- Introduction
- Application Web
- Configuration de la base
- Schema de la base
- Nos differentes requetes
- Resultat des tests
- Installation de l'application
- Conclusion
Le projet vise à simuler une application de réseau social permettant aux utilisateurs de suivre d'autres utilisateurs et d'acheter des produits en ligne. La base de données est conçue pour gérer un million d'utilisateurs, 10 000 références de produits et les relations entre eux. Le projet utilise deux technologies dans un but de comparaison de base de données différentes: une base de données NoSQL (Neo4J) et une base de données relationnelle (MariaDB).
Les utilisateurs peuvent suivre d'autres utilisateurs de manière orientée, et chaque utilisateur peut avoir jusqu'à 20 followers. Les achats des utilisateurs sont enregistrés dans la base de données, avec chaque utilisateur pouvant acheter jusqu'à 5 produits parmi les 10 000 références de produits disponibles. Des requêtes sont fournies pour obtenir des informations sur les commandes et les followers, permettant de découvrir les produits les plus populaires dans les cercles de followers d'un utilisateur donné.
Tous ces test ont pour but de savoir quel est le modèle de base de données le plus efficace et dans quelle disposition ?
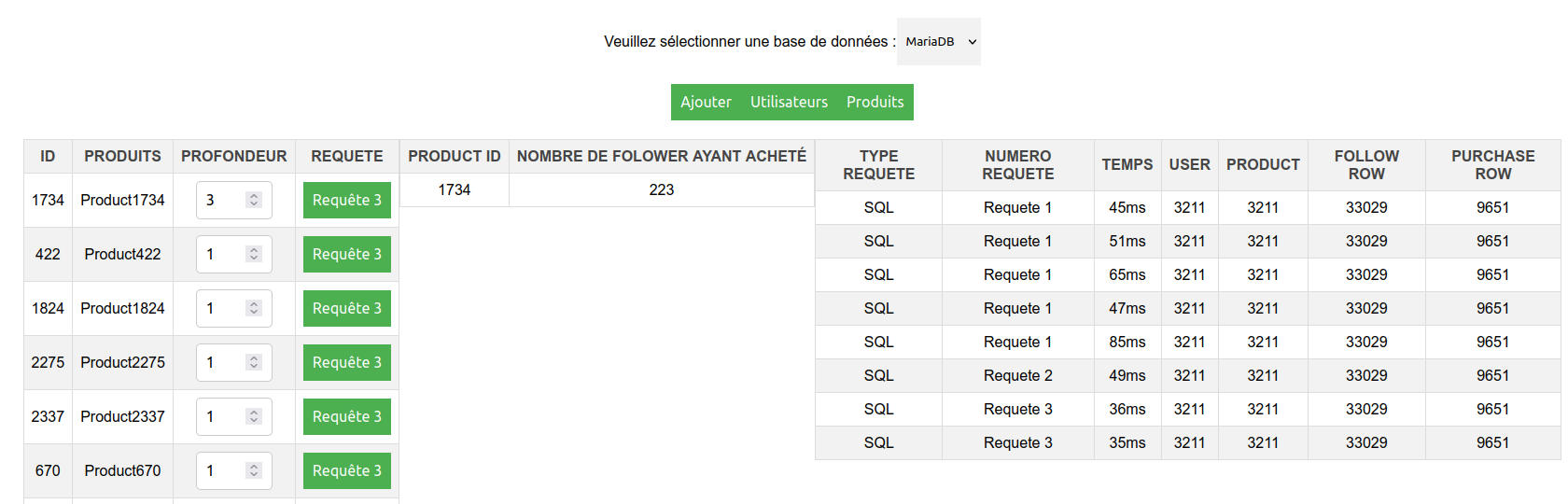
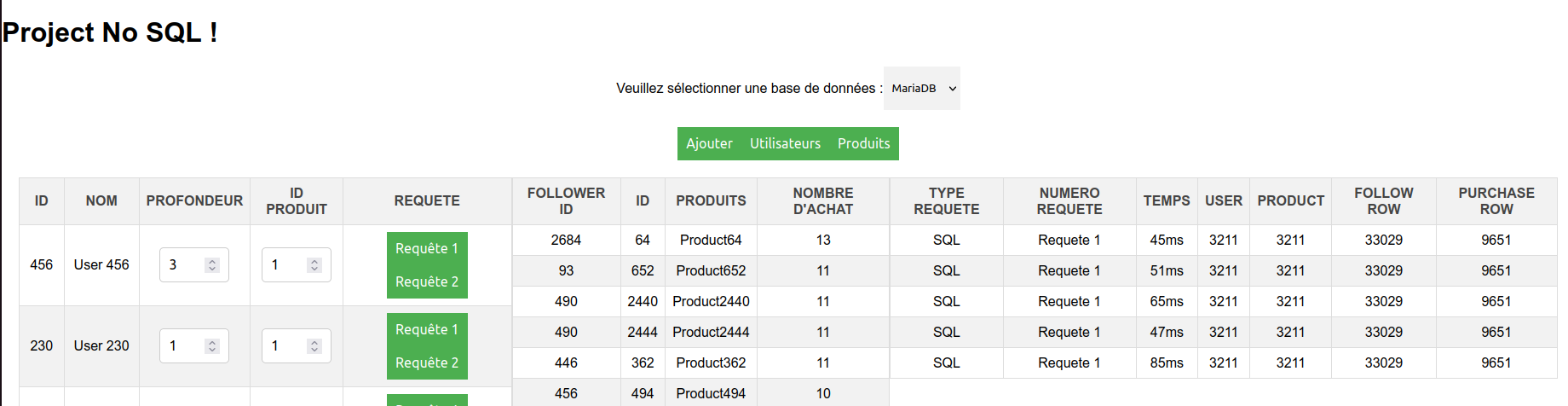
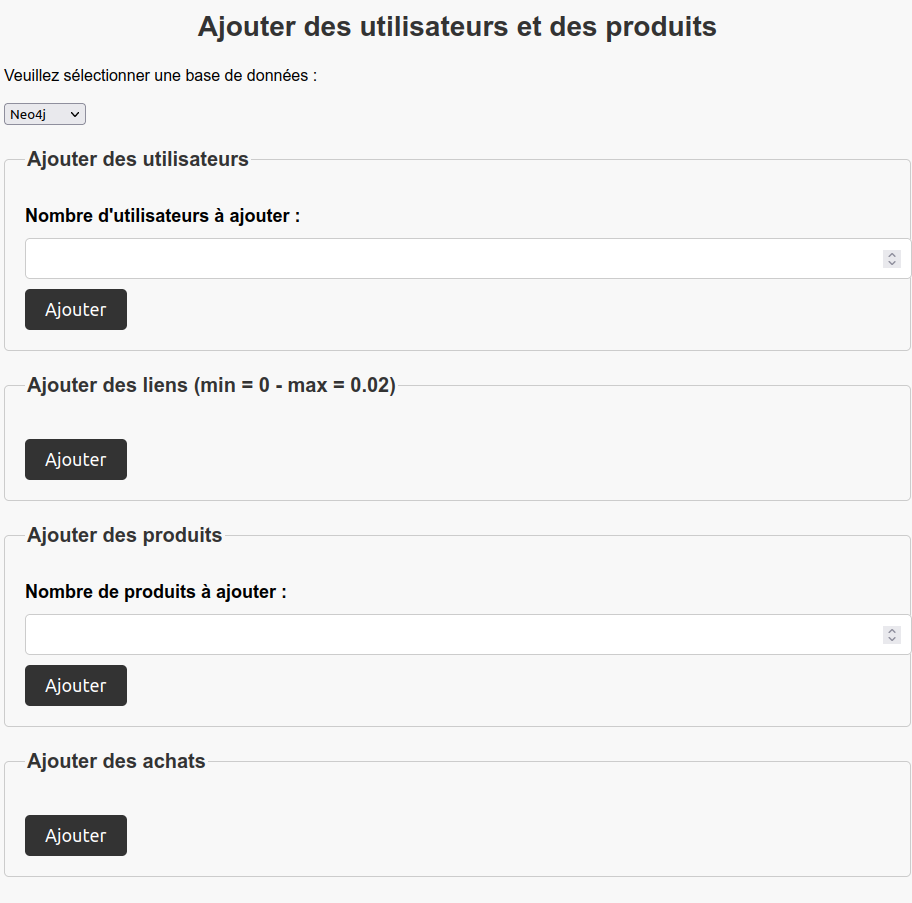
