[Spark-25993][SQL][TEST]Add test cases for CREATE EXTERNAL TABLE with subdirectories #27123
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
## What changes were proposed in this pull request?
I believe the log message: `Committer $committerClass is not a ParquetOutputCommitter and cannot create job summaries. Set Parquet option ${ParquetOutputFormat.JOB_SUMMARY_LEVEL} to NONE.` is at odds with the `if` statement that logs the warning. Despite the instructions in the warning, users still encounter the warning if `JOB_SUMMARY_LEVEL` is already set to `NONE`.
This pull request introduces a change to skip logging the warning if `JOB_SUMMARY_LEVEL` is set to `NONE`.
## How was this patch tested?
I built to make sure everything still compiled and I ran the existing test suite. I didn't feel it was worth the overhead to add a test to make sure a log message does not get logged, but if reviewers feel differently, I can add one.
Closes apache#24808 from jmsanders/master.
Authored-by: Jordan Sanders <jmsanders@users.noreply.github.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…e when converted to local relation ## What changes were proposed in this pull request? When using `from_avro` to deserialize avro data to catalyst StructType format, if `ConvertToLocalRelation` is applied at the time, `from_avro` produces only the last value (overriding previous values). The cause is `AvroDeserializer` reuses output row for StructType. Normally, it should be fine in Spark SQL. But `ConvertToLocalRelation` just uses `InterpretedProjection` to project local rows. `InterpretedProjection` creates new row for each output thro, it includes the same nested row object from `AvroDeserializer`. By the end, converted local relation has only last value. This is to backport the fix to branch 2.4 and uses `InterpretedMutableProjection` in `ConvertToLocalRelation` and call `copy()` on output rows. ## How was this patch tested? Added test. Closes apache#24822 from viirya/SPARK-27798-2.4. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…t with groupId ## What changes were proposed in this pull request? Usage: DirectKafkaWordCount <brokers> <topics> -- <brokers> is a list of one or more Kafka brokers <groupId> is a consumer group name to consume from topics <topics> is a list of one or more kafka topics to consume from ## How was this patch tested? N/A. Please review https://spark.apache.org/contributing.html before opening a pull request. Closes apache#24819 from cnZach/minor_DirectKafkaWordCount_UsageWithGroupId. Authored-by: Yuexin Zhang <zach.yx.zhang@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
… incorrect
## What changes were proposed in this pull request?
For caseWhen Object canonicalized is not handled
for e.g let's consider below CaseWhen Object
val attrRef = AttributeReference("ACCESS_CHECK", StringType)()
val caseWhenObj1 = CaseWhen(Seq((attrRef, Literal("A"))))
caseWhenObj1.canonicalized **ouput** is as below
CASE WHEN ACCESS_CHECK#0 THEN A END (**Before Fix)**
**After Fix** : CASE WHEN none#0 THEN A END
So when there will be aliasref like below statements, semantic equals will fail. Sematic equals returns true if the canonicalized form of both the expressions are same.
val attrRef = AttributeReference("ACCESS_CHECK", StringType)()
val aliasAttrRef = attrRef.withName("access_check")
val caseWhenObj1 = CaseWhen(Seq((attrRef, Literal("A"))))
val caseWhenObj2 = CaseWhen(Seq((aliasAttrRef, Literal("A"))))
**assert(caseWhenObj2.semanticEquals(caseWhenObj1.semanticEquals) fails**
**caseWhenObj1.canonicalized**
Before Fix:CASE WHEN ACCESS_CHECK#0 THEN A END
After Fix: CASE WHEN none#0 THEN A END
**caseWhenObj2.canonicalized**
Before Fix:CASE WHEN access_check#0 THEN A END
After Fix: CASE WHEN none#0 THEN A END
## How was this patch tested?
Added UT
Closes apache#24836 from sandeep-katta/spark2.4.
Authored-by: sandeep katta <sandeep.katta2007@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
## What changes were proposed in this pull request? Just found the doctest on `over` function of `Column` is commented out. The window spec is also not for the window function used there. We should either remove the doctest, or improve it. Because other functions of `Column` have doctest generally, so this PR tries to improve it. ## How was this patch tested? Added doctest. Closes apache#24854 from viirya/column-test-minor. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit ddf4a50) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…ly in the saveAsHadoopDataset function ## What changes were proposed in this pull request? (Continuation of apache#19118 ; see for details) ## How was this patch tested? Existing tests. Closes apache#24863 from srowen/SPARK-21882.2. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> (cherry picked from commit b508eab) Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request? Adding spark.checkpoint.compress configuration parameter to the documentation  ## How was this patch tested? Checked locally for jeykyll html docs. Also validated the html for any issues. Closes apache#24883 from sandeepvja/SPARK-24898. Authored-by: Mellacheruvu Sandeep <mellacheruvu.sandeep@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit b7b4452) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
## What changes were proposed in this pull request? When using `DROPMALFORMED` mode, corrupted records aren't dropped if malformed columns aren't read. This behavior is due to CSV parser column pruning. Current doc of `DROPMALFORMED` doesn't mention the effect of column pruning. Users will be confused by the fact that `DROPMALFORMED` mode doesn't work as expected. Column pruning also affects other modes. This is a doc improvement to add a note to doc of `mode` to explain it. ## How was this patch tested? N/A. This is just doc change. Closes apache#24894 from viirya/SPARK-28058. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit b7bdc31) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request? The word2vec logic fails if a corpora has a word with count > 1e9. We should be able to handle very large counts generally better here by using longs to count. This takes over apache#24814 ## How was this patch tested? Existing tests. Closes apache#24893 from srowen/SPARK-28081. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> (cherry picked from commit e96dd82) Signed-off-by: Sean Owen <sean.owen@databricks.com>
…thread safe This is a Spark 2.4.x backport of apache#24085. Original description follows below: ## What changes were proposed in this pull request? Make ScalaReflection subtype checking thread safe by adding a lock. There is a thread safety bug in the <:< operator in all versions of scala (scala/bug#10766). ## How was this patch tested? Existing tests and a new one for the new subtype checking function. Closes apache#24913 from JoshRosen/joshrosen/SPARK-26555-branch-2.4-backport. Authored-by: mwlon <mloncaric@hmc.edu> Signed-off-by: Josh Rosen <rosenville@gmail.com>
