![]()
Open-source LLM gateway (OSS edition). One API for every AI provider.
Self-hosted. No vendor lock-in. 14 provider types, 30+ LLM providers supported.
Start routing AI traffic in 60 seconds using any of these deployment methods:
npm install -g iaurora
mkdir my-gateway && cd my-gateway
aurora init # creates config.yaml, .env, data/Option A — via .env file (recommended):
AURORA_MASTER_KEY=your-secure-key
GROQ_API_KEY=gsk_...auroraOption B — via inline env vars (no .env needed):
# Linux / macOS
AURORA_MASTER_KEY=your-secure-key GROQ_API_KEY=gsk_... aurora
# Windows PowerShell
$env:AURORA_MASTER_KEY="your-secure-key"; $env:GROQ_API_KEY="gsk_..."; aurora
# Windows CMD
set AURORA_MASTER_KEY=your-secure-key && set GROQ_API_KEY=gsk_... && auroradocker run -d --name aurora -p 8080:8080 \
-e AURORA_MASTER_KEY="your-secure-key" \
-e GROQ_API_KEY="gsk_..." \
aurorahq/aurorahelm install aurora ./helm \
--namespace aurora --create-namespace \
--set auth.masterKey="your-secure-key" \
--set providers.groq.apiKey="gsk_..." \
--set providers.groq.enabled=true \
--set redis.enabled=falsecurl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(grep AURORA_MASTER_KEY .env | cut -d= -f2)" \
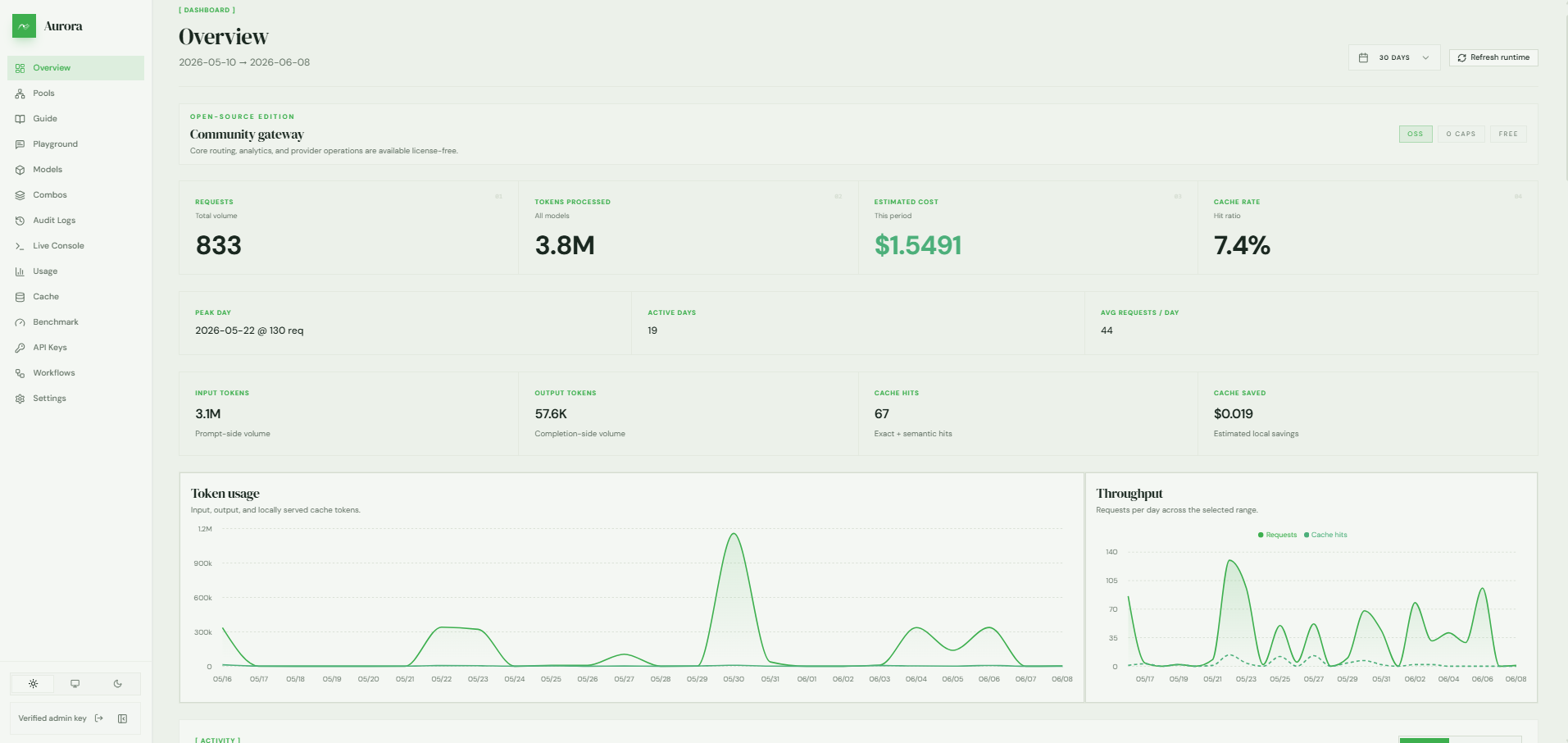
-d '{"model":"groq/llama-3.3-70b-versatile","messages":[{"role":"user","content":"Hello!"}]}'Dashboard: http://localhost:8080/admin/dashboard
Setup guides: npm · Docker · Helm/Kubernetes · Source
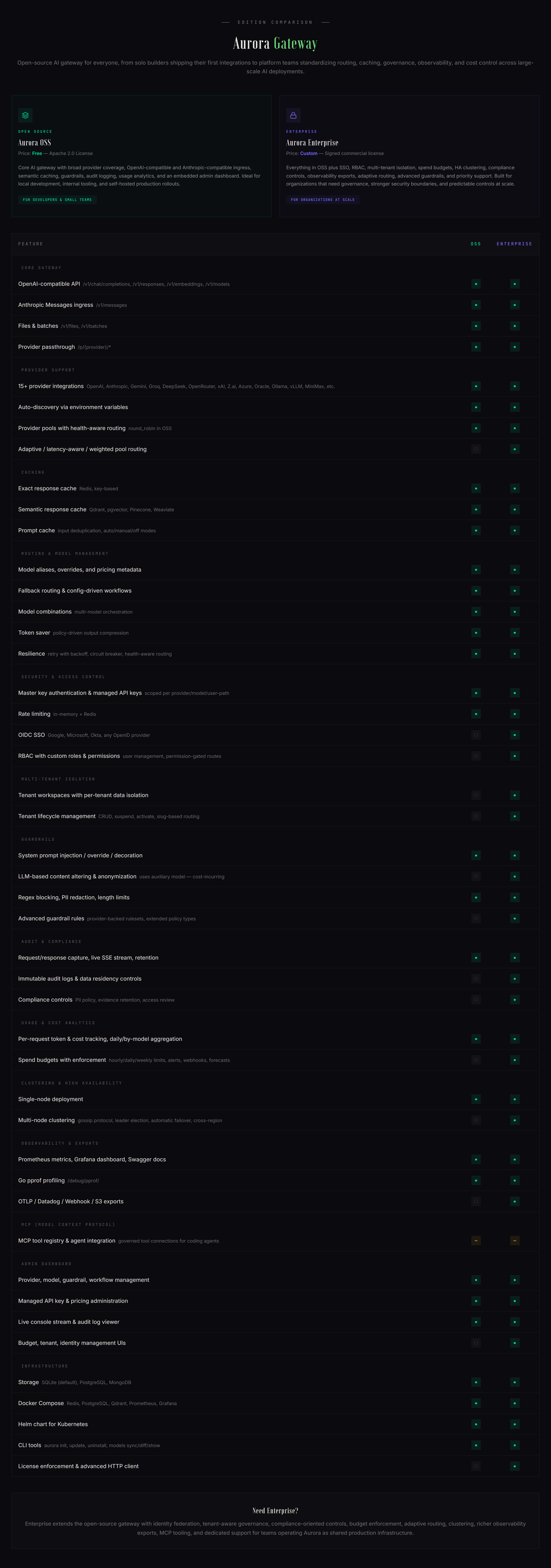
Aurora supports enterprise-grade deployments for teams running production AI systems at scale. In addition to private networking, custom security controls, and governance, Aurora Enterprise unlocks advanced capabilities including SSO, RBAC, tenant isolation, budget enforcement, compliance workflows, and production support.
