
🏗️ 🚀 📈
Flyte is an open-source orchestrator that facilitates building production-grade data and ML pipelines. It is built for scalability and reproducibility, leveraging Kubernetes as its underlying platform. With Flyte, user teams can construct pipelines using the Python SDK, and seamlessly deploy them on both cloud and on-premises environments, enabling distributed processing and efficient resource utilization.
Write code in Python or any other language and leverage a robust type engine.
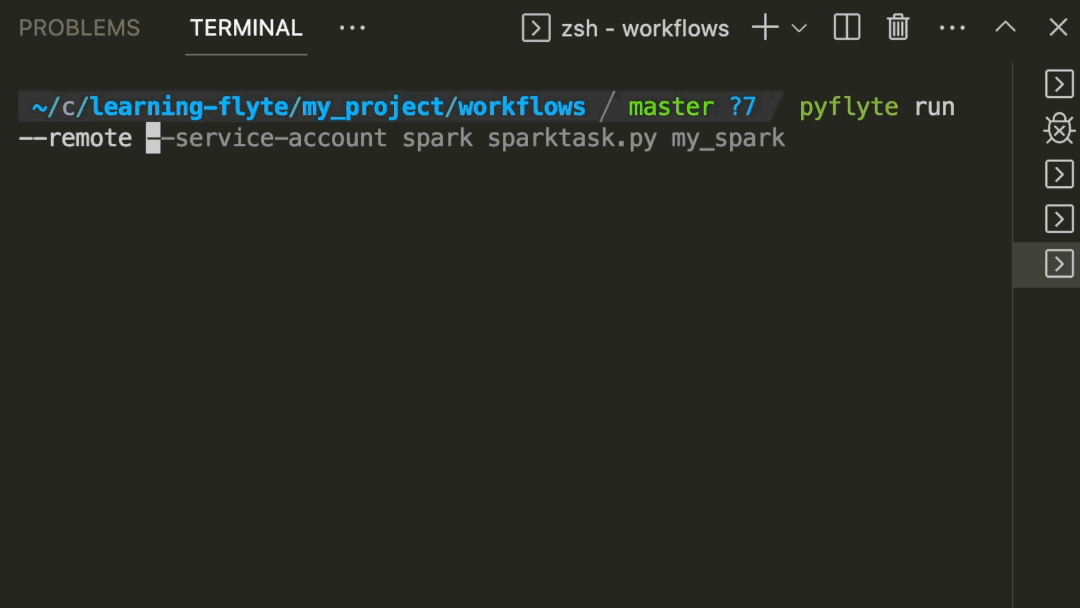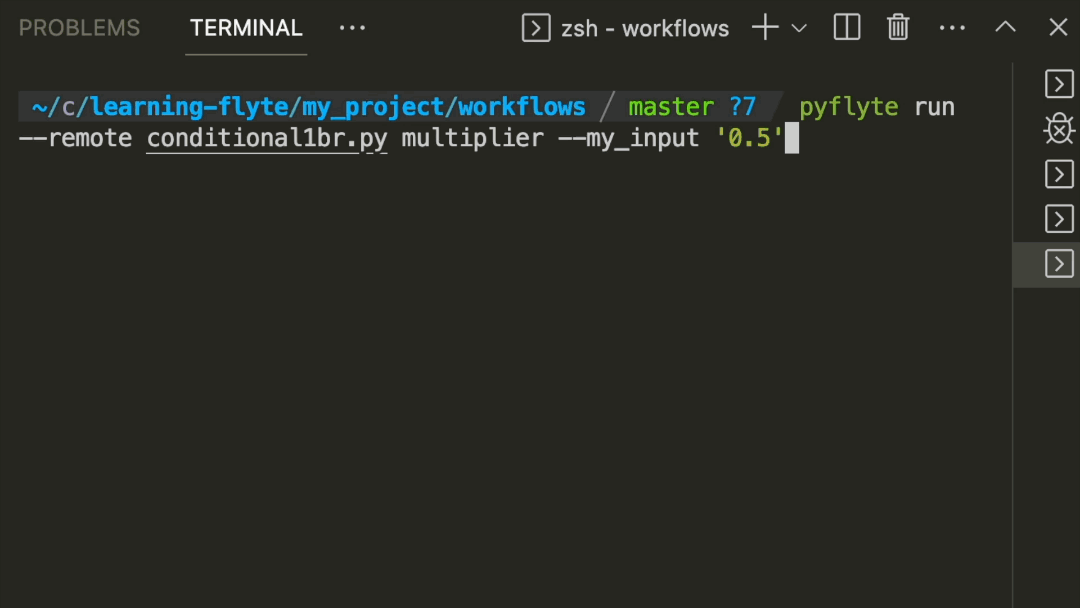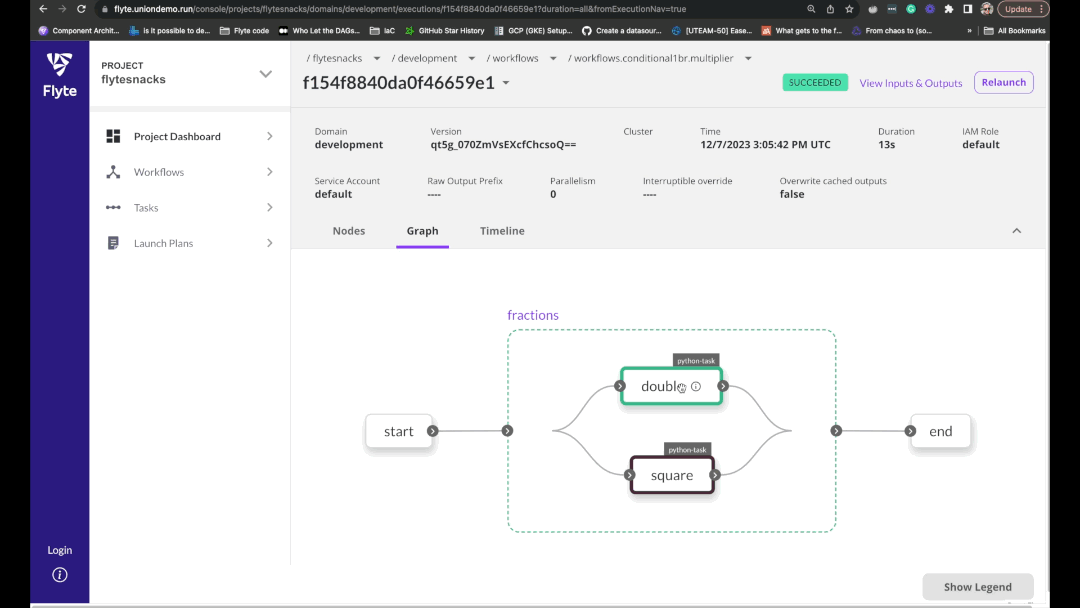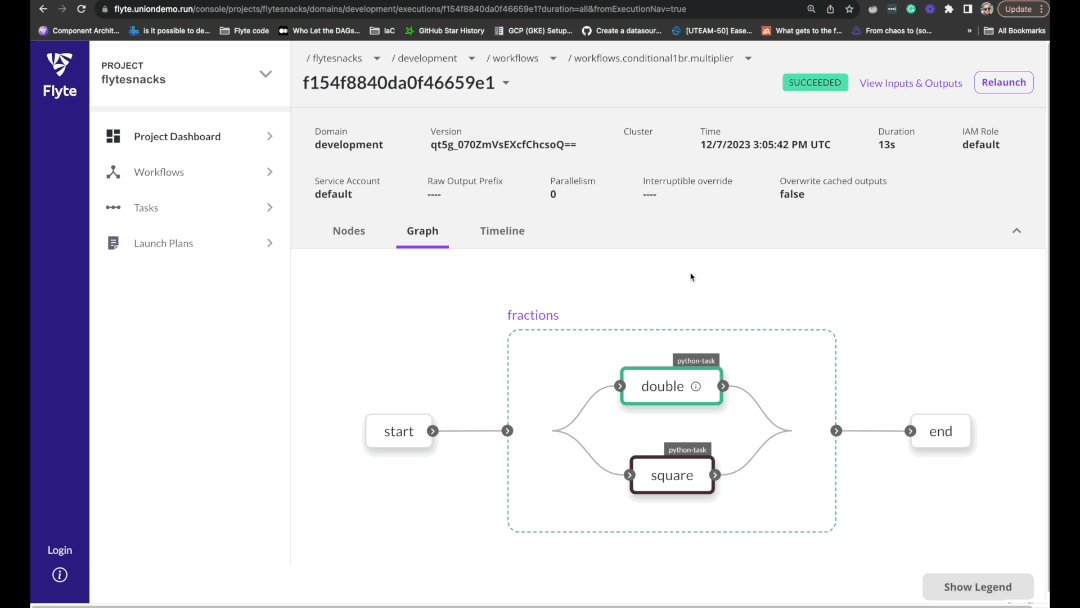
Either locally or on a remote cluster, execute your models with ease.
- Install Flyte's Python SDK
pip install flytekit- Create a workflow (see example)
- Run it locally with:
pyflyte run hello_world.py hello_world_wfReady to try a Flyte cluster?
- Create a new sandbox cluster, running as a Docker container:
flytectl demo start- Now execute your workflows on the cluster:
pyflyte run --remote hello_world.py hello_world_wf
Do you want to see more but don't want to install anything?
Head over to https://sandbox.union.ai/. It allows you to experiment with Flyte's capabilities from a hosted Jupyter notebook.
Ready to productionize?