## What changes were proposed in this pull request? The Python documentation incorrectly says that `variance()` acts as `var_pop` whereas it acts like `var_samp` here: https://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.functions.variance It was not the case in Spark 1.6 doc but it is in Spark 2.0 doc: https://spark.apache.org/docs/1.6.0/api/java/org/apache/spark/sql/functions.html https://spark.apache.org/docs/2.0.0/api/java/org/apache/spark/sql/functions.html The Scala documentation is correct: https://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/functions.html#variance-org.apache.spark.sql.Column- The alias is set on this line: https://github.com/apache/spark/blob/v2.4.3/sql/core/src/main/scala/org/apache/spark/sql/functions.scala#L786 ## How was this patch tested? Using variance() in pyspark 2.4.3 returns: ``` >>> spark.createDataFrame([(1, ), (2, ), (3, )], "a: int").select(variance("a")).show() +-----------+ |var_samp(a)| +-----------+ | 1.0| +-----------+ ``` Closes apache#24895 from tools4origins/patch-1. Authored-by: tools4origins <tools4origins@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 25c5d57) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…rameter order issue ## What changes were proposed in this pull request? This pr backport apache#24902 and apache#24911 to branch-2.4. ## How was this patch tested? unit tests Closes apache#24907 from wangyum/SPARK-28093-branch-2.4. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…decimals not fitting in long This is a Spark 2.4.x backport of apache#23022. Original description follows below: ## What changes were proposed in this pull request? Fix Decimal `toScalaBigInt` and `toJavaBigInteger` used to only work for decimals not fitting long. ## How was this patch tested? Added test to DecimalSuite. Closes apache#24928 from JoshRosen/joshrosen/SPARK-26038-backport. Authored-by: Juliusz Sompolski <julek@databricks.com> Signed-off-by: Josh Rosen <rosenville@gmail.com>
…iodicCheckpointer
## What changes were proposed in this pull request?
remove the oldest checkpointed file only if next checkpoint exists.
I think this patch needs back-porting.
## How was this patch tested?
existing test
local check in spark-shell with following suite:
```
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.ml.classification.GBTClassifier
case class Row(features: org.apache.spark.ml.linalg.Vector, label: Int)
sc.setCheckpointDir("/checkpoints")
val trainingData = sc.parallelize(1 to 2426874, 256).map(x => Row(Vectors.dense(x, x + 1, x * 2 % 10), if (x % 5 == 0) 1 else 0)).toDF
val classifier = new GBTClassifier()
.setLabelCol("label")
.setFeaturesCol("features")
.setProbabilityCol("probability")
.setMaxIter(100)
.setMaxDepth(10)
.setCheckpointInterval(2)
classifier.fit(trainingData)
```
Closes apache#24870 from zhengruifeng/ck_update.
Authored-by: zhengruifeng <ruifengz@foxmail.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
(cherry picked from commit 6064368)
Signed-off-by: Sean Owen <sean.owen@databricks.com>
…ction parameter order issue" ## What changes were proposed in this pull request? This reverts commit 4990be9. The parameter orders might be different in different vendors. We can change it in 3.x to make it more consistent with the other vendors. However, it could break the existing customers' workloads if they already use `trim`. ## How was this patch tested? N/A Closes apache#24943 from wangyum/SPARK-28093-REVERT-2.4. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
if the input dataset is alreadly cached, then we do not need to cache the internal rdd (like kmeans) existing test Closes apache#24919 from zhengruifeng/gmm_fix_double_caching. Authored-by: zhengruifeng <ruifengz@foxmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> (cherry picked from commit c83b3dd) Signed-off-by: Sean Owen <sean.owen@databricks.com>
…n` to prevent StackOverflowError … prevent `StackOverflowError ` ShuffleMapTask's partition field is a FilePartition and FilePartition's 'files' field is a Stream$cons which is essentially a linked list. It is therefore serialized recursively. If the number of files in each partition is, say, 10000 files, recursing into a linked list of length 10000 overflows the stack The problem is only in Bucketed partitions. The corresponding implementation for non Bucketed partitions uses a StreamBuffer. The proposed change applies the same for Bucketed partitions. Existing unit tests. Added new unit test. The unit test fails without the patch. Manual testing on dataset used to reproduce the problem. Closes apache#24957 from parthchandra/branch-2.4. Authored-by: Parth Chandra <parthc@apple.com> Signed-off-by: DB Tsai <d_tsai@apple.com>
## What changes were proposed in this pull request? updated the usage message in sbin/start-slave.sh. <masterURL> argument moved to first ## How was this patch tested? tested locally with Starting master starting slave with (./start-slave.sh spark://<IP>:<PORT> -c 1 and opening spark shell with ./spark-shell --master spark://<IP>:<PORT> Closes apache#24974 from shivusondur/jira28164. Authored-by: shivusondur <shivusondur@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> (cherry picked from commit bd232b9) Signed-off-by: Sean Owen <sean.owen@databricks.com>
…acklisted entries ## What changes were proposed in this pull request? At Spark 2.4.0/2.3.2/2.2.3, [SPARK-24948](https://issues.apache.org/jira/browse/SPARK-24948) delegated access permission checks to the file system, and maintains a blacklist for all event log files failed once at reading. The blacklisted log files are released back after `CLEAN_INTERVAL_S` seconds. However, the released files whose sizes don't changes are ignored forever due to `info.fileSize < entry.getLen()` condition (previously [here](apache@3c96937#diff-a7befb99e7bd7e3ab5c46c2568aa5b3eR454) and now at [shouldReloadLog](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/deploy/history/FsHistoryProvider.scala#L571)) which returns `false` always when the size is the same with the existing value in `KVStore`. This is recovered only via SHS restart. This PR aims to remove the existing entry from `KVStore` when it goes to the blacklist. ## How was this patch tested? Pass the Jenkins with the updated test case. Closes apache#24975 from dongjoon-hyun/SPARK-28157-2.4. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: DB Tsai <d_tsai@apple.com>
…checked exception missed This is very like apache#23590 . `ByteBuffer.allocate` may throw `OutOfMemoryError` when the response is large but no enough memory is available. However, when this happens, `TransportClient.sendRpcSync` will just hang forever if the timeout set to unlimited. This PR catches `Throwable` and uses the error to complete `SettableFuture`. I tested in my IDE by setting the value of size to -1 to verify the result. Without this patch, it won't be finished until timeout (May hang forever if timeout set to MAX_INT), or the expected `IllegalArgumentException` will be caught. ```java Override public void onSuccess(ByteBuffer response) { try { int size = response.remaining(); ByteBuffer copy = ByteBuffer.allocate(size); // set size to -1 in runtime when debug copy.put(response); // flip "copy" to make it readable copy.flip(); result.set(copy); } catch (Throwable t) { result.setException(t); } } ``` Closes apache#24964 from LantaoJin/SPARK-28160. Lead-authored-by: LantaoJin <jinlantao@gmail.com> Co-authored-by: lajin <lajin@ebay.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> (cherry picked from commit 0e42100) Signed-off-by: Sean Owen <sean.owen@databricks.com>
