[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints#27466
[SPARK-30722][PYTHON][DOCS] Update documentation for Pandas UDF with Python type hints#27466HyukjinKwon wants to merge 6 commits intoapache:masterfrom
Conversation
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
This comment has been minimized.
d3eb543 to
4f85930
Compare
| "pyspark.sql.avro.functions", | ||
| "pyspark.sql.pandas.conversion", | ||
| "pyspark.sql.pandas.map_ops", | ||
| "pyspark.sql.pandas.functions", |
There was a problem hiding this comment.
All the tests in pyspark.sql.pandas.functions should be conditionally ran - It should skip the tests if pandas or PyArrow are not available. However, we have been skipping them always due to the lack of mechanism to conditionally run the doctests.
Now, the doctests at pyspark.sql.pandas.functions have type hints that are only for Python 3.5+. So, even if we skip all the tests like the previous way, it shows compilation error due to illegal syntax in Python 2. This is why I had to remove this from the module list to avoid compiling the doctests at all.
| @@ -65,132 +65,188 @@ Spark will fall back to create the DataFrame without Arrow. | |||
|
|
|||
| ## Pandas UDFs (a.k.a. Vectorized UDFs) | |||
There was a problem hiding this comment.
Please see also the PR description of #27165 (comment)
| # | 9| | ||
| # +---+ | ||
|
|
||
| # In the UDF, you can initialize some states before processing batches. |
There was a problem hiding this comment.
I removed this example. It seems too much to know, and the example itself doesn't look particularly useful.
|
|
||
| :class:`MapType`, nested :class:`StructType` are currently not supported as output types. | ||
|
|
||
| Scalar UDFs can be used with :meth:`pyspark.sql.DataFrame.withColumn` and |
There was a problem hiding this comment.
I removed this info. To me it looks too much to know. I just said "A Pandas UDF behaves as a regular PySpark function API in general." instead.
|
|
||
| .. note:: The length of `pandas.Series` within a scalar UDF is not that of the whole input | ||
| column, but is the length of an internal batch used for each call to the function. | ||
| Therefore, this can be used, for example, to ensure the length of each returned |
There was a problem hiding this comment.
I removed this example. This is already logically known since it says the length of input is not the whole series, and the lengths of input and output should be same.
| .. note:: It is not guaranteed that one invocation of a scalar iterator UDF will process all | ||
| batches from one partition, although it is currently implemented this way. | ||
| Your code shall not rely on this behavior because it might change in the future for | ||
| further optimization, e.g., one invocation processes multiple partitions. |
There was a problem hiding this comment.
I removed this note. Unless we explicitly document, nothing is explicitly guaranteed. It seems to me too much to know.
| further optimization, e.g., one invocation processes multiple partitions. | ||
|
|
||
| Scalar iterator UDFs are used with :meth:`pyspark.sql.DataFrame.withColumn` and | ||
| :meth:`pyspark.sql.DataFrame.select`. |
There was a problem hiding this comment.
I removed this too as the same reason as https://github.com/apache/spark/pull/27466/files#r375215947
| | 9| | ||
| +---+ | ||
|
|
||
| In the UDF, you can initialize some states before processing batches, wrap your code with |
There was a problem hiding this comment.
I removed this as the same reason as https://github.com/apache/spark/pull/27466/files#r375215066
|
|
||
| 3. GROUPED_MAP | ||
|
|
||
| A grouped map UDF defines transformation: A `pandas.DataFrame` -> A `pandas.DataFrame` |
There was a problem hiding this comment.
Moved to applyInPandas at GroupedData. Missing information from here was ported to there.
| return _create_udf(f, returnType, evalType) | ||
|
|
||
|
|
||
| def _test(): |
There was a problem hiding this comment.
| +---+-------------------+ | ||
|
|
||
| .. seealso:: :meth:`pyspark.sql.functions.pandas_udf` | ||
| Alternatively, the user can pass a function that takes two arguments. |
There was a problem hiding this comment.
Information ported from GROUPED MAP in pandas_udf.
|
cc @rxin, @zero323, @cloud-fan, @mengxr, @viirya, @dongjoon-hyun, @WeichenXu123, @ueshin, @BryanCutler, @icexelloss, @rberenguel FYI I would appreciate if you guys have some time to take a quick look. It has to be in Spark 3.0 but RC is supposed to start very soon, Mid Feb 2020. |
This comment has been minimized.
