[SPARK-36967][CORE] Report accurate shuffle block size if its skewed#34234
[SPARK-36967][CORE] Report accurate shuffle block size if its skewed#34234wankunde wants to merge 10 commits intoapache:masterfrom
Conversation
 Ngone51
left a comment
Ngone51
left a comment
There was a problem hiding this comment.
The general idea makes sense to me.
There was a problem hiding this comment.
Thanks for this PR. This seems similar to the stale PR #32733 by @exmy (cc @mridulm who reviewed that PR).
The goal of HighlyCompressedMapStatus is to achieve a trade-off between the storage space of the compressed map status and the accuracy of size information for large blocks. We care about accurate block sizes for two reasons:
- Reducers use estimated block sizes in order to limit the total amount of data that they try to fetch at a given time. If the estimated block sizes are severe underestimates then reducers may fetch more data than intended, potentially causing OOMs.
- Spark SQL's
OptimizeSkewJoinrule uses map output statistics to identify skewed partitions). If we underestimate the sizes of skewed map outputs then we'll underestimate partitions sizes and thereby fail to perform skew-join optimization.
I think that PR #32733 was primarily motivated by (1) whereas this PR is motivated by (2), but the issues are related.
A key difference between the two PRs is the threshold for deciding whether to report a more accurate size for a skewed map output: #32733 compared against 5x the average non-empty map output size (plus an additional configurable threshold), whereas this PR compares against the median map output size.
Given how Spark SQL's skew optimization works, I think it makes sense to compare against the median rather than the average. In that code, a partition is considered skewed if its size is larger than spark.sql.adaptive.skewJoin.skewedPartitionFactor * medianPartitionSize and larger than spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes. With default configuration values, a partition is considered to be skewed if size > 5 * medianSize && size > 256MB. Note that these thresholds apply to reduce partition sizes (summing map output sizes to obtain the total input size of each reduce partition).
I guess the main risk to this change is that we could somehow report too many large blocks, thereby increasing memory pressure on the driver and reduce tasks (which currently need to hold all of the map statuses in memory). Theoretically I could create a contrived map output size distribution where up to half of the map outputs are > 5 * medianSize but maybe that pathological distribution is unlikely to occur in practice.
I'll keep brainstorming about this.
There was a problem hiding this comment.
It looks like this code is copied form
Instead of copy-paste duplicating it, I think we should extract the common code into a median(long[]) helper method in org.apache.spark.Utils.
|
If we proceed with this approach then I think we should add new unit tests. We might be able to re-use test cases / logic from from https://github.com/apache/spark/pull/32733/files#diff-6f905716753c4647e146b60bb2e397cb19b7cda76f05208cbbdc891a5f16d54a |
There was a problem hiding this comment.
For shuffle map stages with large number of partitions, the benefits of more accurate estimation are at odds with nontrivial cost of maintaining accurate statistics.
Unfortunately any statistics we pick (median, avg, x-th percentile, x-th percentile * scale, top N'th value, etc) has drawbacks - either with increased memory use, or inaccuracy in statistics.
As long as we can turn the behavior off, that should minimize the impact for degenerate situations.
Thoughts ?
There was a problem hiding this comment.
Given the cost, compute this only if required ?
There was a problem hiding this comment.
I don't think the sort of thousands of number will cost too much ? Am i right ?
There was a problem hiding this comment.
Let us avoid unnecessary allocations and cost.
There was a problem hiding this comment.
Yes, I have updated PR, sort the shuffle blocks only if user enable this future manually. Is this OK?
There was a problem hiding this comment.
Enable this only if explicitly configured ? So that we preserve behavior and see what the impact would be.
We can make it a default in future.
There was a problem hiding this comment.
There are many long running skewed jobs in our cluster, but the driver does not recognize the skewed tasks.
For example, the job in the PR description.
There was a problem hiding this comment.
If we are making a change to the current behavior, I would prefer to keep it disabled by default and enable it explicitly.
There was a problem hiding this comment.
Thanks @mridulm , I just updated code, and disable this behavior by default. Could you help me to review again ?
|
Hi, @Ngone51 @JoeyValentine @mridulm |
 mridulm
left a comment
mridulm
left a comment
There was a problem hiding this comment.