## What changes were proposed in this pull request? The documentation in `linalg.py` is not consistent. This PR uniforms the documentation. ## How was this patch tested? NA Closes apache#25011 from mgaido91/SPARK-28170. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 048224c) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
## What changes were proposed in this pull request? `requestHeaderSize` is added in apache#23090 and applies to Spark + History server UI as well. Without debug log it's hard to find out on which side what configuration is used. In this PR I've added a log message which prints out the value. ## How was this patch tested? Manually checked log files. Closes apache#25045 from gaborgsomogyi/SPARK-26118. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 0b6c2c2) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
There is the following code in [TransportClientFactory#createClient](https://github.com/apache/spark/blob/master/common/network-common/src/main/java/org/apache/spark/network/client/TransportClientFactory.java#L150) ``` int clientIndex = rand.nextInt(numConnectionsPerPeer); TransportClient cachedClient = clientPool.clients[clientIndex]; ``` which choose a client from its pool randomly. If we are unlucky we might not get the max number of connections out, but less than that. To prove that I've tried out the following test: ```java Test public void testRandom() { Random rand = new Random(); Set<Integer> clients = Collections.synchronizedSet(new HashSet<>()); long iterCounter = 0; while (true) { iterCounter++; int maxConnections = 4; clients.clear(); for (int i = 0; i < maxConnections * 10; i++) { int clientIndex = rand.nextInt(maxConnections); clients.add(clientIndex); } if (clients.size() != maxConnections) { System.err.println("Unexpected clients size (iterCounter=" + iterCounter + "): " + clients.size() + ", maxConnections: " + maxConnections); } if (iterCounter % 100000 == 0) { System.out.println("IterCounter: " + iterCounter); } } } ``` Result: ``` Unexpected clients size (iterCounter=22388): 3, maxConnections: 4 Unexpected clients size (iterCounter=36244): 3, maxConnections: 4 Unexpected clients size (iterCounter=85798): 3, maxConnections: 4 IterCounter: 100000 Unexpected clients size (iterCounter=97108): 3, maxConnections: 4 Unexpected clients size (iterCounter=119121): 3, maxConnections: 4 Unexpected clients size (iterCounter=129948): 3, maxConnections: 4 Unexpected clients size (iterCounter=173736): 3, maxConnections: 4 Unexpected clients size (iterCounter=178138): 3, maxConnections: 4 Unexpected clients size (iterCounter=195108): 3, maxConnections: 4 IterCounter: 200000 Unexpected clients size (iterCounter=209006): 3, maxConnections: 4 Unexpected clients size (iterCounter=217105): 3, maxConnections: 4 Unexpected clients size (iterCounter=222456): 3, maxConnections: 4 Unexpected clients size (iterCounter=226899): 3, maxConnections: 4 Unexpected clients size (iterCounter=229101): 3, maxConnections: 4 Unexpected clients size (iterCounter=253549): 3, maxConnections: 4 Unexpected clients size (iterCounter=277550): 3, maxConnections: 4 Unexpected clients size (iterCounter=289637): 3, maxConnections: 4 ... ``` In this PR I've adapted the test code not to have this flakyness. Additional (not committed test) + existing unit tests in a loop. Closes apache#25075 from gaborgsomogyi/SPARK-28261. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit e11a558) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
… before parsing The sub-second part of the interval should be padded before parsing. Currently, Spark gives a correct value only when there is 9 digits below `.`. ``` spark-sql> select interval '0 0:0:0.123456789' day to second; interval 123 milliseconds 456 microseconds spark-sql> select interval '0 0:0:0.12345678' day to second; interval 12 milliseconds 345 microseconds spark-sql> select interval '0 0:0:0.1234' day to second; interval 1 microseconds ``` Pass the Jenkins with the fixed test cases. Closes apache#25079 from dongjoon-hyun/SPARK-28308. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit a5ff922) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…kLauncher on Windows ## What changes were proposed in this pull request? When using SparkLauncher to submit applications **concurrently** with multiple threads under **Windows**, some apps would show that "The process cannot access the file because it is being used by another process" and remains in LOST state at the end. The issue can be reproduced by this [demo](https://issues.apache.org/jira/secure/attachment/12973920/Main.scala). After digging into the code, I find that, Windows cmd `%RANDOM%` would return the same number if we call it instantly(e.g. < 500ms) after last call. As a result, SparkLauncher would get same output file(spark-class-launcher-output-%RANDOM%.txt) for apps. Then, the following app would hit the issue when it tries to write the same file which has already been opened for writing by another app. We should make sure to generate unique output file for SparkLauncher on Windows to avoid this issue. ## How was this patch tested? Tested manually on Windows. Closes apache#25076 from Ngone51/SPARK-28302. Authored-by: wuyi <ngone_5451@163.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 925f620) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…sync commit `DirectKafkaStreamSuite.offset recovery from kafka` commits offsets to Kafka with `Consumer.commitAsync` API (and then reads it back). Since this API is asynchronous it may send notifications late(or not at all). The actual test makes the assumption if the data sent and collected then the offset must be committed as well. This is not true. In this PR I've made the following modifications: * Wait for async offset commit before context stopped * Added commit succeed log to see whether it arrived at all * Using `ConcurrentHashMap` for committed offsets because 2 threads are using the variable (`JobGenerator` and `ScalaTest...`) Existing unit test in a loop + jenkins runs. Closes apache#25100 from gaborgsomogyi/SPARK-28335. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 579edf4) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
… yyyy and yyyy-[m]m formats
Fix `stringToDate()` for the formats `yyyy` and `yyyy-[m]m` that assumes there are no additional chars after the last components `yyyy` and `[m]m`. In the PR, I propose to check that entire input was consumed for the formats.