The Enterprise edition is a separate distribution with a signed license.
Deploy on any Kubernetes cluster with the Helm chart.
# Quick dev — Groq, no Redis, no auth
helm install aurora ./helm \
--namespace aurora --create-namespace \
--set image.tag=1.0.25 \
--set providers.groq.apiKey="gsk_your_key_here" \
--set providers.groq.enabled=true \
--set redis.enabled=false \
--set auth.masterKey=""# Production — multiple providers, auth, Redis
helm upgrade --install aurora ./helm \
--namespace aurora --create-namespace \
--set image.tag=1.0.25 \
--set auth.masterKey="your-secure-key" \
--set providers.openai.apiKey="sk-..." \
--set providers.openai.enabled=true \
--set providers.anthropic.apiKey="sk-ant-..." \
--set providers.anthropic.enabled=true \
--set redis.enabled=trueFull Helm docs: helm/README.md
Providers are auto-discovered from environment variables. Set any provider's _API_KEY and restart — the provider and its default models appear automatically.
Security note for public docs: The env var names listed below are documentation references. Actual secrets go into your
.envfile (in.gitignore) or your deployment secrets manager — never commit them.
| Provider | Env var | Default base URL | Requires base URL | API key required | Default models |
|---|---|---|---|---|---|
| OpenAI | OPENAI_API_KEY |
https://api.openai.com/v1 |
No | Yes | gpt-4o, gpt-4o-mini |
| Anthropic | ANTHROPIC_API_KEY |
https://api.anthropic.com/v1 |
No | Yes | claude-sonnet-4, claude-opus-4 |
| Google Gemini | GEMINI_API_KEY |
https://generativelanguage.googleapis.com/v1beta/openai |
No | Yes | gemini-2.5-pro, gemini-2.5-flash |
| Groq | GROQ_API_KEY |
https://api.groq.com/openai/v1 |
No | Yes | llama-3.3-70b, qwen3-32b, whisper |
| DeepSeek | DEEPSEEK_API_KEY |
https://api.deepseek.com |
No | Yes | deepseek-chat, deepseek-reasoner |
| OpenRouter | OPENROUTER_API_KEY |
https://openrouter.ai/api/v1 |
No | Yes | 300+ models |
| xAI (Grok) | XAI_API_KEY |
https://api.x.ai/v1 |
No | Yes | grok-3, grok-3-mini |
| Z.ai | ZAI_API_KEY |
https://api.z.ai/api/paas/v4 |
No | Yes | glm-4.5 |
| MiniMax | MINIMAX_API_KEY |
https://api.minimax.io/v1 |
No | Yes | minimax-m1 |
| Azure OpenAI | AZURE_API_KEY |
— | Yes | Yes | Your deployments |
| Oracle | ORACLE_API_KEY |
— | Yes | Yes | cohere.command-r-plus |
| Ollama | OLLAMA_API_KEY |
http://localhost:11434/v1 |
No | No (optional) | Any local model |
| vLLM | VLLM_API_KEY |
http://localhost:8000/v1 |
No | No (optional) | Any served model |
| Jina (reranker) | JINA_API_KEY |
— | Yes | Yes | jina-embeddings-v3 |
Every provider supports *_MODELS to override auto-discovered models:
OPENAI_MODELS=gpt-4o,gpt-4o-mini,gpt-4-turboOpenRouter extras:
OPENROUTER_SITE_URL=https://github.com/aurorallm/aurora
OPENROUTER_APP_NAME=Aurora GatewayAzure requires API version:
AZURE_API_VERSION=2024-10-21Override any provider's endpoint:
OPENAI_BASE_URL=https://my-corp-openai-proxy.example.com/v1Use suffix notation (underscores become hyphens in the provider name):
OPENAI_EAST_API_KEY=sk-... # → provider: openai-east
OPENAI_WEST_API_KEY=sk-... # → provider: openai-west
