[SPARK-33187][SQL] Add a check on the number of returned partitions in the HiveShim#getPartitionsByFilter method #30225
Conversation
|
Can one of the admins verify this patch? |
|
Could you add tests? btw, does hive have a similar config? |
|
Is it a good design if partition number larger than 100000? |
User queries generally do not exceed 100000 partitions. It's just that filter can't filter partitions very well.
|
I'll think about adding a test. |
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
Outdated
Show resolved
Hide resolved
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
Outdated
Show resolved
Hide resolved
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
Outdated
Show resolved
Hide resolved
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
Outdated
Show resolved
Hide resolved
There was a problem hiding this comment.
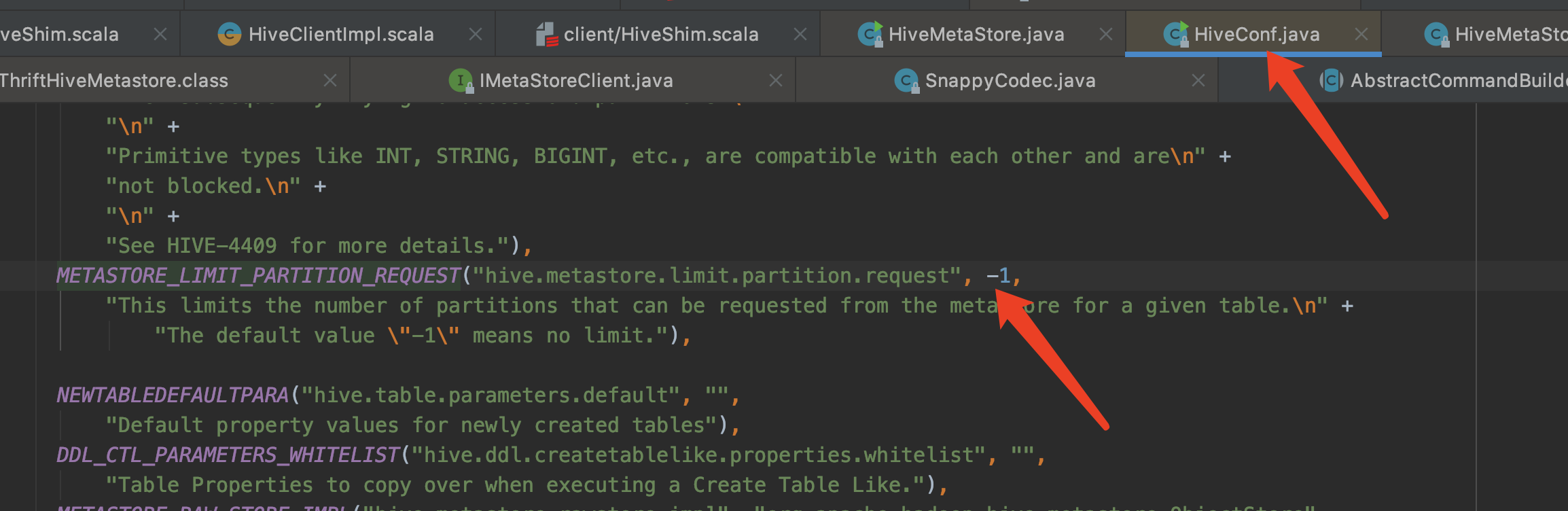
Could you verify is hive.metastore.limit.partition.request works? if it works, we can add it to document. We have added a Hadoop config before: mapreduce.fileoutputcommitter.algorithm.version.
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
Outdated
Show resolved
Hide resolved
| .version("3.1.0") | ||
| .intConf | ||
| .checkValue(_ >= -1, "The maximum must be a positive integer, -1 to follow the Hive config.") | ||
| .createWithDefault(100000) |
There was a problem hiding this comment.
have you considered to keep the default behavior as it is but allow it to be configurable? changing it means now we'll need to make two HMS calls (one additional getNumPartitionsByFilter) which I'm not sure is desirable (have seen HMS perform very badly in production before).
There was a problem hiding this comment.
