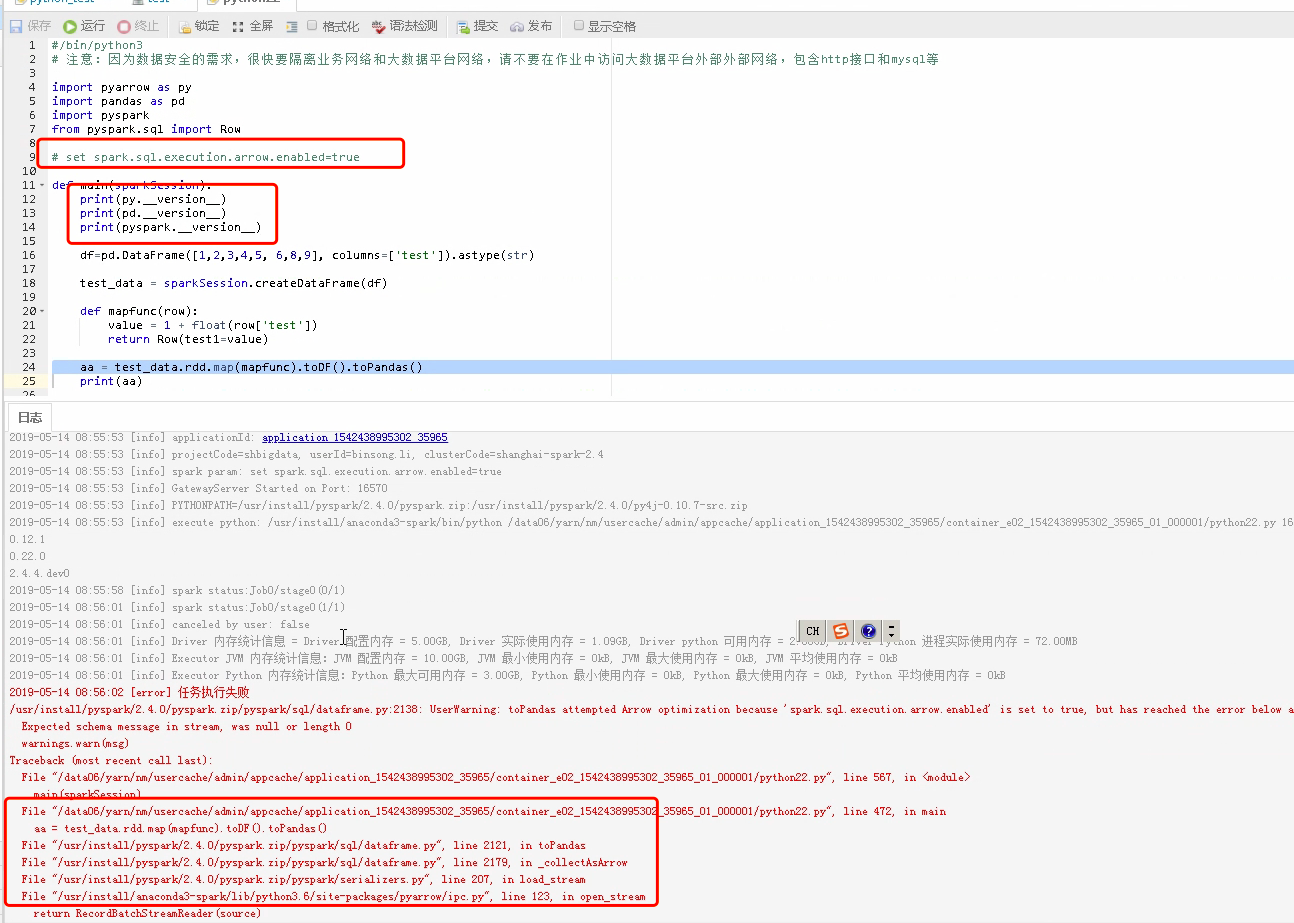
The following error occurred in spark 2.4
Expected schema message in stream, was null or length 0
```
df=pd.DataFrame([1,2,3,4,5, 6,8,9], columns=['test']).astype(str)
test_data = sparkSession.createDataFrame(df)
def mapfunc(row):
value = 1 + float(row['test'])
return Row(test1=value)
aa = test_data.rdd.map(mapfunc).toDF().toPandas()
```
|
{kind=link}
{kind=link}
|
@melin I tried out your example with pyspark branch-2.4, pyarrow 0.12.1 and pandas 0.24.0 and did not reproduce the error. Your pandas version is a bit old, but I don't think that is the problem. Does the error happen in local mode or only in a cluster? |
|
@melin, please file a JIRA or ask it to the mailing list separately. |
|
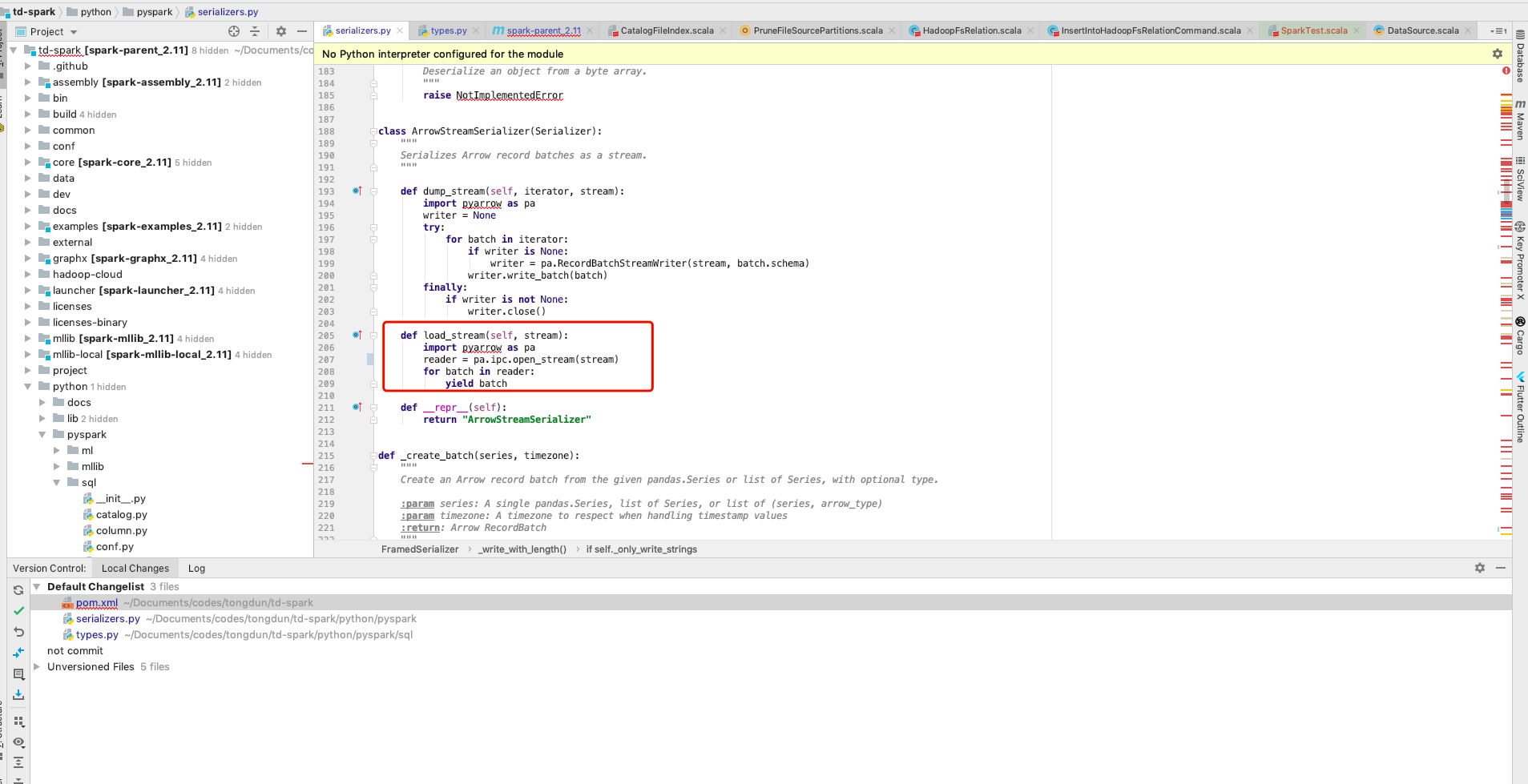
Pyarrow version 0.12.1, arrow jar version 0.10, can run correctly. Pyarrow
version 0.121, arrow jar version 0.12, this exception occurs
Bryan Cutler <notifications@github.com> 于2019年5月15日周三 上午1:02写道:
… @melin <https://github.com/melin> I tried out your example with pyspark
branch-2.4, pyarrow 0.12.1 and pandas 0.24.0 and did not reproduce the
error. Your pandas version is a bit old, but I don't think that is the
problem. Does the error happen in local mode or only in a cluster?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#23657?email_source=notifications&email_token=AAIXXZTW3YGXH7NDSB3BJLTPVLWAXA5CNFSM4GSPNWO2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODVMD35Q#issuecomment-492322294>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAIXXZVPSIBZAYVTTUNYIR3PVLWAXANCNFSM4GSPNWOQ>
.