JINA_API_KEY1=... # → provider: jina-1The gateway loads settings in this priority order (later wins):
code defaults → config.yaml → .env / environment variables
Generated by aurora init, every section of config.yaml is documented inline:
| Section | What it controls |
|---|---|
server |
Port, base path, master key, passthrough, Anthropic ingress |
admin |
Dashboard API and UI |
models |
Discovery, overrides, allowlisting |
storage |
SQLite (default), PostgreSQL, or MongoDB |
logging |
Audit logging of requests/responses |
usage |
Token tracking, pricing, retention |
metrics |
Prometheus endpoint |
guardrails |
Content safety filters |
cache |
Model cache, response cache (exact + semantic) |
combos |
Multi-model combo definitions |
token_saver |
Output compression |
fallback |
Provider failover rules |
resilience |
Retry + circuit breaker |
The tables below document every supported env var for reference. In practice you configure these in your
.envfile (CLI deployments),-eflags (Docker), or--setvalues (Helm). Never commit secrets to version control.
Minimal set to get the gateway running:
# ── REQUIRED ──────────────────────────────────────────────
AURORA_MASTER_KEY=replace-with-secure-random-key
# ── AT LEAST ONE PROVIDER ────────────────────────────────
OPENAI_API_KEY=sk-...
# or: GROQ_API_KEY, ANTHROPIC_API_KEY, GEMINI_API_KEY, etc.
# ── OPTIONAL BUT RECOMMENDED ─────────────────────────────
PORT=8080 # Listening port (default: 8080)
STORAGE_TYPE=sqlite # sqlite (default), postgresql, mongodb
LOG_LEVEL=info # debug, info, warn, error
LOG_FORMAT=text # text or jsonEach env var below works in all three deploy modes — here is an example:
| Variable | .env file |
Docker -e flag |
Helm --set value |
|---|---|---|---|
PORT |
PORT=9090 |
-e PORT=9090 |
--set server.port=9090 |
AURORA_MASTER_KEY |
AURORA_MASTER_KEY=... |
-e AURORA_MASTER_KEY=... |
--set auth.masterKey=... |
OPENAI_API_KEY |
OPENAI_API_KEY=sk-... |
-e OPENAI_API_KEY=sk-... |
--set providers.openai.apiKey=... |
STORAGE_TYPE |
STORAGE_TYPE=postgresql |
-e STORAGE_TYPE=postgresql |
--set storage.type=postgresql |
REDIS_URL |
REDIS_URL=redis://... |
-e REDIS_URL=redis://... |
--set cache.redis.url=... |
All configurable environment variables, organized by subsystem:
| Env var | Default | Description |
|---|---|---|
PORT |
8080 |
HTTP listening port |
BASE_PATH |
/ |
URL path prefix to mount under |
AURORA_MASTER_KEY |
"" |
Master API key for auth |
BODY_SIZE_LIMIT |
10M |
Max request body size (e.g. 10M, 1G, 500K) |
SWAGGER_ENABLED |
false |
Enable Swagger UI at /swagger/index.html |
PPROF_ENABLED |
false |
Enable pprof at /debug/pprof/ |
ENABLE_PASSTHROUGH_ROUTES |
true |
Provider-native passthrough at /p/{provider} |
ALLOW_PASSTHROUGH_V1_ALIAS |
true |
Allow /p/{provider}/v1/... alias routes |
ENABLED_PASSTHROUGH_PROVIDERS |
openai,anthropic,openrouter,zai,vllm |
Provider types for passthrough |
ENABLE_ANTHROPIC_INGRESS |
false |
Expose /v1/messages for native Anthropic clients |
DISABLE_REQUEST_LOGGING |
false |
Turn off request logging |
DISABLE_REQUEST_BODY_SNAPSHOT |
false |
Don't snapshot request bodies |
DISABLE_PASSTHROUGH_SEMANTIC_ENRICHMENT |
