Feature Proposal: Loops
This issue describes what we need to support loops in shell programs. Currently, our scheduler only handles known partial orders where everything is unrolled and each node is supposed to execute once. In real programs however, we have loops (and even nested loops) where we can't (always) determine the number of times they will execute. This issue describes a conservative solution to resolve this issue and some hints on how to make this solution more optimistic to allow for more parallelism.
Example loop
for i ...
cmd1
for j ...
cmd2
cmd3
done
cmd4
doneProposal: Loop nodes in partial order
To support these nodes we could extend partial orders to abstract partial orders that also contain loop nodes, i.e., nodes that have an associated stack of loop identifiers.
The abstract partial order for the above program is shown in the attached picture.
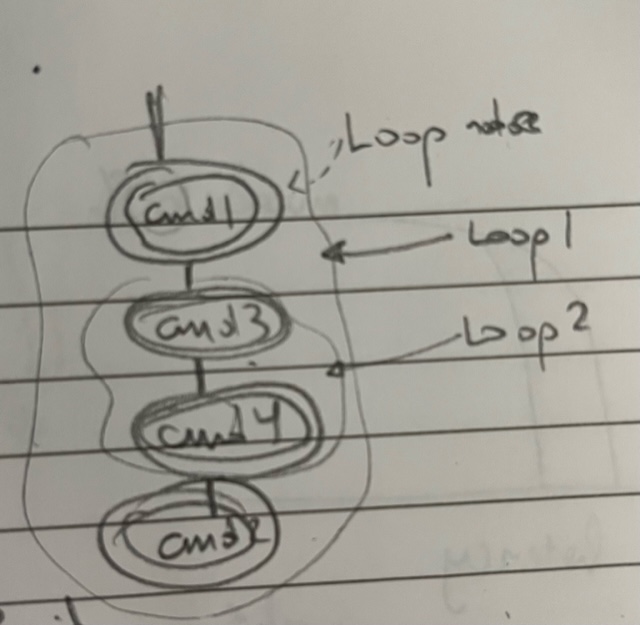
Each loop can then be extended with a loop identifier in the preprocessing pass (kk: is this sound) and everytime the JIT sends a wait to the scheduler it also passes the stack of loop contexts (node_id.loop1.loop2) to uniquely idenitfy the abstract loop node as well as a loop iteration counter for each loop (to uniquely identify the instance of the abstract loop node).
Instances of abstract loop nodes are ordered syntactically by doing an alpha-sort of their stack of iteration counts.
Scheduling
To start with and incrementally support loops, I propose starting execution of a loop node instance only after we receive the wait for now (non-speculative execution for loop nodes). Later down the line, we will be able to speculate loop nodes by guessing the next variable values, but we should not start with that.
The scheduler then knows that a loop is done iterating when it receives the wait for a node after the loop. Note that this doesn't mean that the loop is completely done, e.g., when having nested loops. Later we could consider sending a loop-done message to the scheduler right after the loop is done.
Feature Proposal: Loops
This issue describes what we need to support loops in shell programs. Currently, our scheduler only handles known partial orders where everything is unrolled and each node is supposed to execute once. In real programs however, we have loops (and even nested loops) where we can't (always) determine the number of times they will execute. This issue describes a conservative solution to resolve this issue and some hints on how to make this solution more optimistic to allow for more parallelism.
Example loop
Proposal: Loop nodes in partial order
To support these nodes we could extend partial orders to abstract partial orders that also contain loop nodes, i.e., nodes that have an associated stack of loop identifiers.
The abstract partial order for the above program is shown in the attached picture.
Each loop can then be extended with a loop identifier in the preprocessing pass (kk: is this sound) and everytime the JIT sends a wait to the scheduler it also passes the stack of loop contexts (node_id.loop1.loop2) to uniquely idenitfy the abstract loop node as well as a loop iteration counter for each loop (to uniquely identify the instance of the abstract loop node).
Instances of abstract loop nodes are ordered syntactically by doing an alpha-sort of their stack of iteration counts.
Scheduling
To start with and incrementally support loops, I propose starting execution of a loop node instance only after we receive the wait for now (non-speculative execution for loop nodes). Later down the line, we will be able to speculate loop nodes by guessing the next variable values, but we should not start with that.
The scheduler then knows that a loop is done iterating when it receives the wait for a node after the loop. Note that this doesn't mean that the loop is completely done, e.g., when having nested loops. Later we could consider sending a loop-done message to the scheduler right after the loop is done.