|
|
In Spark 2.4, the jar should be 0.10. Can we move this topic into the mailing list, @melin? |
Upgrade Apache Arrow to version 0.12.0. This includes the Java artifacts and fixes to enable usage with pyarrow 0.12.0 Version 0.12.0 includes the following selected fixes/improvements relevant to Spark users: * Safe cast fails from numpy float64 array with nans to integer, ARROW-4258 * Java, Reduce heap usage for variable width vectors, ARROW-4147 * Binary identity cast not implemented, ARROW-4101 * pyarrow open_stream deprecated, use ipc.open_stream, ARROW-4098 * conversion to date object no longer needed, ARROW-3910 * Error reading IPC file with no record batches, ARROW-3894 * Signed to unsigned integer cast yields incorrect results when type sizes are the same, ARROW-3790 * from_pandas gives incorrect results when converting floating point to bool, ARROW-3428 * Import pyarrow fails if scikit-learn is installed from conda (boost-cpp / libboost issue), ARROW-3048 * Java update to official Flatbuffers version 1.9.0, ARROW-3175 complete list [here](https://issues.apache.org/jira/issues/?jql=project%20%3D%20ARROW%20AND%20status%20in%20(Resolved%2C%20Closed)%20AND%20fixVersion%20%3D%200.12.0) PySpark requires the following fixes to work with PyArrow 0.12.0 * Encrypted pyspark worker fails due to ChunkedStream missing closed property * pyarrow now converts dates as objects by default, which causes error because type is assumed datetime64 * ArrowTests fails due to difference in raised error message * pyarrow.open_stream deprecated * tests fail because groupby adds index column with duplicate name Ran unit tests with pyarrow versions 0.8.0, 0.10.0, 0.11.1, 0.12.0 Closes apache#23657 from BryanCutler/arrow-upgrade-012. Authored-by: Bryan Cutler <cutlerb@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
Upgrade Apache Arrow to version 0.12.0. This includes the Java artifacts and fixes to enable usage with pyarrow 0.12.0 Version 0.12.0 includes the following selected fixes/improvements relevant to Spark users: * Safe cast fails from numpy float64 array with nans to integer, ARROW-4258 * Java, Reduce heap usage for variable width vectors, ARROW-4147 * Binary identity cast not implemented, ARROW-4101 * pyarrow open_stream deprecated, use ipc.open_stream, ARROW-4098 * conversion to date object no longer needed, ARROW-3910 * Error reading IPC file with no record batches, ARROW-3894 * Signed to unsigned integer cast yields incorrect results when type sizes are the same, ARROW-3790 * from_pandas gives incorrect results when converting floating point to bool, ARROW-3428 * Import pyarrow fails if scikit-learn is installed from conda (boost-cpp / libboost issue), ARROW-3048 * Java update to official Flatbuffers version 1.9.0, ARROW-3175 complete list [here](https://issues.apache.org/jira/issues/?jql=project%20%3D%20ARROW%20AND%20status%20in%20(Resolved%2C%20Closed)%20AND%20fixVersion%20%3D%200.12.0) PySpark requires the following fixes to work with PyArrow 0.12.0 * Encrypted pyspark worker fails due to ChunkedStream missing closed property * pyarrow now converts dates as objects by default, which causes error because type is assumed datetime64 * ArrowTests fails due to difference in raised error message * pyarrow.open_stream deprecated * tests fail because groupby adds index column with duplicate name Ran unit tests with pyarrow versions 0.8.0, 0.10.0, 0.11.1, 0.12.0 Closes apache#23657 from BryanCutler/arrow-upgrade-012. Authored-by: Bryan Cutler <cutlerb@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
What changes were proposed in this pull request?
Upgrade Apache Arrow to version 0.12.0. This includes the Java artifacts and fixes to enable usage with pyarrow 0.12.0
Version 0.12.0 includes the following selected fixes/improvements relevant to Spark users:
complete list here
PySpark requires the following fixes to work with PyArrow 0.12.0
How was this patch tested?
Ran unit tests with pyarrow versions 0.8.0, 0.10.0, 0.11.1, 0.12.0