After the fix, the input `1999 08 01` will be invalid because it matches to the pattern `yyyy` but the strings contains additional chars ` 08 01`.
Since Spark 1.6.3 ~ 2.4.3, the behavior is the same.
```
spark-sql> SELECT CAST('1999 08 01' AS DATE);
1999-01-01
```
This PR makes it return NULL like Hive.
```
spark-sql> SELECT CAST('1999 08 01' AS DATE);
NULL
```
Added new checks to `DateTimeUtilsSuite` for the `1999 08 01` and `1999 08` inputs.
Closes apache#25097 from MaxGekk/spark-28015-invalid-date-format.
Authored-by: Maxim Gekk <maxim.gekk@databricks.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…ile appender - size-based rolling compressed
## What changes were proposed in this pull request?
`SizeBasedRollingPolicy.shouldRollover` returns false when the size is equal to `rolloverSizeBytes`.
```scala
/** Should rollover if the next set of bytes is going to exceed the size limit */
def shouldRollover(bytesToBeWritten: Long): Boolean = {
logDebug(s"$bytesToBeWritten + $bytesWrittenSinceRollover > $rolloverSizeBytes")
bytesToBeWritten + bytesWrittenSinceRollover > rolloverSizeBytes
}
```
- https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107553/testReport/org.apache.spark.util/FileAppenderSuite/rolling_file_appender___size_based_rolling__compressed_/
```
org.scalatest.exceptions.TestFailedException: 1000 was not less than 1000
```
## How was this patch tested?
Pass the Jenkins with the updated test.
Closes apache#25125 from dongjoon-hyun/SPARK-28357.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
(cherry picked from commit 1c29212)
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…lass name A code gen test in WholeStageCodeGenSuite was flaky because it used the codegen metrics class to test if the generated code for equivalent plans was identical under a particular flag. This patch switches the test to compare the generated code directly. N/A Closes apache#25131 from gatorsmile/WholeStageCodegenSuite. Authored-by: gatorsmile <gatorsmile@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 60b89cf) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
Parquet may call the filter with a null value to check whether nulls are accepted. While it seems Spark avoids that path in Parquet with 1.10, in 1.11 that causes Spark unit tests to fail. Tested with Parquet 1.11 (and new unit test). Closes apache#25140 from vanzin/SPARK-28371. Authored-by: Marcelo Vanzin <vanzin@cloudera.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 7f9da2b) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…ve table bucketing info ### What changes were proposed in this pull request? This patch adds Hive provider into table metadata in `HiveExternalCatalog.alterTableStats`. When we call `HiveClient.alterTable`, `alterTable` will erase if it can not find hive provider in given table metadata. Rename table also has this issue. ### Why are the changes needed? Because running `ANALYZE TABLE` on a Hive table, if the table has bucketing info, will erase existing bucket info. ### Does this PR introduce any user-facing change? Yes. After this PR, running `ANALYZE TABLE` on Hive table, won't erase existing bucketing info. ### How was this patch tested? Unit test. Closes apache#26685 from viirya/fix-hive-bucket. Lead-authored-by: Liang-Chi Hsieh <viirya@gmail.com> Co-authored-by: Liang-Chi Hsieh <liangchi@uber.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 85cb388) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request?
Do not cast `NaN` to an `Integer`, `Long`, `Short` or `Byte`. This is because casting `NaN` to those types results in a `0` which erroneously replaces `0`s while only `NaN`s should be replaced.
### Why are the changes needed?
This Scala code snippet:
```
import scala.math;
println(Double.NaN.toLong)
```
returns `0` which is problematic as if you run the following Spark code, `0`s get replaced as well:
```
>>> df = spark.createDataFrame([(1.0, 0), (0.0, 3), (float('nan'), 0)], ("index", "value"))
>>> df.show()
+-----+-----+
|index|value|
+-----+-----+
| 1.0| 0|
| 0.0| 3|
| NaN| 0|
+-----+-----+
>>> df.replace(float('nan'), 2).show()
+-----+-----+
|index|value|
+-----+-----+
| 1.0| 2|
| 0.0| 3|
| 2.0| 2|
+-----+-----+
```
### Does this PR introduce any user-facing change?
Yes, after the PR, running the same above code snippet returns the correct expected results:
```
>>> df = spark.createDataFrame([(1.0, 0), (0.0, 3), (float('nan'), 0)], ("index", "value"))
>>> df.show()
+-----+-----+
|index|value|
+-----+-----+
| 1.0| 0|
| 0.0| 3|
| NaN| 0|
+-----+-----+
>>> df.replace(float('nan'), 2).show()
+-----+-----+
|index|value|
+-----+-----+
| 1.0| 0|
| 0.0| 3|
| 2.0| 0|
+-----+-----+
```
### How was this patch tested?
Added unit tests to verify replacing `NaN` only affects columns of type `Float` and `Double`
Closes apache#26749 from johnhany97/SPARK-30082-2.4.