This comment has been minimized.
| ### Iterator of Series to Iterator of Series | ||
|
|
||
| The following example shows how to create scalar iterator Pandas UDFs: | ||
| The type hint can be expressed as `Iterator[pandas.Series]` -> `Iterator[pandas.Series]`. |
There was a problem hiding this comment.
Nitpick. It is more Iterator[Union[Tuple[pandas.Series, ...], pandas.Series]] -> Iterator[pandas.Series], isn't it? But I guess that's too much...
There was a problem hiding this comment.
True .. although I didn't add Iterator[Union[Tuple[pandas.Series, ...], pandas.Series]] type hint to support yet ...
I think we can combine it later if we happen to add this type hint as well. Shouldn't be a big deal at this moment.
This comment has been minimized.
This comment has been minimized.
 BryanCutler
left a comment
BryanCutler
left a comment
There was a problem hiding this comment.
I took a quick look and seems pretty good to me. Thanks @HyukjinKwon !
| globs['spark'] = spark | ||
| # Hack to skip the unit tests in register. These are currently being tested in proper tests. | ||
| # We should reenable this test once we completely drop Python 2. | ||
| del pyspark.sql.udf.UDFRegistration.register |
There was a problem hiding this comment.
To doubly make sure, I tested and checked:
- that it doesn't affect the main codes:
>>> help(spark.udf.register)
Help on method register in module pyspark.sql.udf:
register(name, f, returnType=None) method of pyspark.sql.udf.UDFRegistration instance
...
-
the generated doc too just to make sure.
-
the tests pass.
|
Test build #117958 has finished for PR 27466 at commit
|
|
Test build #117965 has finished for PR 27466 at commit
|
| @@ -65,132 +65,215 @@ Spark will fall back to create the DataFrame without Arrow. | |||
|
|
|||
| ## Pandas UDFs (a.k.a. Vectorized UDFs) | |||
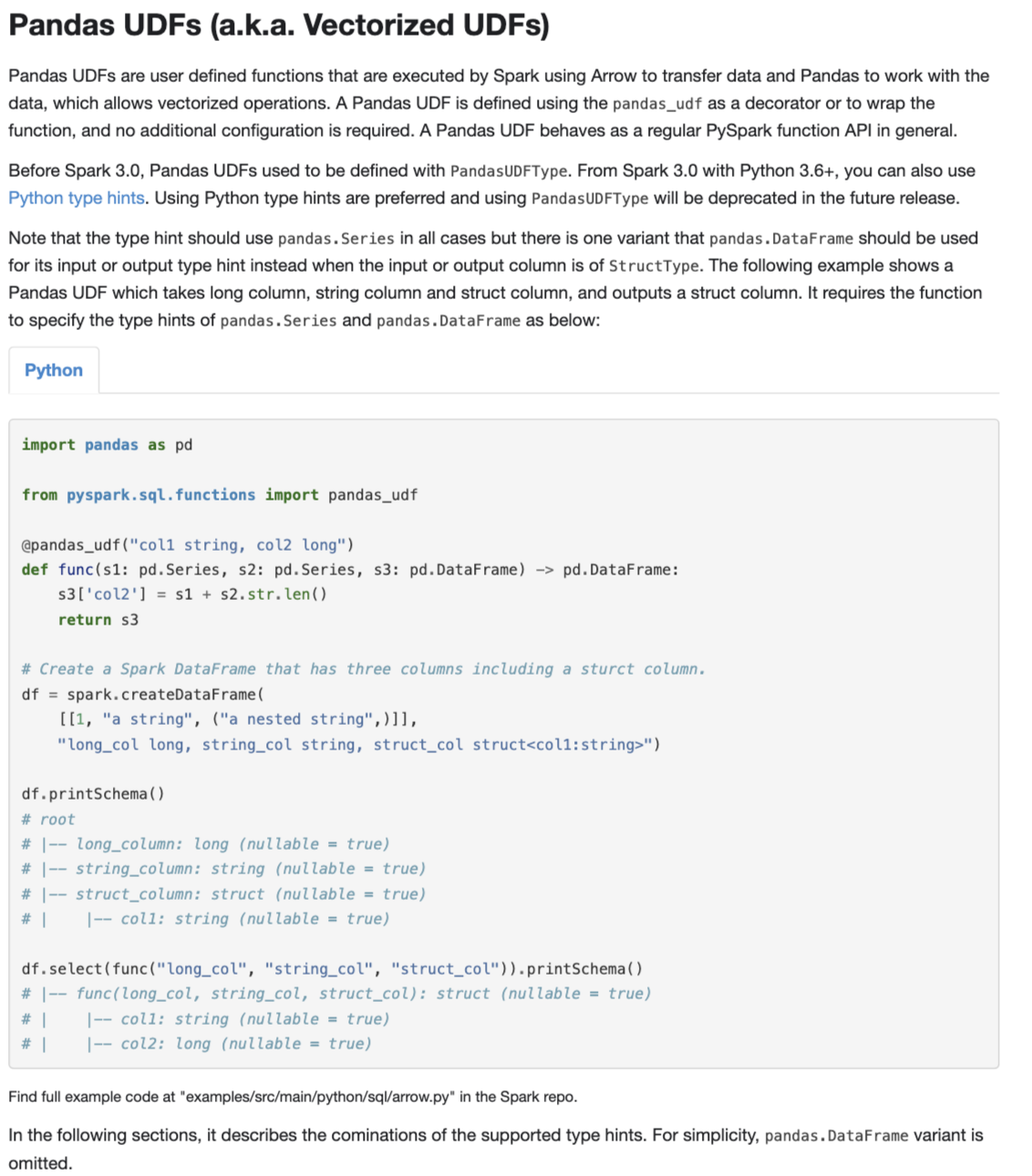
|
Test build #118008 has finished for PR 27466 at commit
|
|
Test build #118087 has finished for PR 27466 at commit
|
|
Should be ready for a look. |
|
Test build #118222 has finished for PR 27466 at commit
|
|
Thanks all. Merged to master and branch-3.0. |
…Python type hints ### What changes were proposed in this pull request? This PR targets to document the Pandas UDF redesign with type hints introduced at SPARK-28264. Mostly self-describing; however, there are few things to note for reviewers. 1. This PR replace the existing documentation of pandas UDFs to the newer redesign to promote the Python type hints. I added some words that Spark 3.0 still keeps the compatibility though. 