Cette web application permet de tester des requêtes sur différentes bases de données à travers une interface utilisateur simple et intuitive, elle donne le temps d'exécution de chaque requête. Elle est codée en HTML, CSS et JavaScript, ce qui la rend facilement accessible et modifiable. L'application est conçue pour fournir des résultats précis et clairs pour chaque requête exécutée, en offrant également une option pour remplir facilement les bases avec une interface intuitive. Grâce à cette application, les utilisateurs peuvent tester rapidement et efficacement leurs requêtes sur différentes bases de données, ce qui permet de faire un comparatif rapide entre les 2 technologies de bases de données.
Modifier le fichier mycnf.conf
innodb_buffer_pool_size = 1G
Cela permet d'augmenter la charge maximale et permettra d'injecter plus de données sans être limité par les tampons de sécurité de MariaDB

Les fichiers RequetesSQL et CreationCypher.cyp regroupe nos differentes commandes et requetes effectué pour la gestion des base de données. Cependant nous allons expliqué dans ce paragraphe le fonctionnement des differentes requetes.
CREATE OR REPLACE PROCEDURE add_random_followers_to_user()
BEGIN
DECLARE max_users INT;
DECLARE num_followers INT;
DECLARE user_id INT DEFAULT 1;
DECLARE i INT DEFAULT 1;
DECLARE rand_num INT;
SELECT COUNT(*) INTO max_users FROM Users;
WHILE user_id <= max_users DO
SELECT COUNT(*) INTO num_followers FROM Follows WHERE follower_id = user_id;
IF num_followers = 0 THEN
SET i = 0;