Go to the Deployment guide for instructions to install Flyte on different environments
- Fine-tune Code Llama on the Flyte codebase
- Forecast sales with Horovod and Spark
- Nucleotide Sequence Querying with BLASTX
🚀 Strongly typed interfaces: Validate your data at every step of the workflow by defining data guardrails using Flyte types.
🌐 Any language: Write code in any language using raw containers, or choose Python, Java, Scala or JavaScript SDKs to develop your Flyte workflows.
🔒 Immutability: Immutable executions help ensure reproducibility by preventing any changes to the state of an execution.
🧬 Data lineage: Track the movement and transformation of data throughout the lifecycle of your data and ML workflows.
📊 Map tasks: Achieve parallel code execution with minimal configuration using map tasks.
🌎 Multi-tenancy: Multiple users can share the same platform while maintaining their own distinct data and configurations.
🌟 Dynamic workflows: Build flexible and adaptable workflows that can change and evolve as needed, making it easier to respond to changing requirements.
⏯️ Wait for external inputs before proceeding with the execution.
🌳 Branching: Selectively execute branches of your workflow based on static or dynamic data produced by other tasks or input data.
📈 Data visualization: Visualize data, monitor models and view training history through plots.
📂 FlyteFile & FlyteDirectory: Transfer files and directories between local and cloud storage.
🗃️ Structured dataset: Convert dataframes between types and enforce column-level type checking using the abstract 2D representation provided by Structured Dataset.
🛡️ Recover from failures: Recover only the failed tasks.
🔁 Rerun a single task: Rerun workflows at the most granular level without modifying the previous state of a data/ML workflow.
🔍 Cache outputs: Cache task outputs by passing cache=True to the task decorator.
🚩 Intra-task checkpointing: Checkpoint progress within a task execution.
⏰ Timeout: Define a timeout period, after which the task is marked as failure.
🏭 Dev to prod: As simple as changing your domain from development or staging to production.
💸 Spot or preemptible instances: Schedule your workflows on spot instances by setting interruptible to True in the task decorator.
☁️ Cloud-native deployment: Deploy Flyte on AWS, GCP, Azure and other cloud services.
📅 Scheduling: Schedule your data and ML workflows to run at a specific time.
📢 Notifications: Stay informed about changes to your workflow's state by configuring notifications through Slack, PagerDuty or email.
⌛️ Timeline view: Evaluate the duration of each of your Flyte tasks and identify potential bottlenecks.
💨 GPU acceleration: Enable and control your tasks’ GPU demands by requesting resources in the task decorator.
🐳 Dependency isolation via containers: Maintain separate sets of dependencies for your tasks so no dependency conflicts arise.
🔀 Parallelism: Flyte tasks are inherently parallel to optimize resource consumption and improve performance.
💾 Allocate resources dynamically at the task level.
Join the likes of LinkedIn, Spotify, Freenome, Pachama, Warner Bros. and many others in adopting Flyte for mission-critical use cases. For a full list of adopters and information on how to add your organization or project, please visit our ADOPTERS page.
📆 Weekly office hours: Live informal sessions with the Flyte team held every week. Book a 30-minute slot and get your questions answered.
👥 Monthly community sync: Happening the first Tuesday of every month, this is where the Flyte team provides updates on the project, and community members can share their progress and ask questions.
💬 Slack: Join the Flyte community on Slack to chat with other users, ask questions, and get help.
📹 Youtube: Tune into panel discussions, customer success stories, community updates and feature deep dives.
📄 Blog: Here, you can find tutorials and feature deep dives to help you learn more about Flyte.
💡 RFCs: RFCs are used for proposing new ideas and features to improve Flyte. You can refer to them to stay updated on the latest developments and contribute to the growth of the platform.
There are many ways to get involved in Flyte, including:
- Submitting bugs and feature requests for various components.
- Reviewing the documentation and submitting pull requests for anything from fixing typos to adding new content.
- Speaking or writing about Flyte or any other ecosystem integration and letting us know!
- Taking on a
help wantedorgood-first-issueand following the CONTRIBUTING guide to submit changes to the codebase. - Upvoting popular feature requests to show your support.
































































































































































































































































































































































Flyte is available under the Apache License 2.0. Use it wisely.