[SPARK-37488][CORE] When TaskLocation is HDFSCacheTaskLocation or HostTaskLocation, check if executor is alive on the host#34743
Conversation
TaskLocalitygetAllowedLocalityLevel may be getting the wrong TaskLocality
|
Can one of the admins verify this patch? |
getAllowedLocalityLevel may be getting the wrong TaskLocalitygetAllowedLocalityLevel may be getting the wrong TaskLocality
getAllowedLocalityLevel may be getting the wrong TaskLocalitygetAllowedLocalityLevel may be getting the wrong TaskLocality
006e1e8 to
3dc018e
Compare
…executor is alive on the host
6b3d2d2 to
8b1a632
Compare
getAllowedLocalityLevel may be getting the wrong TaskLocalityTaskLocation is HDFSCacheTaskLocation or HostTaskLocation, check if executor is alive on the host
core/src/test/scala/org/apache/spark/scheduler/TaskSetManagerSuite.scala
Outdated
Show resolved
Hide resolved
| // to ensure that the taskScheduler already has the relevant executor alive, otherwise | ||
| // we will not pending the task to forHost if the HostTaskLocation level task does not find | ||
| // a live executor for the host, which defeats the purpose of this test | ||
| taskScheduler.resourceOffers(offers).flatten |
There was a problem hiding this comment.
I modified the existing test because it also needs to be done when the executor is ready, and because of this pr change HostTaskLocation does not pending at the forHost level without checking for a live executor
So I call resourceOffers(offers) first before submitting the task
|
Gentle ping @dongjoon-hyun, Can you help review this pr ? : ) |
| ", but there are no executors alive there.") | ||
| } | ||
| } | ||
| pendingTaskSetToAddTo.forHost.getOrElseUpdate(loc.host, new ArrayBuffer) += index |
There was a problem hiding this comment.
Irrespective of whether we have an executor on a host or not, we should update.
An executor could be added later on to that host.
There was a problem hiding this comment.
@mridulm Thank you for your review.
I recognize the downside of doing this, causing many possibilities to fail that could be accelerated with a little waiting.
The trouble for me is that the host doesn't have a woker or NodeManager, so it can never start an executor on the corresponding host machine. Also the getAllowedLocalityLevel method prevents the task from trying to go farther locally. The task can never be actually executed.
Based on this, I have two options in mind
-
can we implement a new task locality, e.g.
HDFSDiskCacheTaskLocationinstead ofHostTaskLocationhere.
Then only the executor alive determination will be done for this case.
spark/core/src/main/scala/org/apache/spark/rdd/HadoopRDD.scala
Lines 456 to 460 in ffe3fc9
-
or modify the implementation of
getAllowedLocalityLevelto allow farther locality with limited attempts
There was a problem hiding this comment.
Two things:
a) The host might not have a worker right now - but that can change as the application executes, and either new executors are added (dynamic resource allocation) or if executors fail.
b) computeValidLocalityLevels will readjust the valid locality levels based on what scheduler knows about.
I am not sure what you mean by "task can never be actually executed".
Please take a look at getAllowedLocalityLevel on how locality level is computed.
A task will always be added to all tasks - and also to some rack typically: so it will always get executed, though might be slightly delayed if other tasks for the stage can have better schedule possible
There was a problem hiding this comment.
I'm sorry I may not have expressed the situation I encountered clearly
Please Take a look at this example: It query a hive partition.
dataset.persist(StorageLevel.MEMORY_AND_DISK()) is an important statement that makes the task accompanied by a preferred locations.