false |
Disable semantic enrichment on passthrough |
| Env var | Default | Description |
|---|---|---|
HTTP_TIMEOUT |
600 |
Upstream request timeout (seconds) |
HTTP_RESPONSE_HEADER_TIMEOUT |
600 |
Timeout for upstream response headers (seconds) |
HTTP_PROXY |
— | HTTP proxy URL for upstream calls |
HTTPS_PROXY |
— | HTTPS proxy URL |
NO_PROXY |
— | Hosts to exclude from proxy |
| Env var | Default | Description |
|---|---|---|
STORAGE_TYPE |
sqlite |
Backend: sqlite, postgresql, or mongodb |
SQLITE_PATH |
data/aurora-oss.db |
SQLite database file path |
POSTGRES_URL |
— | PostgreSQL connection string |
POSTGRES_MAX_CONNS |
10 |
PostgreSQL connection pool max |
MONGODB_URL |
— | MongoDB connection string |
MONGODB_DATABASE |
aurora |
MongoDB database name |
| Env var | Default | Description |
|---|---|---|
MODEL_LIST_URL |
https://aurorallm.github.io/aurora/assets/models.json |
External model metadata registry (empty = disabled) |
MODEL_LIST_LOCAL_PATH |
data/models.local.json |
Local model registry snapshot path |
MODEL_LIST_USER_OVERRIDES_PATH |
data/user_pricing.yaml |
User pricing override file |
MODELS_ENABLED_BY_DEFAULT |
true |
Default enabled state for provider models |
MODEL_OVERRIDES_ENABLED |
true |
Allow per-model overrides (dashboard editing) |
KEEP_ONLY_ALIASES_AT_MODELS_ENDPOINT |
false |
Hide provider models from GET /v1/models, show only aliases |
CONFIGURED_PROVIDER_MODELS_MODE |
fallback |
fallback or allowlist — how configured model lists affect inventory |
Model cache:
| Env var | Default | Description |
|---|---|---|
CACHE_REFRESH_INTERVAL |
3600 |
Model registry cache refresh (seconds) |
AURORA_CACHE_DIR |
.cache |
Local filesystem cache directory |
REDIS_URL |
— | Redis connection URL (enables Redis-backed model cache) |
REDIS_KEY_MODELS |
aurora:models |
Redis key for model cache |
REDIS_TTL_MODELS |
86400 |
Redis model cache TTL (seconds) |
Response cache (exact match):
| Env var | Default | Description |
|---|---|---|
RESPONSE_CACHE_SIMPLE_ENABLED |
false |
Enable Redis exact-response cache |
REDIS_KEY_RESPONSES |
aurora:response: |
Redis key prefix for responses |
REDIS_TTL_RESPONSES |
3600 |
Response cache TTL (seconds) |
Semantic cache (vector similarity):
| Env var | Default | Description |
|---|---|---|
SEMANTIC_CACHE_ENABLED |
false |
Enable semantic cache |
SEMANTIC_CACHE_THRESHOLD |
0.92 |
Similarity threshold (0-1) |
SEMANTIC_CACHE_PROMPT_SIMILARITY |
0.90 |
Prompt similarity threshold (0-1) |
SEMANTIC_CACHE_TTL |
3600 |
Entry TTL (seconds) |
SEMANTIC_CACHE_MAX_CONV_MESSAGES |
3 |
Recent conversation messages to embed |
SEMANTIC_CACHE_EXCLUDE_SYSTEM_PROMPT |
false |
Exclude system prompt from cache key |
SEMANTIC_CACHE_EMBEDDER_PROVIDER |
openai |
Embedder provider name |
SEMANTIC_CACHE_EMBEDDER_MODEL |
text-embedding-3-small |
Embedder model |
SEMANTIC_CACHE_VECTOR_STORE_TYPE |
qdrant |
Backend: qdrant, pgvector, pinecone, weaviate |
SEMANTIC_CACHE_QDRANT_URL |
http://localhost:6333 |
Qdrant URL |
SEMANTIC_CACHE_QDRANT_COLLECTION |
aurora_semantic |
Qdrant collection name |
SEMANTIC_CACHE_QDRANT_API_KEY |
— | Qdrant API key |
