Home
Distributed-Fiji is a series of scripts designed to help you run Fiji on Amazon Web Services using AWS's file storage and computing systems.
- Images and scripts are stored in S3 buckets.
- Fiji is run on "SpotFleets" of computers (or "instances") in the cloud.
Using AWS allows you to create a flexible, on-demand computing infrastructure where you only have to pay for the resources you use. This can give you access to far more computing power than you may have available at your home institution, which is great when you have large image sets to run.
Each piece of the infrastructure has to be added and configured separately, which can be time-consuming and confusing.
Distributed-Fiji tries to leverage the power of the former, while minimizing the problems of the latter.
Essentially all you need to run Distributed-Fiji is an AWS account and a terminal program; see our page on getting set up for all the specific steps you'll need to take.
The steps for actually running the Distributed-Fiji code are outlined in the README, and details of the parameters you set in each step are on their respective Wiki pages (Step 1: Config, Step 2: Jobs, Step 3: Fleet). We'll give an overview of what happens in AWS at each step here and explain what AWS does automatically once you have it set up.
Step 1: In the Config file you set quite a number of specifics that are used by EC2, ECS, SQS, and in making Dockers.
When you run $ fab setup to execute the Config, it does three major things:
- Creates task definitions. These are found in ECS. They define the configuration of the Dockers and include the settings you gave for EXPECTED_NUMBER_FILES, MIN_FILE_SIZE_BYTES, and MEMORY.
- Makes a queue in SQS (it is empty at this point) and sets a dead-letter queue.
- Makes a service in ECS which defines how many Dockers you want.
Step 2: In the Job file you set the location of your script, input, and output as well as list all of the individual tasks that you want run. When you submit the Job file it adds that list of tasks to the queue in SQS (which you made in the previous step).
Step 3: In the Fleet file you set the number and size of the EC2 instances you want.
After these steps are complete, a number of things happen automatically:
- ECS puts Docker containers onto EC2 instances. Ideally, you have set the same parameters in your Config file and your Fleet file. If there is a mismatch and the Docker is larger than the instance it will not be placed. ECS will keep placing Dockers onto an instance until it is full, so if you accidentally create instances that are too large you may end up with more Dockers placed on it than intended. This is also why you may want multiple ECS_CLUSTERs so that ECS doesn't blindly place Dockers you intended for one job onto an instance you intended for another job.