// The online environment is actually hive partition data imported to tidb, the code logic can be simplified as follows
SparkSession testApp = SparkSession.builder()
.master("local[*]")
.appName("test app")
.enableHiveSupport()
.getOrCreate();
Dataset<Row> dataset = testApp.sql("select * from default.test where dt = '20211129'");
dataset.persist(StorageLevel.MEMORY_AND_DISK());
dataset.count();Here is the forHost of my hook runtime
forHost=@HashMap[
serialVersionUID=@Long[1],
_loadFactor=@Integer[750],
table=@HashEntry[][
@DefaultEntry[(kv: hdfs-loc-1, ArrayBuffer(2, 1))],
null,
null,
null,
null,
null,
null,
null,
null,
@DefaultEntry[(kv: driver-host, ArrayBuffer())],
null,
null,
null,
null,
@DefaultEntry[(kv: hdfs-loc-2, ArrayBuffer(2, 1))],
@DefaultEntry[(kv: hdfs-loc-3, ArrayBuffer(2, 1))],
],
Task 1, 2 preferred location is HostTaskLocation , pointing to hdfs-loc-1, hdfs-loc-2, hdfs-loc-3
But these three hosts are hdfs data blocks where the machine, these three machines do not exist spark worker, there is no nodeManager. getAllowedLocalityLevel will