Just had a couple of comments, +CC @JoshRosen, @Ngone51
There was a problem hiding this comment.
nit: Avoid this duplication and pull this value out of the if/else ?
There was a problem hiding this comment.
Finished to pull the code out of if/else.
Thanks
There was a problem hiding this comment.
Do we want to make this a doubleConf ?
There was a problem hiding this comment.
Updated this conf to doubelConf
|
Ok to test |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #144577 has finished for PR 34234 at commit
|
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #144581 has finished for PR 34234 at commit
|
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
hi, @attilapiros |
|
Jenkins retest this please |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #144805 has finished for PR 34234 at commit
|
There was a problem hiding this comment.
Had one comment, rest looks good to me.
+CC @Ngone51, @JoshRosen, @attilapiros
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #145229 has finished for PR 34234 at commit
|
|
The changes look reasonable to me - but will want additional eyes on this. |
|
Hi, @Ngone51 @JoshRosen @attilapiros |
 attilapiros
left a comment
attilapiros
left a comment
There was a problem hiding this comment.
some ideas to make the tests more readable
core/src/test/scala/org/apache/spark/scheduler/MapStatusSuite.scala
Outdated
Show resolved
Hide resolved
core/src/test/scala/org/apache/spark/scheduler/MapStatusSuite.scala
Outdated
Show resolved
Hide resolved
core/src/test/scala/org/apache/spark/scheduler/MapStatusSuite.scala
Outdated
Show resolved
Hide resolved
core/src/test/scala/org/apache/spark/scheduler/MapStatusSuite.scala
Outdated
Show resolved
Hide resolved
|
@attilapiros Thanks for your review. I have updated UT, could you help review the code again. Thanks. |
core/src/test/scala/org/apache/spark/scheduler/MapStatusSuite.scala
Outdated
Show resolved
Hide resolved
core/src/test/scala/org/apache/spark/scheduler/MapStatusSuite.scala
Outdated
Show resolved
Hide resolved
attilapiros
left a comment
There was a problem hiding this comment.
Thanks @wankunde!
LGTM