SET num_followers = FLOOR(RAND() * 20);
WHILE i <= num_followers DO
SET rand_num = FLOOR(RAND() * max_users);
INSERT INTO Follows (follower_id, followee_id, follow_date)
VALUES (user_id, rand_num+1, NOW());
SET i = i + 1;
END WHILE;
END IF;
SET user_id = user_id + 1;
END WHILE;
END;
Dans cette procedure nous parcourons tous les utilisateurs n'ayant pas de follower afin de leur ajouter un nombre entre 1 et 20. Ce nombre est choisi aleatoirement avec la fonction FLOOR(RAND() * 20). Ensuite nous effectuons une boucle jusqu'a atteindre le nombre de followers données et choisant de maniere aleatoire un user_id a follow.
CREATE OR REPLACE PROCEDURE add_random_product_to_user()
BEGIN
DECLARE max_users INT;
DECLARE max_product INT;
DECLARE num_product INT;
DECLARE user_id INT DEFAULT 1;
DECLARE i INT DEFAULT 1;
DECLARE rand_num INT;
SELECT COUNT(*) INTO max_users FROM Users;
SELECT COUNT(*) INTO max_product FROM Products;
WHILE user_id <= max_users DO
SELECT COUNT(*) INTO num_product FROM Purchases p WHERE p.user_id = user_id;
IF num_product = 0 THEN
SET i = 0;
SET num_product = FLOOR(RAND() * 5);
WHILE i <= num_product DO
SET rand_num = FLOOR(RAND() * max_product);
INSERT INTO Purchases (user_id, product_id, purchase_date)
VALUES (user_id, rand_num+1, NOW());
SET i = i + 1;
END WHILE;
END IF;
SET user_id = user_id + 1;
END WHILE;
END;
La fonction d'ajout de relation d'achat fonctionne sensiblement de la meme maniere que la précédante.