only return NODE_LOCAL in this case(All resources are attempted at the NODE_LOCAL before the localityWait time runs out). So "task can never be actually executed".
There was a problem hiding this comment.
Couple of things:
a) Tasks expressing preferred locality does not necessarily mean spark will wait at that preferred level. Take a look at computeValidLocalityLevels.
In your case, if scheduler is waiting for NODE_LOCAL schedules, then it means there is some executor which is alive on some host which is preferred.
b) If a task is not run at one level, it would at the next level - after a modest delay which is configurable.
It does not result in task never getting executed.
There was a problem hiding this comment.
Update:
@DefaultEntry[(kv: driver-host, ArrayBuffer())], indeed Task 0 assigned to driver-host has finished execution based on NODE_LOCAL, but Task 1, 2 are still pending
@mridulm, thanks for the detailed answer, I currently avoid task pending by setting spark.locality.wait.node to 0. In fact a permanent pending is possible, if there are not many resources, spark.locality.wait.node defaults to 3s, and all remaining resources are tried within this time range, then there is no chance to get to the next TaskLocality, although computeValidLocalityLevels returns [ PROCESS_LOCAL, NODE_LOCAL, ANY].
While setting spark.locality.wait.node to 0 eased my production environment's trouble, I think it would be better to treat the TaskLocation special in this case, as the current code also treats the HDFSCacheTaskLocation special
spark/core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala
Lines 262 to 272 in 030de1d
There was a problem hiding this comment.
b) If a task is not run at one level, it would at the next level - after a modest delay which is configurable.
It does not result in task never getting executed.
Add some spark ui screenshots, I reproduce the situation, The task is very light, 100,000 rows of data computing count
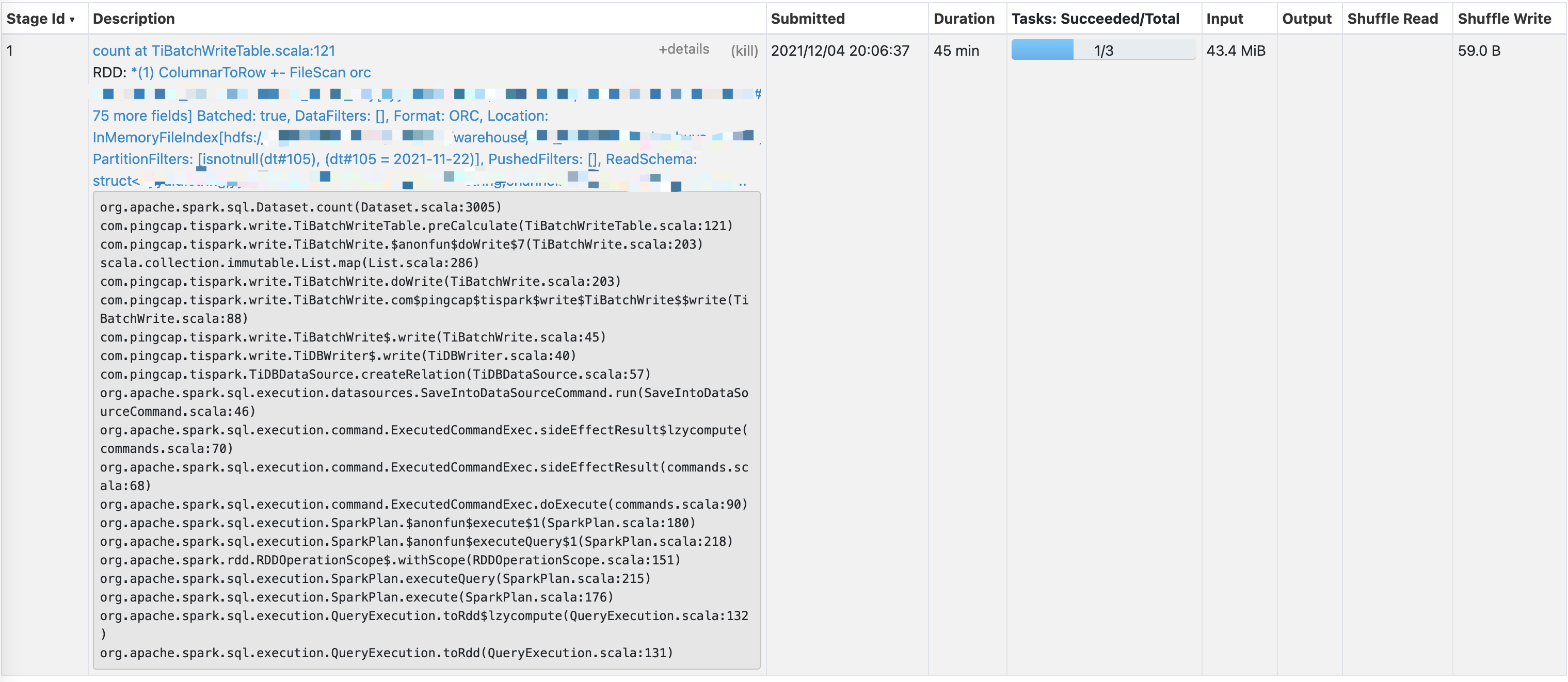

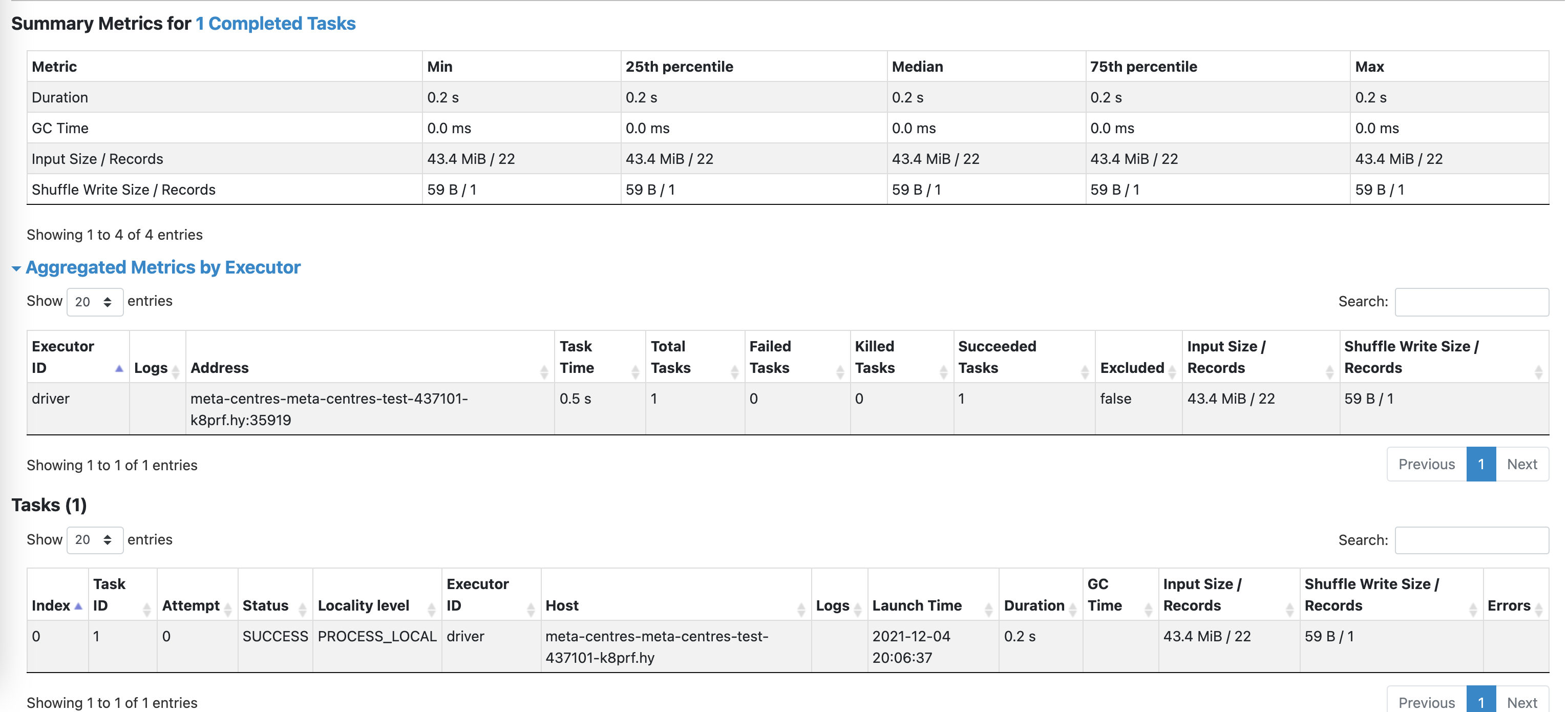
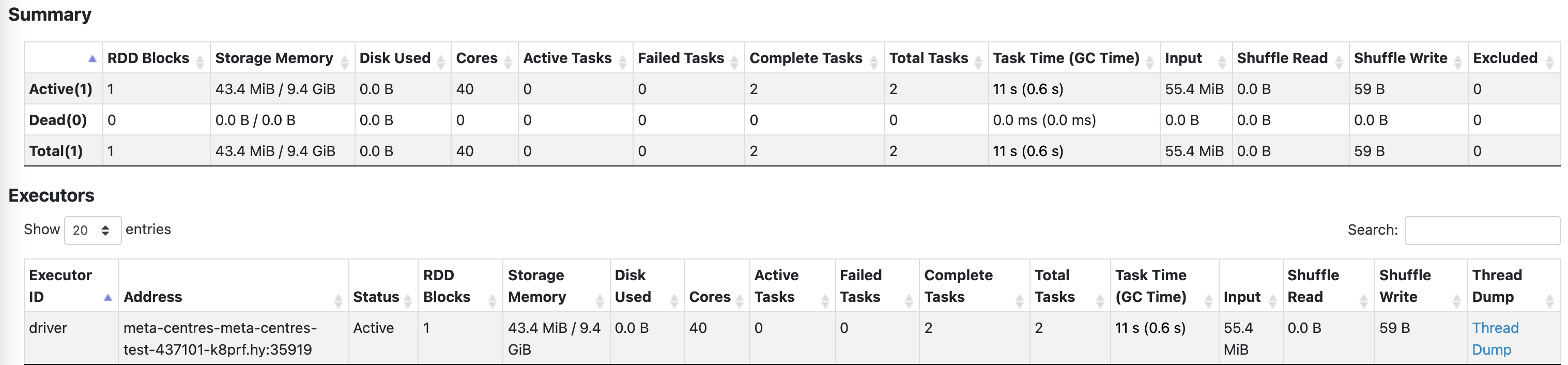
There was a problem hiding this comment.