SEMANTIC_CACHE_PGVECTOR_URL |
— | pgvector connection string |
SEMANTIC_CACHE_PGVECTOR_TABLE |
aurora_semantic_cache |
pgvector table name |
SEMANTIC_CACHE_PGVECTOR_DIMENSION |
1536 |
pgvector embedding dimension |
SEMANTIC_CACHE_PINECONE_HOST |
— | Pinecone host URL |
SEMANTIC_CACHE_PINECONE_API_KEY |
— | Pinecone API key |
SEMANTIC_CACHE_PINECONE_NAMESPACE |
— | Pinecone namespace |
SEMANTIC_CACHE_PINECONE_DIMENSION |
1536 |
Pinecone embedding dimension |
SEMANTIC_CACHE_WEAVIATE_URL |
— | Weaviate URL |
SEMANTIC_CACHE_WEAVIATE_CLASS |
AuroraSemanticCache |
Weaviate class name |
SEMANTIC_CACHE_WEAVIATE_API_KEY |
— | Weaviate API key |
| Env var | Default | Description |
|---|---|---|
LOGGING_ENABLED |
false |
Enable audit log to storage |
LOGGING_LOG_BODIES |
true |
Log request/response bodies (may contain PII) |
LOGGING_LOG_HEADERS |
true |
Log headers (sensitive headers redacted) |
LOGGING_ONLY_MODEL_INTERACTIONS |
true |
Skip health/metrics/admin endpoints |
LOGGING_BUFFER_SIZE |
1000 |
In-memory queue capacity |
LOGGING_FLUSH_INTERVAL |
5 |
Flush interval (seconds) |
LOGGING_RETENTION_DAYS |
30 |
Auto-delete after N days (0 = forever) |
| Env var | Default | Description |
|---|---|---|
USAGE_ENABLED |
true |
Enable token usage tracking |
USAGE_PRICING_RECALCULATION_ENABLED |
true |
Allow admin pricing recalculation |
ENFORCE_RETURNING_USAGE_DATA |
true |
Add stream_options.include_usage=true to streaming requests |
USAGE_BUFFER_SIZE |
1000 |
In-memory queue capacity |
USAGE_FLUSH_INTERVAL |
5 |
Flush interval (seconds) |
USAGE_RETENTION_DAYS |
90 |
Auto-delete after N days (0 = forever) |
| Env var | Default | Description |
|---|---|---|
GUARDRAILS_ENABLED |
false |
Enable content safety filters globally |
ENABLE_GUARDRAILS_FOR_BATCH_PROCESSING |
false |
Apply guardrails to /v1/batches items |
| Env var | Default | Description |
|---|---|---|
METRICS_ENABLED |
false |
Enable Prometheus /metrics endpoint |
METRICS_ENDPOINT |
/metrics |
Metrics endpoint path |
| Env var | Default | Description |
|---|---|---|
TOKEN_SAVER_ENABLED |
false |
Enable caveman-style output compression |
TOKEN_SAVER_ENDPOINTS |
chat_completions |
Endpoints to apply it to |
TOKEN_SAVER_APPLY_STREAMING |
true |
Apply to streaming responses |
TOKEN_SAVER_OUTPUT_ENABLED |
false |
Enable output style/profile |
TOKEN_SAVER_OUTPUT_PROFILE |
concise |
Output profile name |
TOKEN_SAVER_MODELS_INCLUDE |
— | Models to include (comma-separated) |
TOKEN_SAVER_MODELS_EXCLUDE |
— | Models to exclude |
TOKEN_SAVER_PROVIDERS_INCLUDE |
— | Providers to include |
TOKEN_SAVER_PROVIDERS_EXCLUDE |
— | Providers to exclude |
TOKEN_SAVER_ON_ERROR |
allow |
Behavior on error: allow or block |
TOKEN_SAVER_EMIT_HEADERS |
true |
Emit token-saver headers in response |
TOKEN_SAVER_AUDIT_ENABLED |
true |
Log token-saver actions |
| Env var | Default | Description |
|---|---|---|
RETRY_MAX_RETRIES |
3 |
Upstream retry count |
RETRY_INITIAL_BACKOFF |
1s |
Initial backoff duration |
RETRY_MAX_BACKOFF |
30s |
Maximum backoff duration |
RETRY_BACKOFF_FACTOR |
2.0 |
Exponential backoff multiplier |
RETRY_JITTER_FACTOR |
0.1 |
Random jitter fraction |