- When a Docker container gets placed it gives the instance it's on its own name.
- Once an instance has a name, the Docker gives it an alarm that tells it to reboot if it is sitting idle for 15 minutes.
- The Docker hooks the instance up to the _perinstance logs in Cloudwatch.
- The instances look in SQS for a job. Any time they don't have a job they go back to SQS. If SQS tells them there are no visible jobs then they shut themselves down.
- When an instance finishes a job it sends a message to SQS and removes that job from the queue.
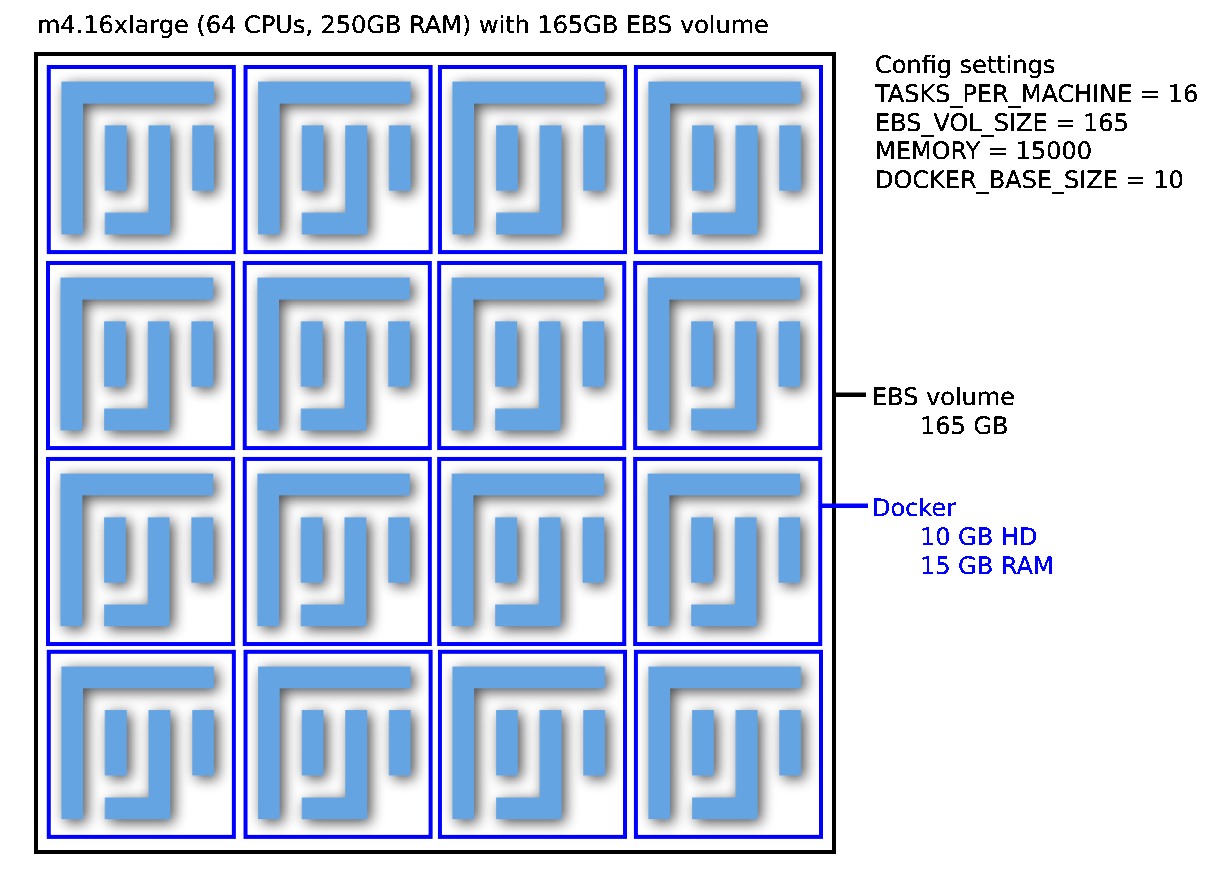
This is an example of one possible instance configuration. This is one m4.16xlarge EC2 instance (64 CPUs, 250GB of RAM) with a 165 EBS volume mounted on it. A spot fleet could contain many such instances.
It has 16 tasks (individual Docker containers).
Each Docker container uses 10GB of hard disk space and is assigned 4 CPUs and 15 GB of RAM (which it does not share with other Docker containers).
Each container shares its individual resources among 4 copies of Fiji. Each copy of Fiji runs a pipeline on one "job", which can be anything from a single image to an entire 384 well plate or timelapse movie.
You can optionally stagger the start time of these 4 copies of Fiji, ensuring that the most memory- or disk-intensive steps aren't happening simultaneously, decreasing the likelihood of a crash.
Read more about this and other configurations in Step 1: Configuration.
To some degree, you determine the best configuration for your needs through trial and error.
- Looking at the resources Fiji uses on your local computer when it runs your images can give you a sense of roughly how much hard drive and memory space each image requires, which can help you determine your group size and what machines to use.
- Prices of different machine sizes fluctuate, so the choice of which type of machines to use in your spot fleet is best determined at the time you run it. How long a job takes to run and how quickly you need the data may also affect how much you're willing to bid for any given machine.
- Running a few large Docker containers (as opposed to many small ones) increases the amount of memory all the copies of Fiji are sharing, decreasing the likelihood you'll run out of memory if you stagger your Fiji start times. However, you're also at a greater risk of running out of hard disk space.
Keep an eye on all of the logs the first few times you run any pipeline, and you'll get a sense of whether your resources are being utilized well or if you need to do more tweaking.
Feel free! We're always looking for ways to improve.
Distributed-Fiji is a project from the Carpenter Lab at the Broad Institute in Cambridge, MA, USA.