MATCH (u:User)
WHERE NOT (u)-[:FOLLOWS]->()
WITH u, RAND() AS random_number
ORDER BY random_number
WITH u, toInteger(RAND() * 21) AS num_followers
WHERE num_followers > 0
WITH u, num_followers
MATCH (other_user:User)
WHERE other_user <> u
WITH u, num_followers, collect(other_user) AS other_users
WITH u, num_followers, other_users[0..num_followers-1] AS selected_users
UNWIND selected_users AS follower
CREATE (u)-[:FOLLOWS]->(follower)
Cette requete fonctionne de maniere differente. Elle parcours toute les users grace au premier MATCH (u:User), elle selectionne un nombre entre 0 et 20 grace à la fonction RAND(). Puis selectionne crée une liste d'autre user tant que la liste n'a pas atteint la taille de nombre de follow. Une fois la liste rempli elle crée de maniere récurisive grace a UNWIND les liens entre le premier User et les followers.
MATCH (u:User)
WHERE NOT (u)-[:PURCHASED]->()
WITH u, toInteger(RAND() * 6) AS num_purchased
WHERE num_purchased > 0
WITH u, num_purchased
MATCH (p:Product)
WITH u,p,num_purchased, RAND() AS random_number
ORDER BY random_number
WITH u, num_purchased, collect(p) AS products_purchased
WITH u, num_purchased, products_purchased[0..num_purchased-1] AS selected_product
UNWIND selected_product AS product
CREATE (u)-[:PURCHASED]->(product)
La requete pour les achats fonctionne de la meme facon, le seul point changeant est que nous mettons un ordre aleatoire sur les produits afin d'eviter d'acheter les premiers produits à chaque fois
WITH RECURSIVE followers(follower_id, followee_id, level) AS (
SELECT follower_id, followee_id, 1 FROM Follows WHERE follower_id = $Follower_ID UNION
SELECT f.follower_id, f.followee_id, level + 1
FROM Follows f
JOIN followers ON f.follower_id = followers.followee_id
WHERE level < $LEVEL)
SELECT f.follower_id , p.product_id, p.product_name, COUNT(*) as num_purchases
FROM followers f
JOIN Purchases pur ON f.followee_id = pur.user_id
JOIN Products p ON pur.product_id = p.product_id
GROUP BY p.product_id, p.product_name
ORDER BY num_purchases DESC;
Cette requête SQL utilise une requête récursive (WITH RECURSIVE) pour récupérer les utilisateurs qui suivent directement ou indirectement un certain utilisateur identifié par $Follower_ID. La profondeur maximale de la recherche est limitée par la variable $LEVEL.
La requête récursive commence par sélectionner toutes les entrées dans la table "Follows" où le "follower_id" est égal à $Follower_ID et en assignant un niveau initial de 1. Ensuite, la requête se poursuit en sélectionnant toutes les entrées dans "Follows" où le "follower_id" correspond à l'"followee_id" de l'étape précédente, en augmentant le niveau de 1. Ce processus continue jusqu'à ce que le niveau maximal spécifié par $LEVEL soit atteint.
Ensuite, la requête joint les résultats de la table "followers" avec les tables "Purchases" et "Products" pour récupérer les produits achetés par les utilisateurs qui suivent le "follower" identifié dans la requête récursive. Le résultat final affiche le "follower_id", l'"product_id", le "product_name" et le nombre d'achats ("num_purchases") pour chaque produit, trié par ordre décroissant du nombre d'achats.
MATCH (u:User {user_id:1})-[:FOLLOWS*0..1]->(f:User)-[:PURCHASED]->(p:Product)
RETURN p.product_name, COUNT(DISTINCT f) AS nombre_de_followers, COUNT(*) AS nombre_de_commandes
ORDER BY nombre_de_followers DESC
La requête commence en sélectionnant le nœud "User" avec l'identifiant "1" et en cherchant tous les nœuds "User" qui sont suivis par le nœud "User" sélectionné, avec une distance de 0 ou 1 relation de suivi ("FOLLOWS*0..1"). Ces nœuds suivis sont représentés par la variable "f".
