[SPARK-31069][CORE] Avoid repeat compute chunksBeingTransferred cause hight cpu cost in external shuffle service when maxChunksBeingTransferred use default value.
#30139
Conversation
|
ping @wangyum @dongjoon-hyun @HeartSaVioR @jiangxb1987 @Ngone51 |
|
Thank you @AngersZhuuuu' number. We have been running this change for more than half a year. |
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Kubernetes integration test starting |
|
Test build #130198 has finished for PR 30139 at commit
|
|
Kubernetes integration test status success |
|
Test build #130199 has finished for PR 30139 at commit
|
|
+CC @otterc |
|
Could you add an empty commit whose authorship is the original author, @AngersZhuuuu . If then, Apache Spark merge script can give both of you the authorship properly. |
Done this. thanks for mention this point. |
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Test build #130241 has finished for PR 30139 at commit
|
 mridulm
left a comment
mridulm
left a comment
There was a problem hiding this comment.
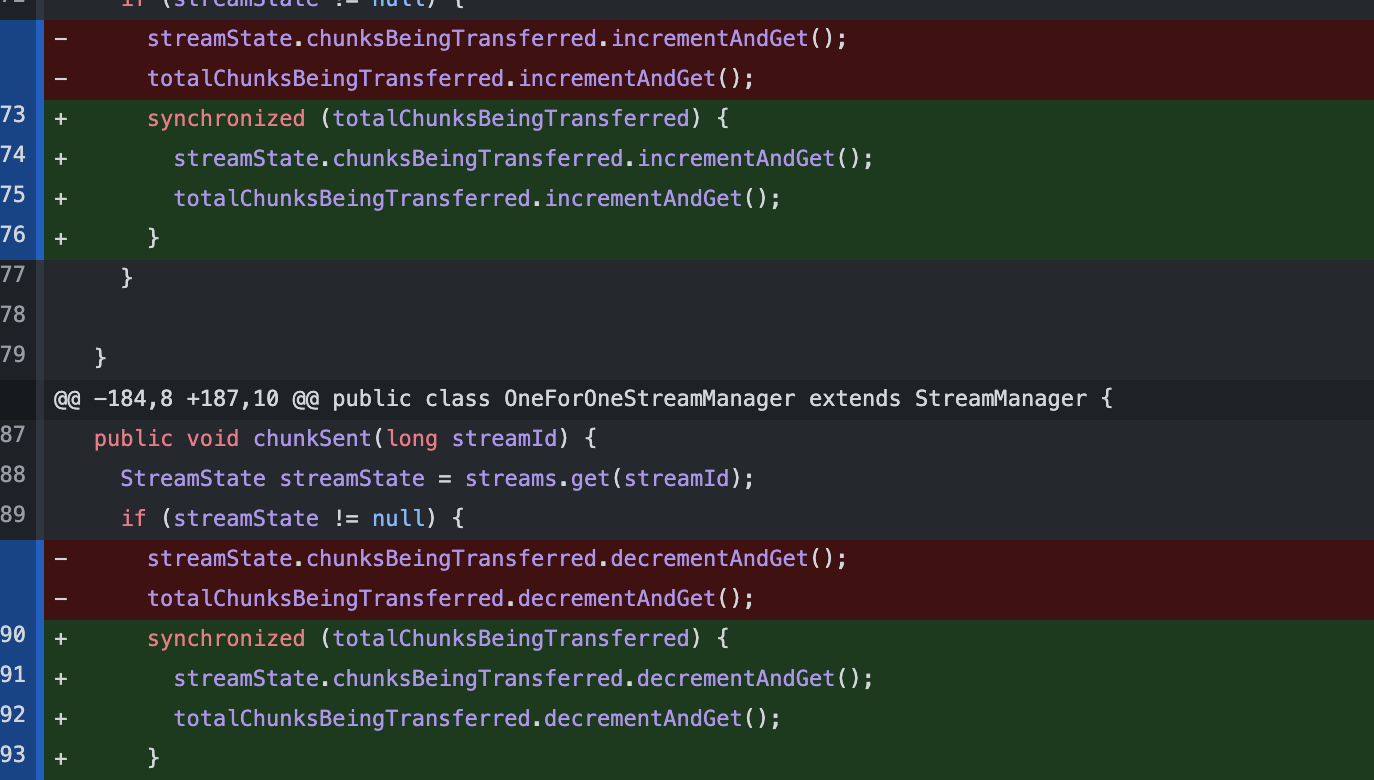
I am concerned that the totalChunksBeingTransferred can diverge over time from state of streams when there are concurrent updates. Either updates to both should be within the same critical section, or we should carefully ensure there is no potential for divergence. Can you relook and ensure this is not the case ?
For example, can there be concurrent execution between chunkBeingSent, chunkSent and connectionTerminated ? If yes, can we ensure the state remains consistent.
In origin code, we just use a concurrent hash map(streams) and also there no strong locking mechanism. And IMO, we can add a lock to keep strong consistence of value And I have run the test in desc, this change has little effect on performance. WDYT? |
|
Yes we should ensure the streamState and the totalChunksBeingTransfered are updated synchronically. Other than that the PR looks good! |
|
|
||
| private final AtomicLong nextStreamId; | ||
| private final ConcurrentHashMap<Long, StreamState> streams; | ||
| private final AtomicLong totalChunksBeingTransferred = new AtomicLong(0); |
There was a problem hiding this comment.
nit: maybe rename to numChunksBeingTransferred? Because it's not accumulating all the chunks that are transferred in history.