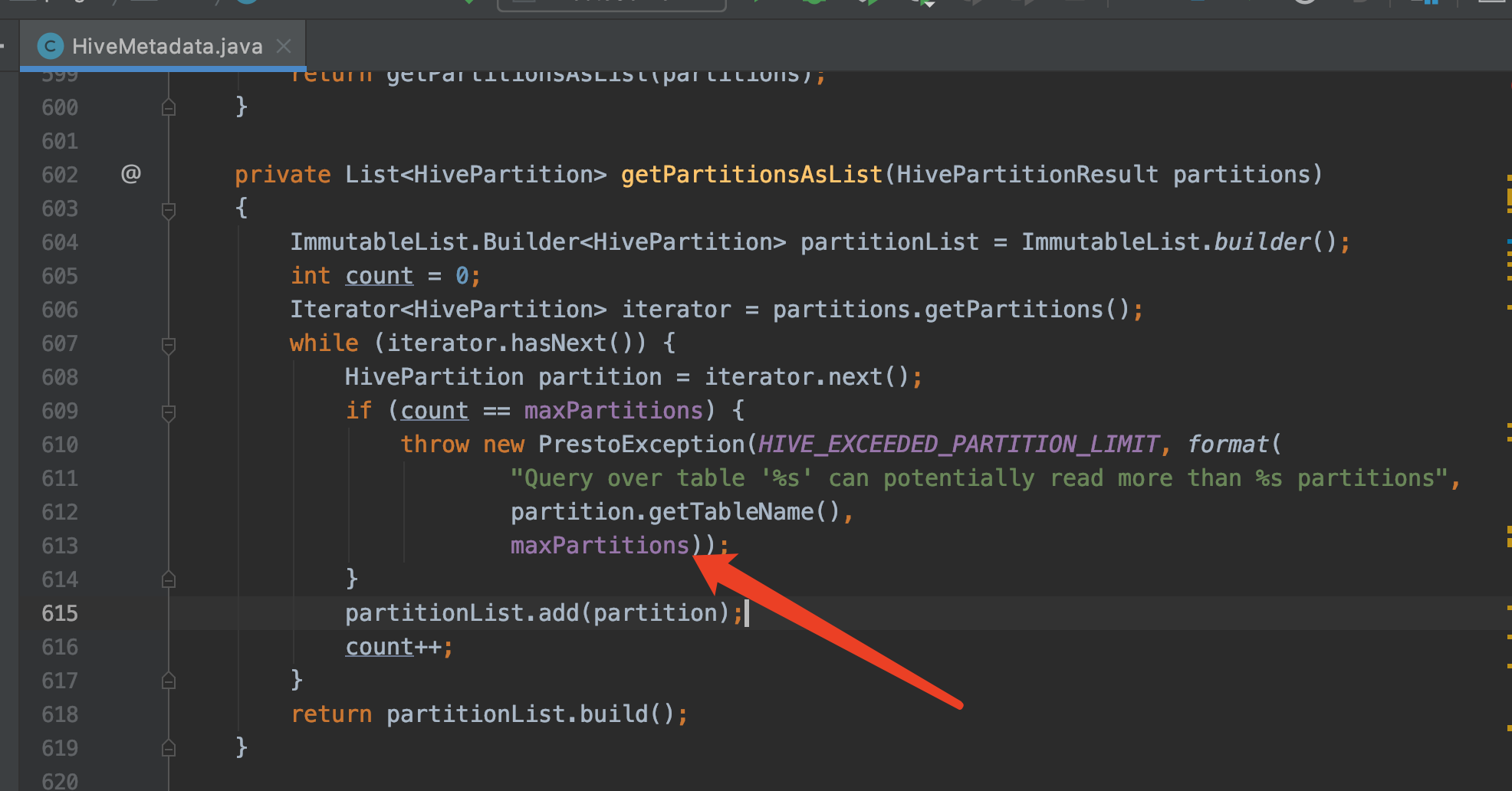
@sunchao Thank you for your response. I think this is a reasonable maximum, and Presto also has a parameter to limit the number of partitions in HiveMetadata#getPartitionsAsList, default value is 100_000
There was a problem hiding this comment.