Ensuite, la requête joint les nœuds "f" avec les nœuds "p" qui ont été achetés par les utilisateurs suivis ("f") via la relation "PURCHASED". La requête utilise la variable "p" pour représenter ces nœuds "Product".
Enfin, la requête retourne le nom du produit ("p.product_name"), le nombre de followers distincts qui ont acheté ce produit ("COUNT(DISTINCT f) AS nombre_de_followers"), et le nombre total de commandes pour ce produit ("COUNT(*) AS nombre_de_commandes"). Les résultats sont triés par ordre décroissant du nombre de followers distincts ("ORDER BY nombre_de_followers DESC").
WITH RECURSIVE followers(follower_id, followee_id, level) AS (
SELECT follower_id, followee_id, 1 FROM Follows WHERE follower_id = $Follower_ID
UNION
SELECT f.follower_id, f.followee_id, level + 1
FROM Follows f
JOIN followers ON f.follower_id = followers.followee_id
WHERE level < $LEVEL
)
SELECT f.follower_id , p.product_id, p.product_name, COUNT(*) as num_purchases
FROM followers f
JOIN Purchases pur ON f.followee_id = pur.user_id
JOIN Products p ON pur.product_id = p.product_id
WHERE p.product_name= $Product_Name
ORDER BY f.follower_id;
Cette requête SQL est similaire à la première, mais elle ajoute une clause WHERE pour filtrer les résultats par nom de produit spécifique.
MATCH (u:User {user_id:$USER})-[:FOLLOWS*0..$LEVEL]->(f:User)-[:PURCHASED]->(p:Product {product_id: $PRODUCT})
RETURN COUNT(DISTINCT f) AS nombre_de_followers, COUNT(*) AS nombre_de_commandes
Cette requête Cypher est similaire à la première, mais elle ajoute une clause pour filtrer les résultats en fonction de l'id
SELECT COUNT(DISTINCT f.followee_id) AS num_followees
FROM Users u
INNER JOIN (
WITH RECURSIVE followers(follower_id, followee_id, level) AS (
SELECT follower_id, followee_id, 1 FROM Follows WHERE followee_id IN (
SELECT user_id FROM Purchases WHERE product_id = $PRODUCT_ID
)
UNION
SELECT f.follower_id, f.followee_id, level + 1
FROM Follows f
JOIN followers ON f.follower_id = followers.followee_id
WHERE level < $LEVEL
)
SELECT followee_id FROM followers
) AS f ON u.user_id = f.followee_id;
La requête commence en sélectionnant les utilisateurs de la table "Users" ("FROM Users u").
Ensuite, la requête utilise une sous-requête (WITH RECURSIVE) pour récupérer les utilisateurs qui suivent directement ou indirectement les utilisateurs qui ont acheté le produit spécifié dans la table "Purchases".
Plus précisément, la sous-requête utilise une requête récursive pour récupérer tous les followers pour chaque utilisateur ayant acheté le produit spécifié, jusqu'à un certain niveau de profondeur ("$LEVEL"). La première partie de la requête récursive récupère les followers directs pour chaque utilisateur ayant acheté le produit spécifié ("SELECT follower_id, followee_id, 1 FROM Follows WHERE followee_id IN (...)"). La deuxième partie de la requête récursive récupère les followers des followers précédemment identifiés, jusqu'à la profondeur spécifiée par "$LEVEL" ("SELECT f.follower_id, f.followee_id, level + 1 FROM Follows f JOIN followers ON f.follower_id = followers.followee_id WHERE level < $LEVEL").
Enfin, la requête principale joint les résultats de la sous-requête avec la table "Users" pour compter le nombre d'utilisateurs qui suivent au moins un utilisateur identifié dans la sous-requête ("COUNT(DISTINCT f.followee_id) AS num_followees").
