[SPARK-29225][SQL] Change Spark SQL DESC FORMATTED format same with Hive#25917
[SPARK-29225][SQL] Change Spark SQL DESC FORMATTED format same with Hive#25917AngersZhuuuu wants to merge 6 commits intoapache:masterfrom
DESC FORMATTED format same with Hive#25917Conversation
 HyukjinKwon
left a comment
HyukjinKwon
left a comment
There was a problem hiding this comment.
@AngersZhuuuu I think it affects user-facing output. Please describe before/after outputs
Add photo about before/after result since the length of result formatted string is too long. |
DESC FORMATTED TABLE_NAME format same with HiveDESC FORMATTED format same with Hive
|
ok to test |
|
Test build #111786 has finished for PR 25917 at commit
|
|
Test build #111789 has finished for PR 25917 at commit
|
|
The failures looks relevant to this PR, @AngersZhuuuu . |
Got it, UT need change. |
|
Test build #111799 has finished for PR 25917 at commit
|
|
@dongjoon-hyun |
|
Retest this please. |
| if (partColNames.isEmpty) { | ||
| schema | ||
| } else { | ||
| StructType(schema.filter(col => !partColNames.contains(col.name))) |
There was a problem hiding this comment.
Although this function is used for the data from metadata only for now, this is a usual suspect for the case-sensitive failures.
We don't know who will use this function later. And, since partColNames is Seq[String], it's not safe. We had better consider a case-sensitivity. Please refer SchemaUtils.normalizePartitionSpec and SchemaUtils.checkColumnNameDuplication. You can use resolver to be robust.