CIRCUIT_BREAKER_FAILURE_THRESHOLD |
5 |
Failures before circuit opens |
CIRCUIT_BREAKER_SUCCESS_THRESHOLD |
2 |
Successes before circuit closes |
CIRCUIT_BREAKER_TIMEOUT |
30s |
Time before half-open retry |
| Env var | Default | Description |
|---|---|---|
FEATURE_FALLBACK_MODE |
manual |
Fallback mode: auto, manual, or off |
FALLBACK_MANUAL_RULES_PATH |
— | Path to manual fallback rules JSON |
| Env var | Default | Description |
|---|---|---|
ADMIN_ENDPOINTS_ENABLED |
true |
Enable /admin/api/v1/* REST endpoints |
ADMIN_UI_ENABLED |
true |
Enable /admin/dashboard UI |
COMBOS_ENABLED |
true |
Enable combo model calls |
CLI_TOOLS_ENABLED |
true |
Enable CLI tools integration |
CLI_TOOLS_APPLY_ENABLED |
false |
Allow admin/API to apply tool changes |
WORKFLOW_REFRESH_INTERVAL |
1m |
Workflow refresh interval from storage |
EDITION |
— | Edition identifier (Enterprise use) |
| Env var | Default | Description |
|---|---|---|
AURORA_CONFIG_PATH |
configs/config.yaml |
Override path to config YAML |
Aurora ships pre-built config profiles in configs/editions/:
| Profile | File | Use case |
|---|---|---|
| OSS | oss.env.example |
Minimal local — SQLite, no Redis |
| OSS Local Power | oss.local-power.env.example |
SQLite + Redis exact cache |
| OSS Team | oss.team.env.example |
Postgres + Redis + Qdrant — full team deployment |
export AURORA_CONFIG_PATH=configs/editions/oss.team.example.yamlThe aurora CLI is installed via npm install -g iaurora.
| Command | Description |
|---|---|
aurora init |
Scaffolds config.yaml, .env, data/ in the current directory |
aurora |
Starts the gateway server (default port 8080) |
aurora --help |
Show all CLI options |
aurora init generates:
config.yaml— Full gateway configuration with inline docs for every section.env— Environment file for secrets and runtime overrides (based on.env.template)data/— Directory for SQLite database and local model cache
The gateway merges config.yaml + .env/env vars at startup. Use config.yaml for structure and .env for secrets/keys.
aurora/
├── apps/ # Application entrypoints
│ └── aurora/ # Main gateway binary
├── internal/ # Internal packages
│ ├── api/ # HTTP handlers, middleware
│ ├── config/ # Configuration loading and validation
│ ├── providers/ # Provider implementations (OpenAI, Anthropic, etc.)
│ ├── storage/ # SQLite, PostgreSQL, MongoDB backends
│ ├── guardrails/ # Content safety filters
│ ├── cache/ # Exact and semantic caching
│ └── analytics/ # Usage tracking and metrics
├── dashboard-ui/ # React admin dashboard frontend
├── configs/ # Configuration profiles and examples
├── docs/ # Documentation and assets
├── scripts/ # Build and release scripts
├── test/ # Test suites
└── helm/ # Kubernetes Helm charts
Join our Discord for community support, setup help, and discussions.
We welcome contributions of all kinds! Check out the repository to get started:
- Setting up the development environment
- Code conventions and best practices
- How to submit pull requests
- Building and testing locally
This project is licensed under the Apache 2.0 License — see the LICENSE file for details.
Built with ❤️ by the Aurora team.