Capability-token enforcement for LLM-synthesized procedures. The runtime is the gate, not the manifest.
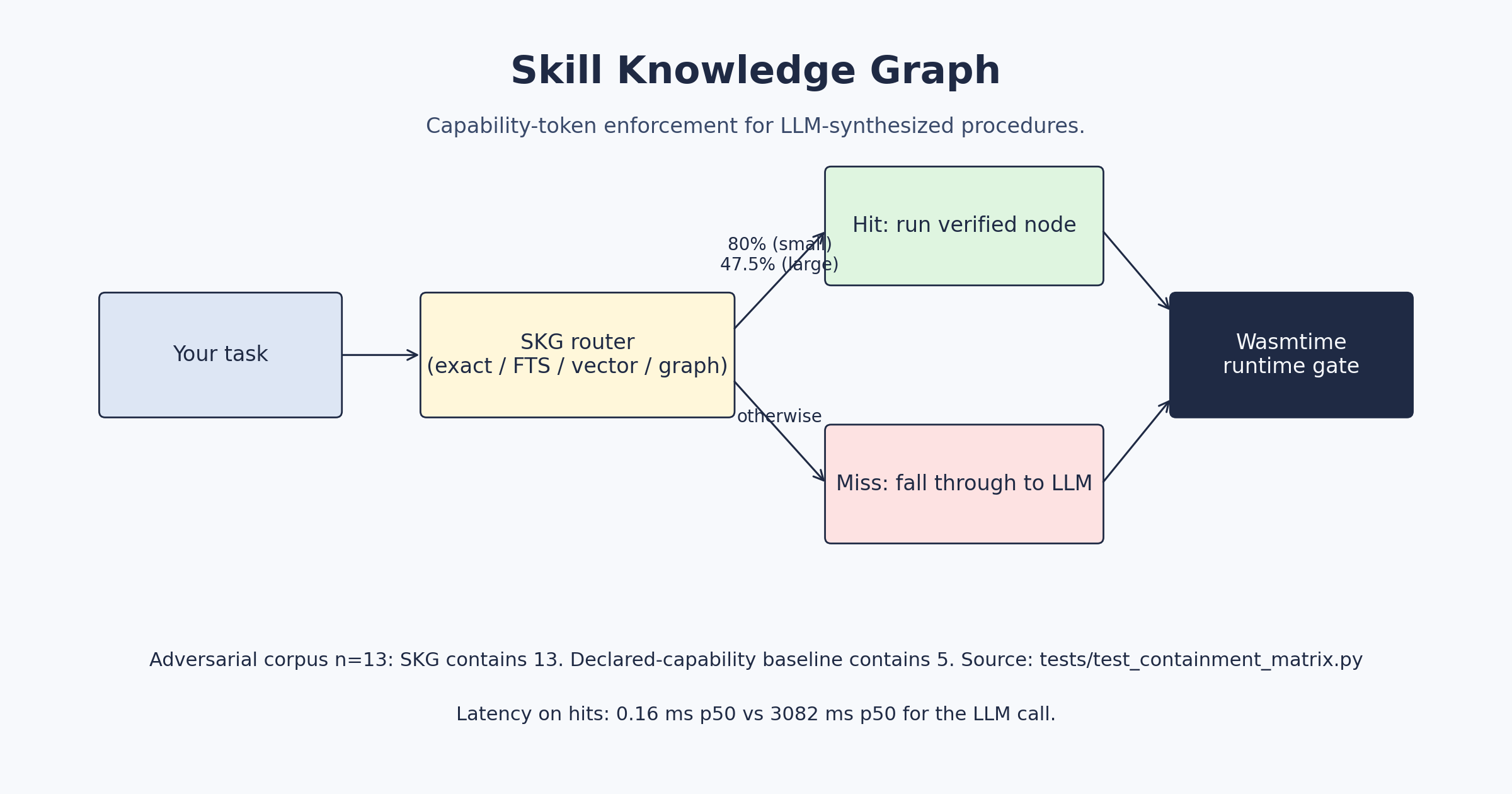
SKG sits between an LLM agent and the operations it wants to perform. On every host call, the Wasmtime runtime physically prevents anything the grant set does not include. Recurring tasks resolve through a local router and skip the LLM entirely.
Three measured numbers (full methodology in
paper.md
or paper.pdf):
- 528 input tokens saved per task (~36%) on a 200-task corpus, 95% bootstrap CI [442, 628].
- 0.16 ms p50 routing latency vs 3082 ms p50 for the LLM call.
- 13 of 13 attacks contained vs 5 of 13 for a declared-capability baseline.
pipx install skg
# or:
uv tool install skg
That puts skg and skg-mcp on your PATH. Verified this turn from
PyPI listing https://pypi.org/project/skg/0.1.0/.
skg install --client claude-code --write # writes ~/.claude.json
skg install --client copilot --write # writes ~/.copilot/mcp-config.json
codex mcp add skg -- $(which skg-mcp) # codex uses TOML, registers via its own CLI
The hosts now expose three tools: skg_route, skg_execute,
skg_list_nodes.
For scripts, CI, and one-off use without an MCP host.
skg run "draft a reviewer ping for PR review"
skg run --vendor copilot "summarise the last 10 commits"
skg run --json --dry-run "any task"
skg run routes through SKG, falls back to the configured vendor
on a miss, and prints the result.
When you want to edit the package itself:
git clone https://github.com/bdube83/skill-knowledge-graph
cd skill-knowledge-graph
python3.13 -m venv .venv
.venv/bin/pip install -e .
Nodes are Rust crates compiled to WASI. Each ships with a manifest that lists requested capabilities. The launcher mints a per-run handle table, wires only the host imports the grant set permits, then runs Wasmtime. A node that imports a host function it was not granted fails at instantiate-time.
Twelve generic effect classes plus text.generate:
local.read/write, network.read/write, external.draft/send,
browser.read/write, git.read/write, secret.read,
production.write. Three of them require an approval token at call
time.
The router runs four stages in order: exact, full-text search, vector, graph composition. The first three are local; the fourth expands typed edges in the graph.
- The 36% token saving holds on long-context tasks. On
short-context tasks the 120-token routing header costs more than
the LLM call. Below 120 tokens per task LLM input, SKG adds
overhead. Source:
eval/results/h1_stats.json. - The vector stage gets 0 of 200 hits today. The bottleneck is the
placeholder
local-hash-v1embedding, not the pipeline. - Graph composition is not yet quantitatively tested; deferred to a follow-up paper.
.venv/bin/python -m pytest tests/ -q
# 242 tests on commit 5daee75
| Path | Contents |
|---|---|
skg/ |
Kernel, router, runtime, MCP server, CLI, baselines, host adapters. |
nodes/ |
Three reference Rust-WASI crates. |
eval/ |
Corpus, runners, statistical scripts. |
tests/ |
Pytest suite. |
figures/ |
Architecture diagram source and renders. |
docs/ |
Integration guide and paper-reproduction guide. |
paper.md / paper.pdf |
The accompanying paper. |
@misc{dube2026skg,
title = {Skill Knowledge Graph: Capability-Token Enforcement for LLM-Synthesized Procedures},
author = {Dube, Bongani},
year = {2026},
note = {Paystack. Draft},
url = {https://github.com/bdube83/skill-knowledge-graph}
}Apache 2.0. See LICENSE.