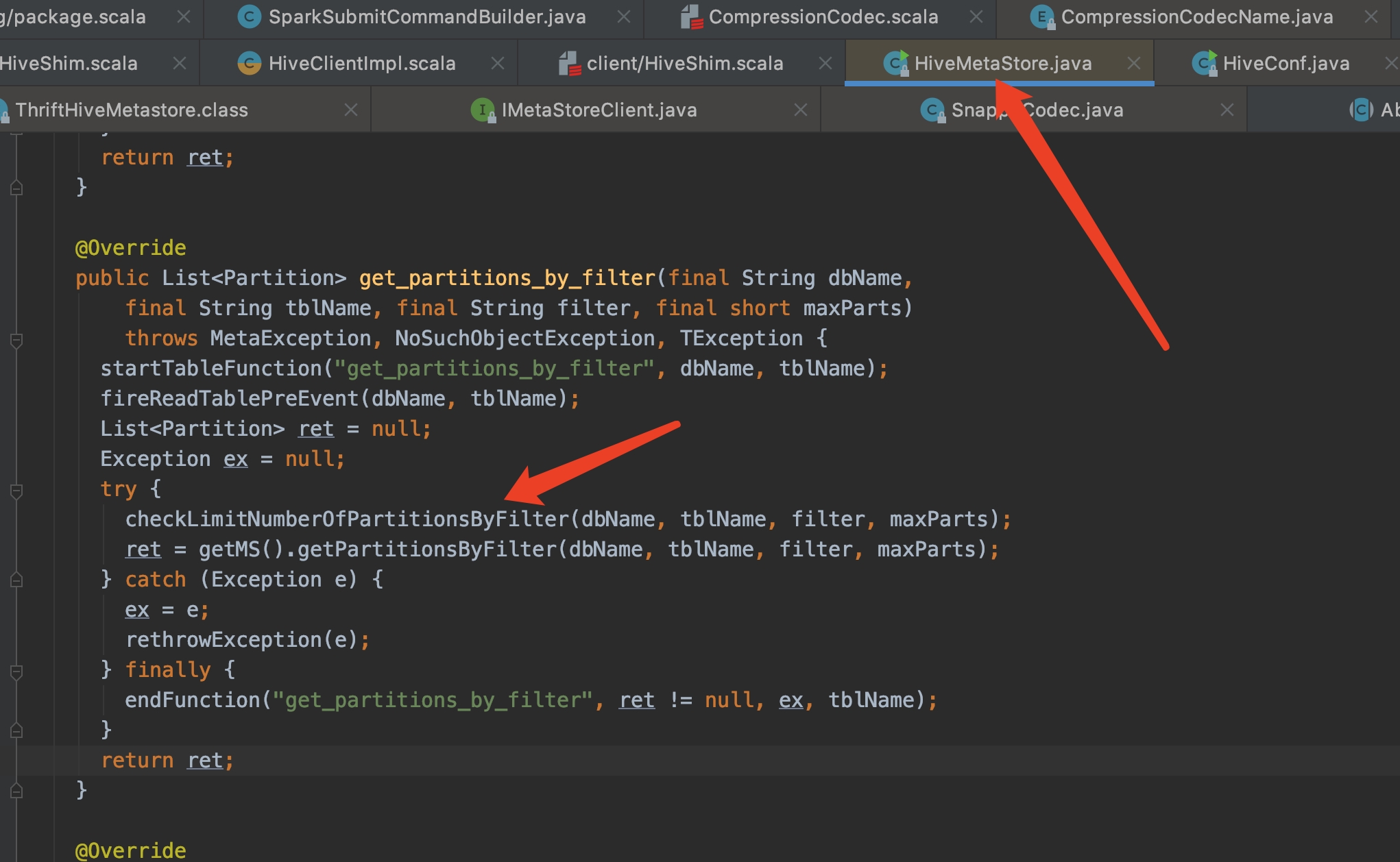
Yea the default value 100_000 looks fine to me. My main question is whether we need to make the default value to be that and double the HMS calls. Presto doesn't call getNumPartitionsByFilter it seems as it streams through a partition iterator and stops once the threshold is reached.
@wangyum It does not work on the client |
|
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. |
What changes were proposed in this pull request?
Add a check on the number of returned metastore partitions by calling Hive#getNumPartitionsByFilter, and add SQLConf spark.sql.hive.metastorePartitionLimit, default value is 100_000
Why are the changes needed?
In the method Shim#getPartitionsByFilter, when filter is empty or when the hive table has a large number of partitions, calling getAllPartitionsMethod or getPartitionsByFilterMethod will results in Driver OOM.
Does this PR introduce any user-facing change?
No
How was this patch tested?
This change is already covered by existing tests