There was a problem hiding this comment.
nit: maybe rename to
numChunksBeingTransferred? Because it's not accumulating all the chunks that are transferred in history.
Updated
This should have a considerable impact on the performance when there are multiple open streams because updates of different streams would lock on a single object |
Since |
Hmmm. Every update to |
How about current change? Don't use AtomicLong but use |
I know that, but as @jiangxb1987 @mridulm mentioned, we need to ensure the streamState and the totalChunksBeingTransfered are updated synchronically. Add this lock is a strong guarantee. The execution process in the middle of the lock is very fast, so the impact is not really significant. Also, It's a huge leap in performance compared to what it was before |
We reduce many race condition on |
|
Sorry but your latest change doesn't actually lock properly. Long is immutable, and you always replace the object when you do the calculation and assign to the field, which is used as a lock. Your best try would be changing it to long (to avoid box/unbox), and have a separate Object field as locking purpose. |
a big mistake, thanks for your suggestion. |
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Test build #130779 has finished for PR 30139 at commit
|
|
I see this is now only making exception on not calculating the chunksBeingTransferred on default value of config. This is far from the original approach, so could you please update PR title and description based on the new change? IMHO we no longer fixes SPARK-31069 via this PR, but if there's no good idea to address the root issue, it'd be OK to keep this to be associated with SPARK-31069. If someone encounters with the issue setting the config as non-default, the issue would be filed again and we can work on the new JIRA issue. |
chunksBeingTransferred cause hight cpu cost in external shuffle service when maxChunksBeingTransferred use default value.
Yea, updated and added guidelines for users who need to use the origin PR #27831 |
|
@AngersZhuuuu To clarify, the updated behavior of the PR is that by default we dont incur the cost of computing I am fine with the change, ideally we should fix the behavior even when |
Yea, need to think about how to guarantee performance and consistent execution with minimal overhead as followup work. Current change will solve most users' problems. |
|
+CC @srowen, @jiangxb1987, @cloud-fan |
|
+CC @otterc, @wangyum, @HeartSaVioR, @Ngone51 who also reviewed this change. |
 HeartSaVioR
left a comment
HeartSaVioR
left a comment
There was a problem hiding this comment.
+1 Looks OK to me.
It'd be ideal if we could find the good way we all agree to resolve the origin problem, but it doesn't look like that easy.
 otterc
left a comment
otterc
left a comment
There was a problem hiding this comment.
Other than the nits, looks good to me.
| long chunksBeingTransferred = streamManager.chunksBeingTransferred(); | ||
| if (chunksBeingTransferred >= maxChunksBeingTransferred) { | ||
| logger.warn("The number of chunks being transferred {} is above {}, close the connection.", | ||
| chunksBeingTransferred, maxChunksBeingTransferred); |
There was a problem hiding this comment.
Nit: indentation should be 2
There was a problem hiding this comment.
Nit: indentation should be 2
Done
| long chunksBeingTransferred = streamManager.chunksBeingTransferred(); | ||
| if (chunksBeingTransferred >= maxChunksBeingTransferred) { | ||
| logger.warn("The number of chunks being transferred {} is above {}, close the connection.", | ||
| chunksBeingTransferred, maxChunksBeingTransferred); |
There was a problem hiding this comment.
Nit: indentation should be 2 spaces
There was a problem hiding this comment.
Nit: indentation should be 2 spaces
Done
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #131087 has finished for PR 30139 at commit
|
|
Any update? |
|
+CC @srowen, @HyukjinKwon I merged the pr via ./dev/merge_spark_pr.py - but it failed with following [1] I had run a git fetch -all and git pull before merging. A subsequent pull showed no conflicts with local [2]. Any idea why there is a disconnect between github and apache repo ? Thanks. [1] [2] |
|
Scratch that - was a concurrent merge issue at git, not seen this before :-) |
|
Thanks for fixing this @AngersZhuuuu ! Thanks for the reviews @jiangxb1987, @HeartSaVioR, @otterc, @srowen, @cloud-fan |
|
I became a committer after gitbox integration, and according to the guide, I guess we no longer need to set up ASF git as remote repo. |
|
@AngersZhuuuu Can you update the jira please ? I am not sure if I have added your id as assignee |
|
My repo config's are from ages back @HeartSaVioR :-) |
assignee is me now, any other information need update? |

|
Thanks ! |
|
Yeah .. I migrated to gitbox completely IIRC. I remember there was a similar syncing issue without the migration. Now committers have to set up according to https://infra.apache.org/apache-github.html if I am not wrong. FYI, I believe we now can use interchangeably gitbox and github. This is my remote FYI: git remote -v |
What changes were proposed in this pull request?
Followup from #27831 , origin author @chrysan.
Each request it will check
chunksBeingTransferredsuch as
It will traverse
streamsrepeatedly and we know that fetch data chunk will accessstreamtoo, there cause two problem:streams, the longer the length, the longer the timestreamsIn this PR, when
maxChunksBeingTransferreduse default value, we avoid computechunksBeingTransferredsince we don't care about this. If user want to set this configuration and meet performance problem, you can also backport PR #27831Why are the changes needed?
Speed up getting
chunksBeingTransferredand avoid lock race in objectstreamsDoes this PR introduce any user-facing change?
No
How was this patch tested?
Existed UT