2. This PR proposes to name non-pandas UDFs as "Pandas Function API" 3. SCALAR_ITER become two separate sections to reduce confusion: - `Iterator[pd.Series]` -> `Iterator[pd.Series]` - `Iterator[Tuple[pd.Series, ...]]` -> `Iterator[pd.Series]` 4. I removed some examples that look overkill to me. 5. I also removed some information in the doc, that seems duplicating or too much. ### Why are the changes needed? To document new redesign in pandas UDF. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Existing tests should cover. Closes #27466 from HyukjinKwon/SPARK-30722. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit aa6a605) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…Python type hints ### What changes were proposed in this pull request? This PR targets to document the Pandas UDF redesign with type hints introduced at SPARK-28264. Mostly self-describing; however, there are few things to note for reviewers. 1. This PR replace the existing documentation of pandas UDFs to the newer redesign to promote the Python type hints. I added some words that Spark 3.0 still keeps the compatibility though. 2. This PR proposes to name non-pandas UDFs as "Pandas Function API" 3. SCALAR_ITER become two separate sections to reduce confusion: - `Iterator[pd.Series]` -> `Iterator[pd.Series]` - `Iterator[Tuple[pd.Series, ...]]` -> `Iterator[pd.Series]` 4. I removed some examples that look overkill to me. 5. I also removed some information in the doc, that seems duplicating or too much. ### Why are the changes needed? To document new redesign in pandas UDF. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Existing tests should cover. Closes apache#27466 from HyukjinKwon/SPARK-30722. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
What changes were proposed in this pull request?
This PR targets to document the Pandas UDF redesign with type hints introduced at SPARK-28264.
Mostly self-describing; however, there are few things to note for reviewers.
This PR replace the existing documentation of pandas UDFs to the newer redesign to promote the Python type hints. I added some words that Spark 3.0 still keeps the compatibility though.
This PR proposes to name non-pandas UDFs as "Pandas Function API"
SCALAR_ITER become two separate sections to reduce confusion:
Iterator[pd.Series]->Iterator[pd.Series]Iterator[Tuple[pd.Series, ...]]->Iterator[pd.Series]I removed some examples that look overkill to me.
I also removed some information in the doc, that seems duplicating or too much.
Why are the changes needed?
To document new redesign in pandas UDF.
Does this PR introduce any user-facing change?
No.
How was this patch tested?
Existing tests should cover.