Authored-by: John Ayad <johnhany97@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…cessful auth The new auth code was missing this bit, so it was not possible to know which app a client belonged to when auth was on. I also refactored the SASL test that checks for this so it also checks the new protocol (test failed before the fix, passes now). Closes apache#26764 from vanzin/SPARK-30129-2.4. Authored-by: Marcelo Vanzin <vanzin@cloudera.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…terations are large
### What changes were proposed in this pull request?
This patch adds normalization to word vectors when fitting dataset in Word2Vec.
### Why are the changes needed?
Running Word2Vec on some datasets, when numIterations is large, can produce infinity word vectors.
### Does this PR introduce any user-facing change?
Yes. After this patch, Word2Vec won't produce infinity word vectors.
### How was this patch tested?
Manually. This issue is not always reproducible on any dataset. The dataset known to reproduce it is too large (925M) to upload.
```scala
case class Sentences(name: String, words: Array[String])
val dataset = spark.read
.option("header", "true").option("sep", "\t")
.option("quote", "").option("nullValue", "\\N")
.csv("/tmp/title.akas.tsv")
.filter("region = 'US' or language = 'en'")
.select("title")
.as[String]
.map(s => Sentences(s, s.split(' ')))
.persist()
println("Training model...")
val word2Vec = new Word2Vec()
.setInputCol("words")
.setOutputCol("vector")
.setVectorSize(64)
.setWindowSize(4)
.setNumPartitions(50)
.setMinCount(5)
.setMaxIter(30)
val model = word2Vec.fit(dataset)
model.getVectors.show()
```
Before:
```
Training model...
+-------------+--------------------+
| word| vector|
+-------------+--------------------+
| Unspoken|[-Infinity,-Infin...|
| Talent|[-Infinity,Infini...|
| Hourglass|[2.02805806500023...|
|Nickelodeon's|[-4.2918617120906...|
| Priests|[-1.3570403355926...|
| Religion:|[-6.7049072282803...|
| Bu|[5.05591774315586...|
| Totoro:|[-1.0539840178632...|
| Trouble,|[-3.5363592836003...|
| Hatter|[4.90413981352826...|
| '79|[7.50436471285412...|
| Vile|[-2.9147142985312...|
| 9/11|[-Infinity,Infini...|
| Santino|[1.30005911270850...|
| Motives|[-1.2538958306253...|
| '13|[-4.5040152427657...|
| Fierce|[Infinity,Infinit...|
| Stover|[-2.6326895394029...|
| 'It|[1.66574533864436...|
| Butts|[Infinity,Infinit...|
+-------------+--------------------+
only showing top 20 rows
```
After:
```
Training model...
+-------------+--------------------+
| word| vector|
+-------------+--------------------+
| Unspoken|[-0.0454501919448...|
| Talent|[-0.2657704949378...|
| Hourglass|[-0.1399687677621...|
|Nickelodeon's|[-0.1767119318246...|
| Priests|[-0.0047509293071...|
| Religion:|[-0.0411605164408...|
| Bu|[0.11837736517190...|
| Totoro:|[0.05258282646536...|
| Trouble,|[0.09482011198997...|
| Hatter|[0.06040831282734...|
| '79|[0.04783720895648...|
| Vile|[-0.0017210749210...|
| 9/11|[-0.0713915303349...|
| Santino|[-0.0412711687386...|
| Motives|[-0.0492418706417...|
| '13|[-0.0073119504377...|
| Fierce|[-0.0565455369651...|
| Stover|[0.06938160210847...|
| 'It|[0.01117012929171...|
| Butts|[0.05374567210674...|
+-------------+--------------------+
only showing top 20 rows
```
Closes apache#26722 from viirya/SPARK-24666-2.
Lead-authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Co-authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <liangchi@uber.com>
(cherry picked from commit 755d889)
Signed-off-by: Liang-Chi Hsieh <liangchi@uber.com>
This PR aims to use [Google Maven mirror](https://cloudplatform.googleblog.com/2015/11/faster-builds-for-Java-developers-with-Maven-Central-mirror.html) in `GitHub Action` jobs to improve the stability. ```xml <settings> <mirrors> <mirror> <id>google-maven-central</id> <name>GCS Maven Central mirror</name> <url>https://maven-central.storage-download.googleapis.com/repos/central/data/</url> <mirrorOf>central</mirrorOf> </mirror> </mirrors> </settings> ``` Although we added Maven cache inside `GitHub Action`, the timeouts happen too frequently during access `artifact descriptor`. ``` [ERROR] Failed to execute goal on project spark-mllib_2.12: ... Failed to read artifact descriptor for ... ... Connection timed out (Read failed) -> [Help 1] ``` No. This PR is irrelevant to Jenkins. This is tested on the personal repository first. `GitHub Action` of this PR should pass. - dongjoon-hyun#11 Closes apache#26793 from dongjoon-hyun/SPARK-30163. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 1068b8b) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…thout cache ### What changes were proposed in this pull request? This PR is a follow-up of apache#26793 and aims to initialize `~/.m2` directory. ### Why are the changes needed? In case of cache reset, `~/.m2` directory doesn't exist. It causes a failure. - `master` branch has a cache as of now. So, we missed this. - `branch-2.4` has no cache as of now, and we hit this failure. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? This PR is tested against personal `branch-2.4`. - dongjoon-hyun#12 Closes apache#26794 from dongjoon-hyun/SPARK-30163-2. Authored-by: Dongjoon Hyun <dhyun@apple.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 16f1b23) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…tion is enabled ### What changes were proposed in this pull request? Added `shutdownHook` for shutdown method of executor plugin. This will ensure that shutdown method will be called always. ### Why are the changes needed? Whenever executors are not going down gracefully, i.e getting killed due to idle time or getting killed forcefully, shutdown method of executors plugin is not getting called. Shutdown method can be used to release any resources that plugin has acquired during its initialisation. So its important to make sure that every time a executor goes down shutdown method of plugin gets called. ### Does this PR introduce any user-facing change? No ### How was this patch tested? Tested Manually Closes apache#26841 from iRakson/SPARK-29152_2.4. Authored-by: root1 <raksonrakesh@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