There was a problem hiding this comment.
@dongjoon-hyun
Updated, current way is robust enough. Since here is just show table desc. use resolver to check column name equal.
By the way : PartitionUtils.normalizePartitionSpec
|
Test build #111810 has finished for PR 25917 at commit
|
|
Test build #111812 has finished for PR 25917 at commit
|
|
Test build #111816 has finished for PR 25917 at commit
|
|
Test build #111817 has finished for PR 25917 at commit
|
|
@dongjoon-hyun @HyukjinKwon Any more suggestion for this problem? |
|
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. |
What changes were proposed in this pull request?
As I have mentioned in SPARK-29225
Spark SQL
DESC FORMATTED table_nameformat have so many different point form hive's format.Since some JDBC query interaction platform like
HUEuse Hive format to parse information form the query result.Such as column information:
Hue use
DESC FORMATTED tablequery to get result and parse column information by it's result format.Spark SQL show different format, it cause problem when show result.
Why are the changes needed?
For better interaction with JDBC query platform like Hue.
Does this PR introduce any user-facing change?
Create table like below:
Then call
DESC FORMATTED order_partition.Origin Format:
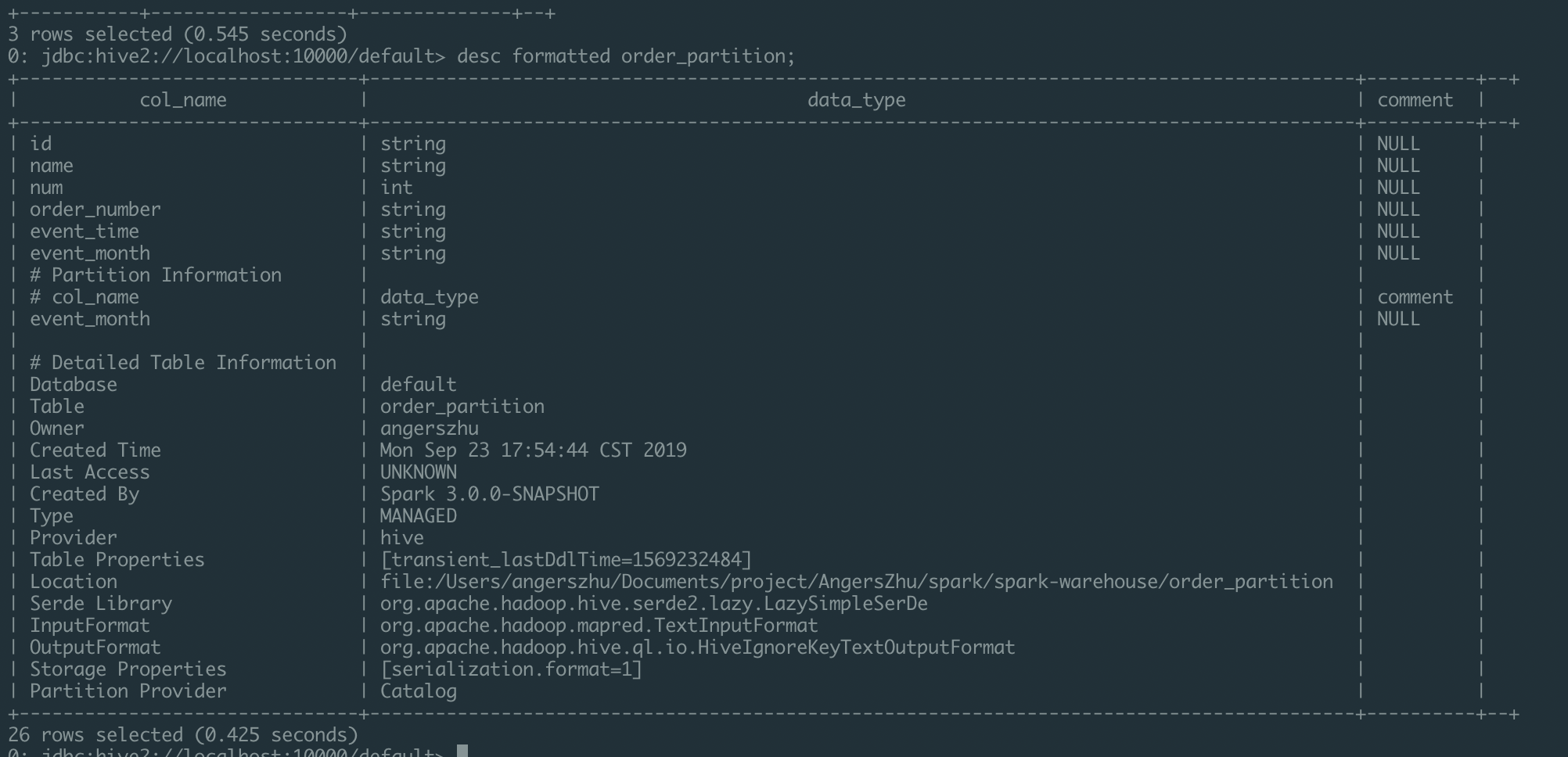
Current format:
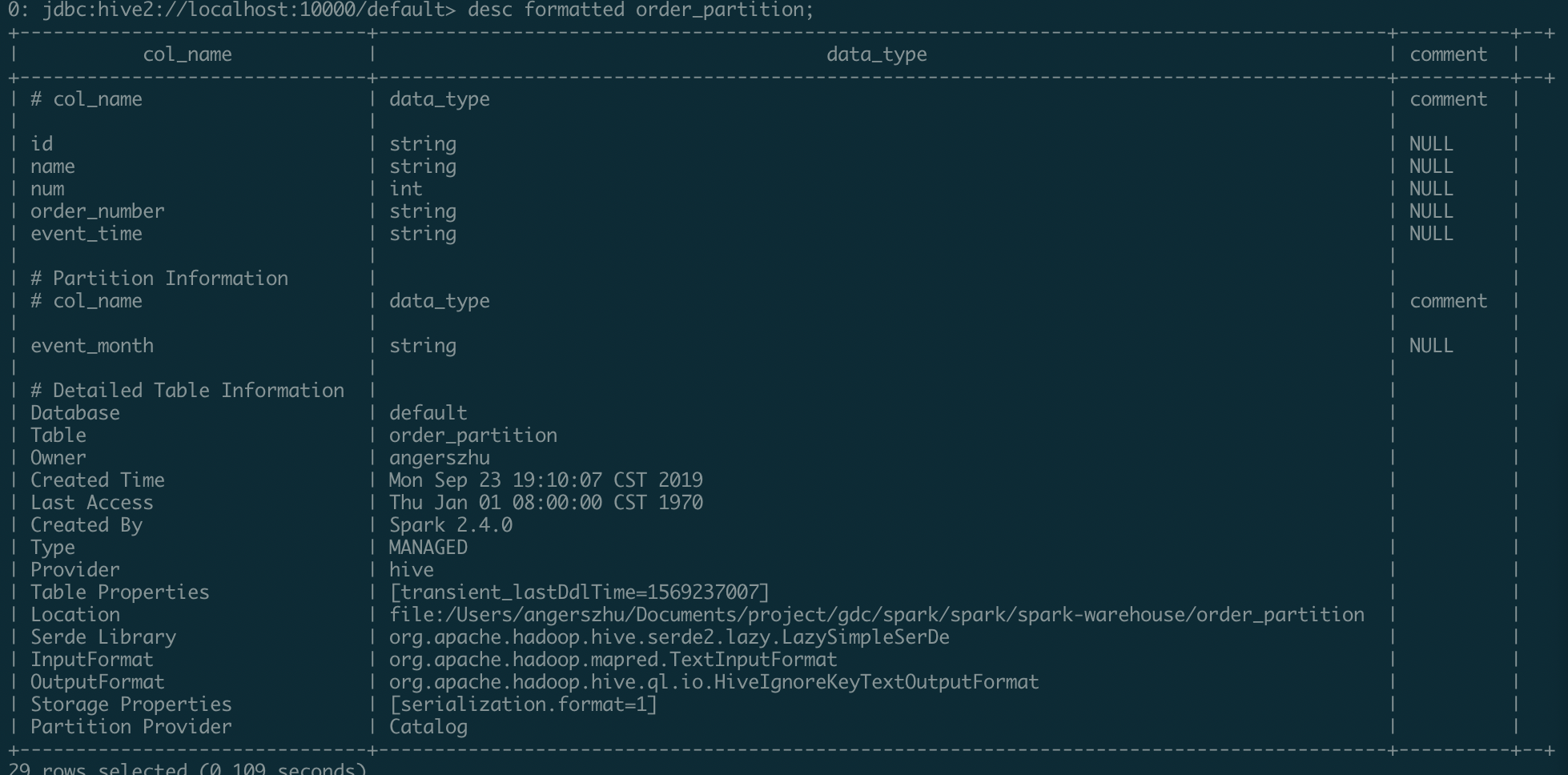
Changes
When call
DESC FORMATTED table_name#Partition information#Partition informationHow was this patch tested?
MT