In fact a permanent pending is possible, if there are not many resources, spark.locality.wait.node defaults to 3s, and all remaining resources are tried within this time range, then there is no chance to get to the next TaskLocality, although computeValidLocalityLevels returns [ PROCESS_LOCAL, NODE_LOCAL, ANY].
I am confused about this statement - if there are no resources available, no tasks can be scheduled and so spark will wait indefinitely.
If/when there are resources available, scheduler will move to the next locality level once the previous level times out.
I think it would be better to treat the TaskLocation special in this case, as the current code also treats the HDFSCacheTaskLocation special
Current behavior of HDFSCacheTaskLocation is:
a) If there are executors on the host, add to forExecutor
b) Add to forHost
(b) is done for all tasks which have locality preference.
As and when a new executor is added or an existing executor is removed, computeValidLocalityLevels iterates through the various for<LEVEL> to identify if there are executors available on that LEVEL to determine whether to keep the level for schedule.
What is proposed in the PR will break computeValidLocalityLevels - since addition of a new executor will not add host level schedule.
If the issue we are attempting to solve is:
"for the current pending tasks, with the executor resources available to the application, disregard a locality level if there are no valid candidates for that level"
If yes, the current PR is not solving this issue - though this is a good problem to address in the scheduler.
I do agree, setting wait time to 0 just to mitigate this issue is indeed suboptimal.
We will have to look at the cost/benefit of doing that based on the proposal which fixes this issue - since I suspect the costs would not be very cheap (the various materialized datastructures in scheduler are to keep the costs as low as possible).
Hope that clarifies.
There was a problem hiding this comment.
Yes, I totally agree with you and after discussing with you I realized that this pr just solves my special case and breaks other cases.
The reason I haven't closed this pr yet is because I still want to find a way to fix this situation with minimal modifications, while not affecting other scenarios that are already working well.
@mridulm, thank you for spending a lot of time discussing this and giving me new insight into spark scheduling as well.
Codecov Report
@@ Coverage Diff @@
## master #34743 +/- ##
==========================================
+ Coverage 90.11% 90.55% +0.43%
==========================================
Files 292 294 +2
Lines 62785 62656 -129
Branches 9902 9857 -45
==========================================
+ Hits 56580 56737 +157
+ Misses 4825 4604 -221
+ Partials 1380 1315 -65
Flags with carried forward coverage won't be shown. Click here to find out more.
Continue to review full report at Codecov.
|

|
Thank you for pinging me, @guiyanakuang . :) |
|
I'll close this pr because this implementation doesn't solve the issue perfectly, and I don't have a better idea right now. Thanks to @mridulm and @dongjoon-hyun for the review |
|
Thank you for closing, @guiyanakuang . |
I have observed that tasks are permanently pending and reruns can always be reproduced.
Since it is only reproducible online, I use the arthas runtime to see the status of the function entries and returns within the
TaskSetManager.I replaced the real host to avoid revealing company information
https://gist.github.com/guiyanakuang/431584f191645513552a937d16ae8fbd
NODE_LOCALlevel, because the persist function is called, the pendingTasks.forHost has a collection of pending tasks, but it points to the machine where the block of partitioned data is located, and since the only resource spark gets is the driver.Here is the forHost information I got through the arthas hook
When we can only provide driver resources, getAllowedLocalityLevel limits the attempt level to NODE_LOCAL. But in reality, the task cannot run at this level, and the attempt level cannot reach ANY
What changes were proposed in this pull request?
To solve the above mentioned problem, this pr modifies the initialization logic of
forHost.When
TaskLocationisHDFSCacheTaskLocationorHostTaskLocation, check if executor is alive on the host.Why are the changes needed?
In my online environment it may cause the task to pending permanently, this pr aims to fix this issue.
Does this PR introduce any user-facing change?
No
How was this patch tested?
Add unit test