… as expected ### What changes were proposed in this pull request? This patch changes the condition to check if BytesToBytesMap should grow up its internal array. Specifically, it changes to compare by the capacity of the array, instead of its size. ### Why are the changes needed? One Spark job on our cluster hangs forever at BytesToBytesMap.safeLookup. After inspecting, the long array size is 536870912. Currently in BytesToBytesMap.append, we only grow the internal array if the size of the array is less than its MAX_CAPACITY that is 536870912. So in above case, the array can not be grown up, and safeLookup can not find an empty slot forever. But it is wrong because we use two array entries per key, so the array size is twice the capacity. We should compare the current capacity of the array, instead of its size. ### Does this PR introduce any user-facing change? No ### How was this patch tested? This issue only happens when loading big number of values into BytesToBytesMap, so it is hard to do unit test. This is tested manually with internal Spark job. Closes apache#26828 from viirya/fix-bytemap. Lead-authored-by: Liang-Chi Hsieh <viirya@gmail.com> Co-authored-by: Liang-Chi Hsieh <liangchi@uber.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit b4aeaf9) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…ons' option ### What changes were proposed in this pull request? This patch fixes the availability of `minPartitions` option for Kafka source, as it is only supported by micro-batch for now. There's a WIP PR for batch (apache#25436) as well but there's no progress on the PR so far, so safer to fix the doc first, and let it be added later when we address it with batch case as well. ### Why are the changes needed? The doc is wrong and misleading. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Just a doc change. Closes apache#26849 from HeartSaVioR/MINOR-FIX-minPartition-availability-doc. Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit e39bb4c) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…g and integral types backport apache#26871 ----- Check the partition column data type and only allow string and integral types in hive partition pruning. Currently we only support string and integral types in hive partition pruning, but the check is done for literals. If the predicate is `InSet`, then there is no literal and we may pass an unsupported partition predicate to Hive and cause problems. Closes apache#26876 from cloud-fan/backport. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…k properties ignored in spark-submit ### What changes were proposed in this pull request? The value of non-Spark config properties ignored in spark-submit is no longer logged. ### Why are the changes needed? The value isn't really needed in the logs, and could contain potentially sensitive info. While we can redact the values selectively too, I figured it's more robust to just not log them at all here, as the values aren't important in this log statement. ### Does this PR introduce any user-facing change? Other than the change to logging above, no. ### How was this patch tested? Existing tests Closes apache#26893 from srowen/SPARK-30263. Authored-by: Sean Owen <srowen@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 46e950b) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…c allocation is enabled" This reverts commit 74d8cf1.
### What changes were proposed in this pull request? This PR proposes to fix documentation for slide function. Fixed the spacing issue and added some parameter related info. ### Why are the changes needed? Documentation improvement ### Does this PR introduce any user-facing change? No (doc-only change). ### How was this patch tested? Manually tested by documentation build. Closes apache#26896 from bboutkov/pyspark_doc_fix. Authored-by: Boris Boutkov <boris.boutkov@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 3bf5498) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…ge from history server ### What changes were proposed in this pull request? ### Why are the changes needed? Currently from history server, we will not able to access the pool info, as we aren't writing pool information to the event log other than pool name. Already spark is hiding pool table when accessing from history server. But from the pool column in the stage table will redirect to the pools table, and that will throw error when accessing the pools page. To prevent error page, we need to hide the pool column also in the stage table ### Does this PR introduce any user-facing change? No ### How was this patch tested? Manual test Before change:   After change:  Closes apache#26616 from shahidki31/poolHistory. Authored-by: shahid <shahidki31@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> (cherry picked from commit dd217e1) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
{kind=link}
{kind=link}
{kind=link}
…lding keys reaching max capacity
### What changes were proposed in this pull request?
We should not append keys to BytesToBytesMap to be its max capacity.
### Why are the changes needed?
BytesToBytesMap.append allows to append keys until the number of keys reaches MAX_CAPACITY. But once the the pointer array in the map holds MAX_CAPACITY keys, next time call of lookup will hang forever.
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
Manually test by:
```java
Test
public void testCapacity() {
TestMemoryManager memoryManager2 =
new TestMemoryManager(
new SparkConf()
.set(package$.MODULE$.MEMORY_OFFHEAP_ENABLED(), true)
.set(package$.MODULE$.MEMORY_OFFHEAP_SIZE(), 25600 * 1024 * 1024L)
.set(package$.MODULE$.SHUFFLE_SPILL_COMPRESS(), false)
.set(package$.MODULE$.SHUFFLE_COMPRESS(), false));
TaskMemoryManager taskMemoryManager2 = new TaskMemoryManager(memoryManager2, 0);
final long pageSizeBytes = 8000000 + 8; // 8 bytes for end-of-page marker
final BytesToBytesMap map = new BytesToBytesMap(taskMemoryManager2, 1024, pageSizeBytes);
try {
for (long i = 0; i < BytesToBytesMap.MAX_CAPACITY + 1; i++) {
final long[] value = new long[]{i};
boolean succeed = map.lookup(value, Platform.LONG_ARRAY_OFFSET, 8).append(
value,
Platform.LONG_ARRAY_OFFSET,
8,
value,
Platform.LONG_ARRAY_OFFSET,
8);
}
map.free();
} finally {
map.free();
}
}
```
Once the map was appended to 536870912 keys (MAX_CAPACITY), the next lookup will hang.
Closes apache#26914 from viirya/fix-bytemap2.
