ICP 6
In this ICP we studied another type of machine learning called the clustering. We focused on the specific type of clustering which is the K-Mean Clustering. Also we studied how can we measure the performance of K-Means and increase the performance of it.
The tasks are as follows.
- Apply K-Means clustering to the data. (https://umkc.box.com/s/a9lzu9qoqfkbhjwk5nz9m6dyybhl1wqy)
- Remove null values with the mean
- Use the elbow method to find a good number of clusters with the KMeans algorithm
- Calculate the silhouette score for the above clustering
- Try feature scaling to see if it will improve the Silhouette score
- Apply PCA on the same dataset
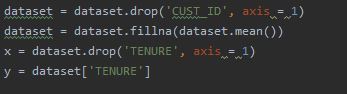
In order to apply K-Means clustering on the dataset there is some pre-processing required. Firstly a column with the name CUST_ID is removed. After that the null values are replaced with the mean of each column. After that the features and result dataframe are made.
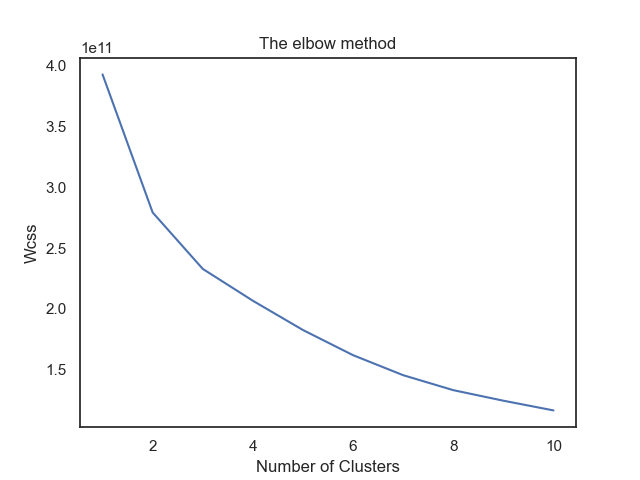
Once the data is pre-processed we have to determine the constant for number of cluster. The best way to find it out is by elbow method. The graph shown below shows that the best value for neighboring values is 3.
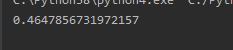
Using 3 as the cluster value we can determine the Silhouette value. The closer it is to 0 the more accurate it is.
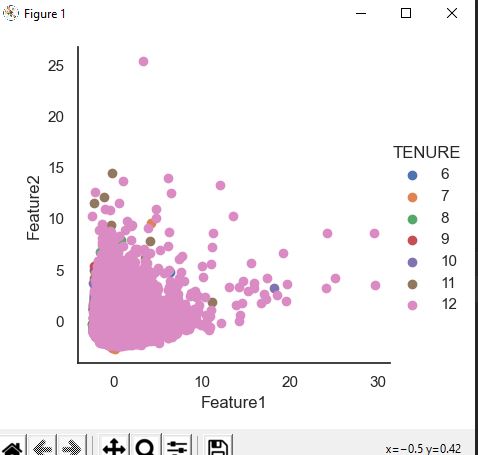
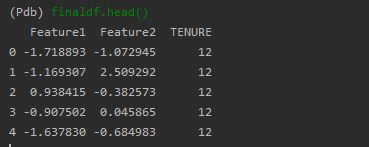
Feature scaling is applied using the PCA and standardization. Following is the screenshot showing the code to scale the data. The dataframe after PCA scaling to 2 columns is renamed having first column as Feature1 and second column as Feature with the final column as TENURE.
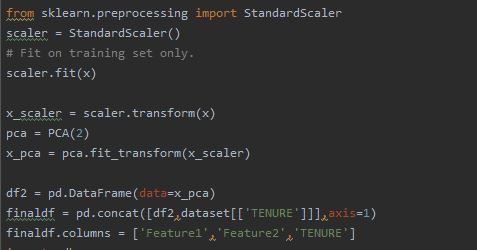
The dataframe made is shown below.
After applying the PCA we have two features. We can apply K-Means using this new dataframe. After applying the elbow method the new cluster neighbor constant is for which is shown below.
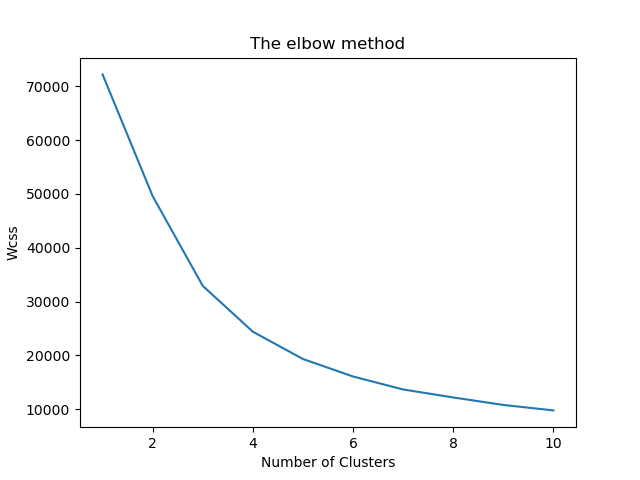
We can see that the new constant is now 4. Using this constant the Shilhouette score has improved.

We can visualize the clustering as follows.