MATCH (p:Product {product_id: $PRODUCT})<-[:PURCHASED]-(u:User)
MATCH (u)-[:FOLLOWS*$LEVEL]->(f:User)
MATCH (f)-[:PURCHASED]->(p)
RETURN COUNT(DISTINCT f) AS nombre_de_followers, COUNT(*) AS nombre_de_commandes
La requête commence en trouvant tous les utilisateurs qui ont acheté le produit spécifié ("MATCH (p:Product {product_id: $PRODUCT})<-[:PURCHASED]-(u:User)").
Ensuite, la requête recherche tous les followers des utilisateurs trouvés précédemment jusqu'à un certain niveau de profondeur ("MATCH (u)-[:FOLLOWS*$LEVEL]->(f:User)").
Enfin, la requête trouve tous les produits achetés par les followers identifiés dans la requête précédente ("MATCH (f)-[:PURCHASED]->(p)").
Ces petits tableaux résument le temps d'éxecution de chacune des requêtes pour chacune des technologies mises sous haute volumétrie.
| Base de données | Users | Products | Purchases | Follows |
|---|---|---|---|---|
| MariaDB | 0.014 sc | 0.010 sc | 0.016 sc | 0.013 sc |
| NoSQL | NA sc | NA sc | NA sc | NA sc |
| Base de données | Users | Products | Purchases | Follows |
|---|---|---|---|---|
| MariaDB | 20 min | 4sc | 4.195 sc | NA (trop long ) |
| NoSQL | 14.23 sc | 13.51 sc | NA sc | NA sc |
| Base de données | Requête 1 | Requête 2 | Requête 3 |
|---|---|---|---|
| NoSQL | 13.02 sc | 12.74 sc | 16.2 sc |
| MariaDB | 14.23 sc | 13.51 sc | 11.3 sc |
MariaDB :
port: 3306, user: "root", password: "root"
NoSQL :
port :7687, user : neo4j, password : neo4j1234
API Node JS, URL de requête:
/requeteNeo4j, /ajoutNeo4j, /ajoutSQL, /requeteSQL
Faire un GitClone dans un répertoire et ensuite utiliser un
npm install
Pour vous connecter à votre base, je vous conseille de modifier le db.js pour correspondre a vos logins
Pour lancer l'application :
npm start
Nous nous sommes contentés du miminum en expérience utilisateur et nous vous recommandons d'ouvrir la console JS de votre navigateur afin d'avoir les messages de validation de vos actions ( ajout d'éléments dans les bases, requête de données, etc...)
Les deux bases de données que nous avons créé sont différentes et ont chacune leurs avantages et leurs inconvénients en fonction des cas d'utilisation:
La base de données NoSQL que nous avons créé est orientée graphe et est donc très utile pour les cas d'utilisation basés sur des graphes, tels que les réseaux sociaux. Elle est très performante pour les requêtes basées sur les relations, avec comme exemples la première et la seconde requête que nous avons écrites. Cependant, elle peut être moins performante pour les requêtes qui nécessitent des jointures complexes sur plusieurs tables.
L' autre base de données utilise un modèle relationnel , elle est optimisée pour les requêtes basées sur des tables. Elle est plus efficace pour les jointures sur plusieurs tables, comme la troisième requête que nous avons écrit, elle implique trois tables différentes. Cependant, elle peut être moins efficace pour les requêtes qui nécessitent de suivre des relations entre les données, comme les requêtes de niveau 1 et 2 que nous avons fait.
En fonction de notre cas d'utilisation, nous pouvons choisir la base de données qui nous convient le mieux. Si vous travaillez principalement avec des données relationnelles et que vous avez besoin d'effectuer des jointures complexes sur plusieurs tables, la base de données relationnelle est la meilleure option. Si vous travaillez principalement avec des données orientées graphe et que vous avez besoin d'effectuer des requêtes basées sur les relations, la base de données NoSQL semble être la meilleure option.
Projet mené par Grégoire Arnoult et Jules Fabre.