Authored-by: Liang-Chi Hsieh <liangchi@uber.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
(cherry picked from commit b2baaa2)
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…d in the related functions ### What changes were proposed in this pull request? Link to appropriate Java Class with list of date/time patterns supported ### Why are the changes needed? Avoid confusion on the end-user's side of things, as seen in questions like [this](https://stackoverflow.com/questions/54496878/date-format-conversion-is-adding-1-year-to-the-border-dates) on StackOverflow ### Does this PR introduce any user-facing change? Yes, Docs are updated. ### How was this patch tested? Built docs: 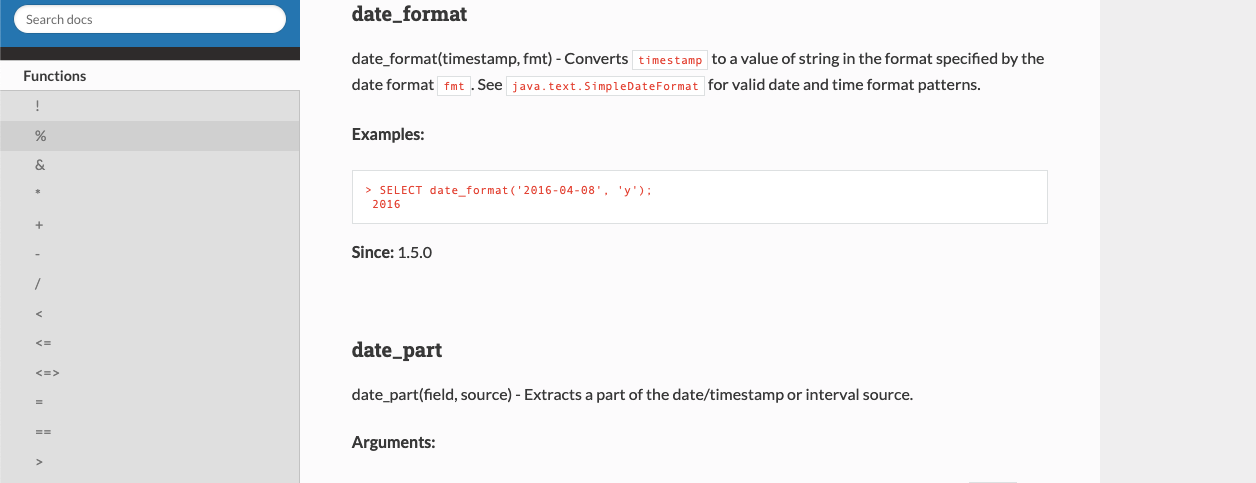 Closes apache#26867 from johnhany97/SPARK-30236-2.4. Authored-by: John Ayad <johnhany97@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
{kind=link}
…SON table When querying a partitioned table with format `org.apache.hive.hcatalog.data.JsonSerDe` and more than one task runs in each executor concurrently, the following exception is encountered: `java.lang.ClassCastException: java.util.ArrayList cannot be cast to org.apache.hive.hcatalog.data.HCatRecord` The exception occurs in `HadoopTableReader.fillObject`. `org.apache.hive.hcatalog.data.JsonSerDe#initialize` populates a `cachedObjectInspector` field by calling `HCatRecordObjectInspectorFactory.getHCatRecordObjectInspector`, which is not thread-safe; this `cachedObjectInspector` is returned by `JsonSerDe#getObjectInspector`. We protect against this Hive bug by synchronizing on an object when we need to call `initialize` on `org.apache.hadoop.hive.serde2.Deserializer` instances (which may be `JsonSerDe` instances). By doing so, the `ObjectInspector` for the `Deserializer` of the partitions of the JSON table and that of the table `SerDe` are the same cached `ObjectInspector` and `HadoopTableReader.fillObject` then works correctly. (If the `ObjectInspector`s are different, then a bug in `HCatRecordObjectInspector` causes an `ArrayList` to be created instead of an `HCatRecord`, resulting in the `ClassCastException` that is seen.) To avoid HIVE-15773 / HIVE-21752. No. Tested manually on a cluster with a partitioned JSON table and running a query using more than one core per executor. Before this change, the ClassCastException happens consistently. With this change it does not happen. Closes apache#26895 from wypoon/SPARK-17398. Authored-by: Wing Yew Poon <wypoon@cloudera.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> (cherry picked from commit c72f88b) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
…mparatorSuite` ### What changes were proposed in this pull request? As mentioned in apache#26548 (review), some test cases in `RecordBinaryComparatorSuite` use a fixed arrayOffset when writing to long arrays, this could lead to weird stuff including crashing with a SIGSEGV. This PR fix the problem by computing the arrayOffset based on `Platform.LONG_ARRAY_OFFSET`. ### How was this patch tested? Tested locally. Previously, when we try to add `System.gc()` between write into long array and compare by RecordBinaryComparator, there is a chance to hit JVM crash with SIGSEGV like: ``` # # A fatal error has been detected by the Java Runtime Environment: # # SIGSEGV (0xb) at pc=0x00007efc66970bcb, pid=11831, tid=0x00007efc0f9f9700 # # JRE version: OpenJDK Runtime Environment (8.0_222-b10) (build 1.8.0_222-8u222-b10-1ubuntu1~16.04.1-b10) # Java VM: OpenJDK 64-Bit Server VM (25.222-b10 mixed mode linux-amd64 compressed oops) # Problematic frame: # V [libjvm.so+0x5fbbcb] # # Core dump written. Default location: /home/jenkins/workspace/sql/core/core or core.11831 # # An error report file with more information is saved as: # /home/jenkins/workspace/sql/core/hs_err_pid11831.log # # If you would like to submit a bug report, please visit: # http://bugreport.java.com/bugreport/crash.jsp # ``` After the fix those test cases didn't crash the JVM anymore. Closes apache#26939 from jiangxb1987/rbc. Authored-by: Xingbo Jiang <xingbo.jiang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? Upgrade jetty to 9.3.27.v20190418 to fix below CVE https://nvd.nist.gov/vuln/detail/CVE-2019-10247 https://nvd.nist.gov/vuln/detail/CVE-2019-10241 tag: https://github.com/eclipse/jetty.project/releases/tag/jetty-9.3.27.v20190418 ### Why are the changes needed? To fix CVE-2019-10247 and CVE-2019-10241 ### Does this PR introduce any user-facing change? No ### How was this patch tested? Existing Test Closes apache#26967 from sandeep-katta/jettyUpgrade. Authored-by: sandeep katta <sandeep.katta2007@gmail.com> Signed-off-by: Sean Owen <srowen@gmail.com>