### What changes were proposed in this pull request? A shuffle block is considered as skewed and will be accurately recorded in HighlyCompressedMapStatus if its size if larger than this factor multiplying the median shuffle block size. Before this change 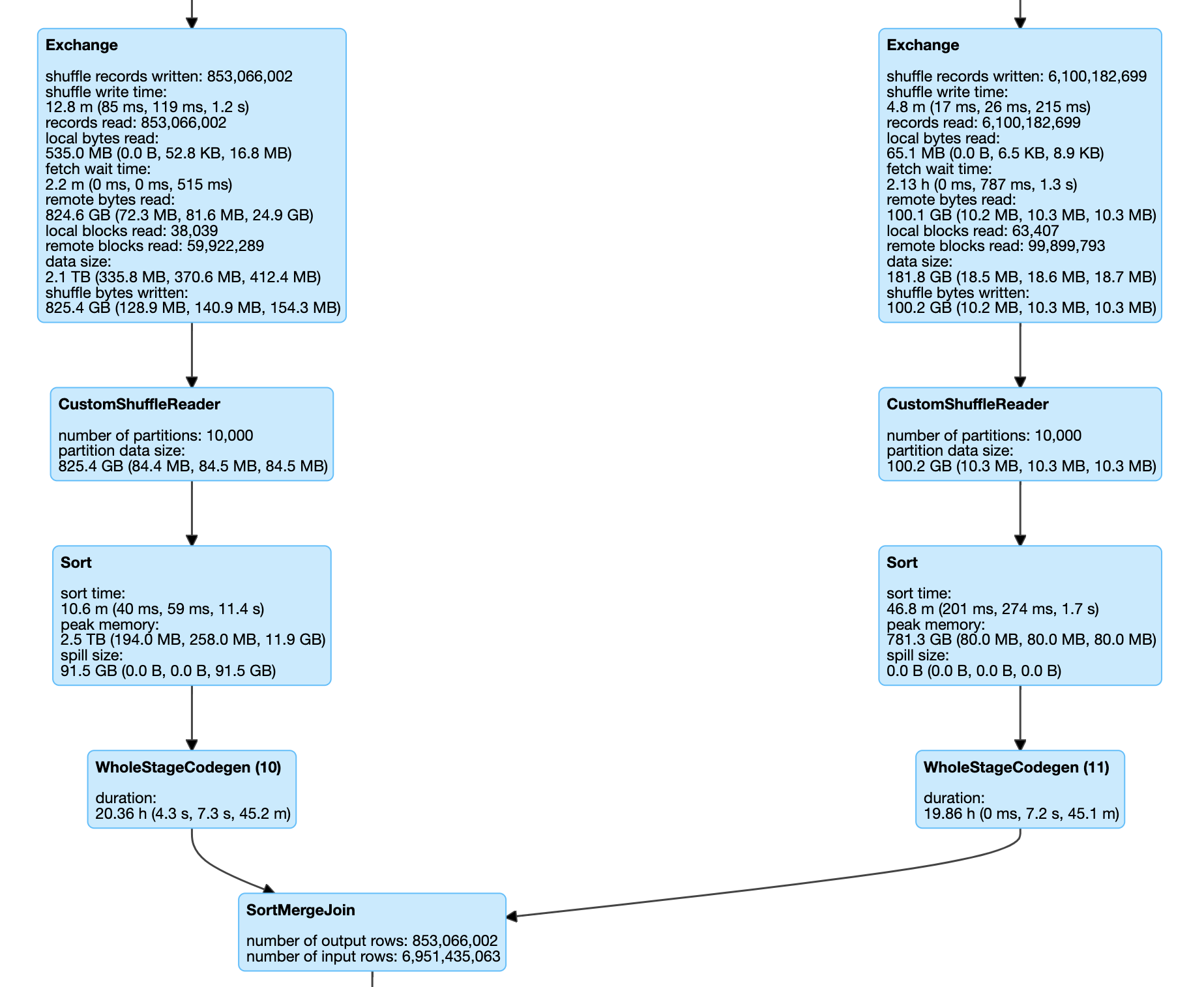 After this change  ### Why are the changes needed? Now map task will report accurate shuffle block size if the block size is greater than "spark.shuffle.accurateBlockThreshold"( 100M by default ). But if there are a large number of map tasks and the shuffle block sizes of these tasks are smaller than "spark.shuffle.accurateBlockThreshold", there may be unrecognized data skew. For example, there are 10000 map task and 10000 reduce task, and each map task create 50M shuffle blocks for reduce 0, and 10K shuffle blocks for the left reduce tasks, reduce 0 is data skew, but the stat of this plan do not have this information. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Update exists UTs Closes apache#34234 from wankunde/map_status. Authored-by: Kun Wan <wankun@apache.org> Signed-off-by: attilapiros <piros.attila.zsolt@gmail.com>
{kind=link}
{kind=link}
| val threshold = | ||
| if (accurateBlockSkewedFactor > 0) { | ||
| val sortedSizes = uncompressedSizes.sorted | ||
| val medianSize: Long = Utils.median(sortedSizes) |
There was a problem hiding this comment.
it seems we sort uncompressedSizes twice. The sortedSizes is sorted but the Utils.median sort it again.
There was a problem hiding this comment.
Yes, uncompressedSizes is sorted twice. Maybe we can change Utils.median(sizes: Array[Long]) to Utils.median(sizes: Array[Long], alreadySorted: Boolean = false), and change Utils.median(sortedSizes) to Utils.median(sortedSizes, true) to avoid this extra sort ?
@ulysses-you WDYH
What changes were proposed in this pull request?
A shuffle block is considered as skewed and will be accurately recorded in HighlyCompressedMapStatus if its size if larger than this factor multiplying the median shuffle block size.
Before this change
After this change
Why are the changes needed?
Now map task will report accurate shuffle block size if the block size is greater than "spark.shuffle.accurateBlockThreshold"( 100M by default ). But if there are a large number of map tasks and the shuffle block sizes of these tasks are smaller than "spark.shuffle.accurateBlockThreshold", there may be unrecognized data skew.
For example, there are 10000 map task and 10000 reduce task, and each map task create 50M shuffle blocks for reduce 0, and 10K shuffle blocks for the left reduce tasks, reduce 0 is data skew, but the stat of this plan do not have this information.
Does this PR introduce any user-facing change?
No
How was this patch tested?
Update exists UTs