[STORM-3112] Incremental scheduling supports#2723
[STORM-3112] Incremental scheduling supports#2723danny0405 wants to merge 4 commits intoapache:masterfrom
Conversation
|
@revans2 @HeartSaVioR |
|
@danny0405 There is a lot of code here and I am trying to understand what exactly this is doing, because it is hard to get it from just the code. I can see the extra caching that you put in for the StormBase, which looks great. The JIRA says that we are only scheduling topologies that need to be scheduled, but I see that you had to change the isolation scheduler to disable that feature. What exactly are the differences that the scheduler sees. I am also a little confused about how this, besides the caching, improves performance. All of the schedulers will loop through the list of topologies and only schedule the ones that need to be scheduled. It is a tiny check that takes a few ms at the most. |
|
Then the reasons why this patch can improve performance:
The reason why IsolationScheduler need a full scheduling:
|
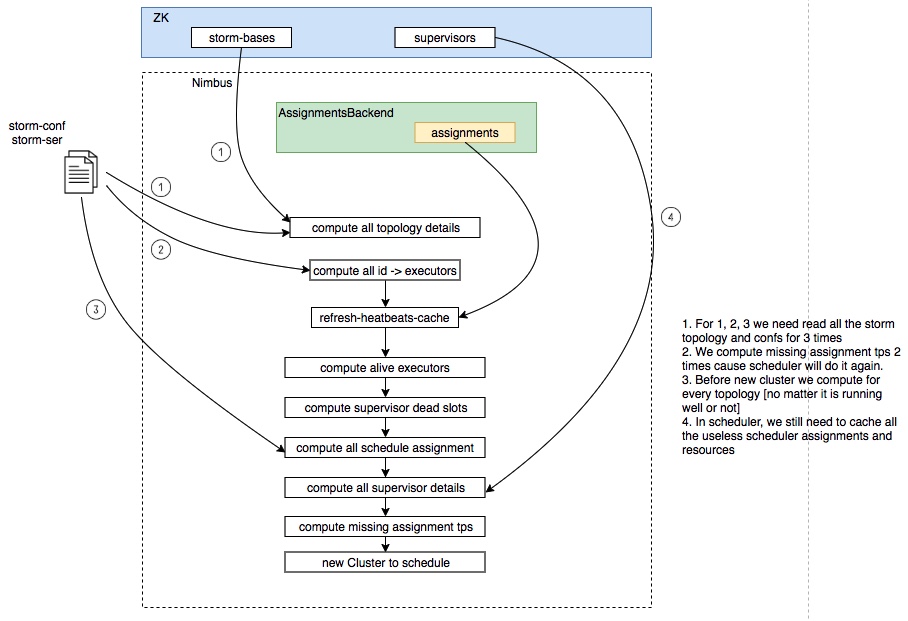
|
@danny0405 |
|
@HeartSaVioR @revans2 Could you have a benchmark test for this patch ? I will very appreciate for it. |
|
@danny0405 Unfortunately I also can't run a large cluster. I could run Storm in 3~4 VM nodes but I think the patch will not address such small cluster. I'll take a look at design difference and comment sooner. |
|
@danny0405 |
|
@HeartSaVioR |
|
@danny0405 |
|
@danny0405 I have spent some time looking at your patch, I have not found any issues with the code itself, but I easily could have missed something. My biggest problems is that I just cannot get past the backwards incompatibility imposed by NeedsFullTopologiesScheduler. I also don't want to merge in a performance improvement without any actual numbers to back it up. To get the performance numbers, you really only want to know how long it takes to schedule. You don't actually need to run a full cluster. The simplest way to make that happen is to fake out the heartbeats for the supervisors and the workers. You could do it as a stand alone application, but it might be nice to have a bit more control over it so you can simulate workers that don't come up, or workers that crash. Once you have that working I really would like to see a breakdown of how much time is being spent computing the different parts that go into creating the new Cluster. As for NeedsFullTopologiesScheduler would either like to see this switched so schedulers opt into getting less information, or even better have us cache the fully computed inputs to Cluster and just update the cache incrementally instead of leaving things out. |
|
@revans2 As for NeedsFullTopologiesScheduler, i agree to remove it. We can tweak the IsolationScheduler or cache topologies data, either is ok. But i am inclined to choose the first one, cause we do not have a powerful reliable cache for master now, everything we cached will need to have a recover strategy, too many cache will make this things a little mess. For the first chose, i think more work will be done for refactoring the code, I will fire a another JIRA to solve this problem. For this patch, it is enough for us. |
|
@revans2 @HeartSaVioR |
|
@danny0405 I'd say showing the numbers is more powerful for persuading than let others dive to the code and find value, especially the patch is not addressing Storm's performance issues what we already know about. STORM-2693 addressed our long-lived issue, so that was less needed to persuade others but this doesn't look like the case. |
|
I'd like to say it doesn't mean I don't plan to review this. I'd rather say other issues which are directly coupled with releases (mostly Storm 2.0.0) should be reviewed prior to this, unless you show interesting numbers to let us want to include this to Storm 2.0.0. |
|
@revans2 |
|
@srdo @revans2 @HeartSaVioR Can you please review this for me ? It's so long time since the patch we proposed, i will very appreciate it if you can review this patch. |
What is this patch for
Incremental scheduling supports.
As STORM-3093 described, now the scheduling work for a round is a complete scan and computation for all the topologies on cluster, which is a very heavy work when topologies increment to hundreds.
So this patch is to refactor the scheduling logic that only care about topologies that need to.
Promotions List
Cause in STORM-3093 i already cache the storm-id -> executors mapping, now for a scheduling round, things we will do:
About Robustness When Nimbus Restarts
The New Scheduling mode
Test data
This is the one incremental topology scheduling time cost data produced by LargeAmountsOfTopologiesSchedulingTest.java, i also add in a ISchedulerTracer if you wanna more specific time cost data during scheduling.
Need to emphasize that this data is already promoted by removing storm-bases accessing time and re-computing of id->executors mapping compared to old scheduling mode, but we can still see
a remarkable promotion and very good performance for this new scheduling mode.
We can see that incremental scheduling is very lightweight and fast.
JIRA: STORM-3112.