…her to update stats when analyzing partition ### What changes were proposed in this pull request? This is a backport for [pr#26908](apache#26908). It's an obvious bug: currently when analyzing partition stats, we use old table stats to compare with newly computed stats to decide whether it should update stats or not. ### Why are the changes needed? bug fix ### Does this PR introduce any user-facing change? no ### How was this patch tested? add new tests Closes apache#26963 from wzhfy/failto_update_part_stats_2.4. Authored-by: Zhenhua Wang <wzh_zju@163.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request? Upgrade jackson-databind to 2.6.7.3 to following CVE CVE-2018-14718 - CVE-2018-14721 FasterXML/jackson-databind#2097 CVE-2018-19360, CVE-2018-19361, CVE-2018-19362 FasterXML/jackson-databind#2186 tag: https://github.com/FasterXML/jackson-databind/commits/jackson-databind-2.6.7.3 ### Why are the changes needed? CVE-2018-14718,CVE-2018-14719,CVE-2018-14720,CVE-2018-14721,CVE-2018-19360,CVE-2018-19361,CVE-2018-19362 ### Does this PR introduce any user-facing change? No ### How was this patch tested? Existing UT Closes apache#26986 from sandeep-katta/jacksonUpgrade. Authored-by: sandeep katta <sandeep.katta2007@gmail.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request? Backported from [pr#26994](apache#26994). Currently if function lookup fails, spark will give it a second chance by casting decimal type to double type. But for cases where decimal type doesn't exist, it's meaningless to lookup again and cause extra cost like unnecessary metastore access. We should throw exceptions directly in these cases. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Covered by existing tests. Closes apache#27054 from wzhfy/avoid_udf_fail_twice-2.4. Authored-by: Zhenhua Wang <wzh_zju@163.com> Signed-off-by: Zhenhua Wang <wzh_zju@163.com>
…r regardless of current thread context classloader ### What changes were proposed in this pull request? This patch is based on apache#23921 but revised to be simpler, as well as adds UT to test the behavior. (This patch contains the commit from apache#23921 to retain credit.) Spark loads new JARs for `ADD JAR` and `CREATE FUNCTION ... USING JAR` into jar classloader in shared state, and changes current thread's context classloader to jar classloader as many parts of remaining codes rely on current thread's context classloader. This would work if the further queries will run in same thread and there's no change on context classloader for the thread, but once the context classloader of current thread is switched back by various reason, Spark fails to create instance of class for the function. This bug mostly affects spark-shell, as spark-shell will roll back current thread's context classloader at every prompt. But it may also affects the case of job-server, where the queries may be running in multiple threads. This patch fixes the issue via switching the context classloader to the classloader which loads the class. Hopefully FunctionBuilder created by `makeFunctionBuilder` has the information of Class as a part of closure, hence the Class itself can be provided regardless of current thread's context classloader. ### Why are the changes needed? Without this patch, end users cannot execute Hive UDF using JAR twice in spark-shell. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? New UT. Closes apache#27075 from HeartSaVioR/SPARK-26560-branch-2.4. Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…ncEventQueue#removeListenerOnError There is a deadlock between `LiveListenerBus#stop` and `AsyncEventQueue#removeListenerOnError`. We can reproduce as follows: 1. Post some events to `LiveListenerBus` 2. Call `LiveListenerBus#stop` and hold the synchronized lock of `bus`(https://github.com/apache/spark/blob/5e92301723464d0876b5a7eec59c15fed0c5b98c/core/src/main/scala/org/apache/spark/scheduler/LiveListenerBus.scala#L229), waiting until all the events are processed by listeners, then remove all the queues 3. Event queue would drain out events by posting to its listeners. If a listener is interrupted, it will call `AsyncEventQueue#removeListenerOnError`, inside it will call `bus.removeListener`(https://github.com/apache/spark/blob/7b1b60c7583faca70aeab2659f06d4e491efa5c0/core/src/main/scala/org/apache/spark/scheduler/AsyncEventQueue.scala#L207), trying to acquire synchronized lock of bus, resulting in deadlock This PR removes the `synchronized` from `LiveListenerBus.stop` because underlying data structures themselves are thread-safe. To fix deadlock. No. New UT. Closes apache#26924 from wangshuo128/event-queue-race-condition. Authored-by: Wang Shuo <wangshuo128@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com> (cherry picked from commit 10cae04) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
…leInputStream This bug manifested itself when another stream would potentially make a call to NioBufferedFileInputStream.read() after it had reached EOF in the wrapped stream. In that case, the refill() code would clear the output buffer the first time EOF was found, leaving it in a readable state for subsequent read() calls. If any of those calls were made, bad data would be returned. By flipping the buffer before returning, even in the EOF case, you get the correct behavior in subsequent calls. I picked that approach to avoid keeping more state in this class, although it means calling the underlying stream even after EOF (which is fine, but perhaps a little more expensive). This showed up (at least) when using encryption, because the commons-crypto StreamInput class does not track EOF internally, leaving it for the wrapped stream to behave correctly. Tested with added unit test + slightly modified test case attached to SPARK-18105. Closes apache#27084 from vanzin/SPARK-30225. Authored-by: Marcelo Vanzin <vanzin@cloudera.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
|
Can one of the admins verify this patch? |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
20 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
Add these test cases for resolution of ORC table location reported by SPARK-25993
Why are the changes needed?
Does this PR introduce any user-facing change?
How was this patch tested?