从零开始深入理解 AI Infra 的核心全栈技术
在线浏览:https://caomaolufei.github.io/AIInfraGuide/
AI Infra 正在成为大模型时代最关键的工程能力之一。本项目系统梳理从 GPU 硬件到分布式训练、从 CUDA 编程到推理优化的完整技术栈,帮助工程师构建扎实的 AI 基础设施知识体系。同时提供了面试宝典模块(共收录 180+ 场面试真题,覆盖 40+ 家公司)。



大模型时代,AI 基础设施(AI Infra)已经成为支撑训练、推理和服务的核心技术底座。然而,这个领域有一个显著的矛盾——技术迭代极快,但系统化的中文学习资料却严重匮乏。
很多工程师在学习 AI Infra 时面临相似的困境:
- CUDA 编程的入门资料散落各处,缺乏从基础到算子优化的完整路径
- 分布式训练涉及 DDP、FSDP、3D 并行等众多概念,不知道该从哪里开始
- 推理优化技术(PagedAttention、量化、Speculative Decoding)发展迅猛,难以跟上节奏
- 性能分析工具(Nsight Systems、Nsight Compute)功能强大,但上手门槛不低
AIInfraGuide 正是为了解决这些问题而创建的——一个开源、系统、面向实践的 AI Infra 知识库,帮助工程师构建从硬件到软件、从训练到推理的完整知识体系。
知识库围绕 4 大学习模块 + 2 个辅助板块 + 面试宝典,覆盖 AI Infra 工程师需要掌握的关键技术栈:
| 板块 | 涵盖内容 |
|---|---|
| AIInfra 学习路线 | 系统化的学习路径、知识图谱、推荐资源 |
| 模块一:前置知识 | 编程语言基础、数学基础、Transformer 架构、PyTorch 框架、GPU 硬件概论、集合通信基础 |
| 模块二:CUDA 编程与算子优化 | CUDA 编程入门、性能优化基础、Reduce/GEMM/Softmax/Attention 经典算子实现、AI 编译器、性能分析工具链 |
| 模块三:分布式训练 | 分布式训练总论、数据并行(DP/DDP/FSDP)、ZeRO 系列、张量并行与序列并行、流水线并行、3D 并行、训练框架实战 |
| 模块四:推理优化 | LLM 推理基础、推理引擎核心技术、主流推理框架(vLLM 等)、量化、Speculative Decoding、PD 解耦架构、性能分析与 Benchmark |
| 性能分析 | Nsight Systems/Compute、Roofline 模型、Profiling 实战 |
| 面试宝典 | 目前共收录 180+ 场面试真题,覆盖 40+ 家公司,按梯队分类组织,助你高效备战拿下心仪 Offer |
每篇文章都遵循「先白话后术语」的写作原则——先用通俗的语言解释"是什么、为什么需要",再给出严谨的技术细节,确保读者既看得懂也学得对。
| 序号 | 文章 | 说明 |
|---|---|---|
| 0 | 从零理解 AI Infra | AI Infra 的定义、技术栈全貌与核心组件 |
| 1 | AI Infra 学习路线 | 系统化的学习路径与知识图谱 |
涵盖 GPU 架构、编程语言基础、数学基础、Transformer 架构、PyTorch 框架和集合通信等核心前置知识,为后续深入 AI Infra 打好坚实基础。
| 章节 | 主要内容 |
|---|---|
| 第 1 章 编程语言基础 | Python 进阶、C/C++ 核心、Linux 与开发环境 |
| 第 2 章 数学基础 | 线性代数、概率论与统计、微积分 |
| 第 3 章 Transformer 架构详解 | Self-Attention、前馈网络、位置编码、归一化层、模型架构变种 |
| 第 4 章 PyTorch 框架 | Tensor 与自动微分、Module 与训练流程、调试与性能分析 |
| 第 5 章 GPU 硬件概论 | GPU 架构总览、存储层次、主流 GPU 规格对比、互联拓扑 |
| 第 6 章 集合通信基础 | 通信原语、通信算法、NCCL |
已更新文章:
| 序号 | 文章 | 说明 |
|---|---|---|
| 1 | GPU 基础知识:从硬件架构到 AI 计算 | CPU vs GPU、SM 架构、显存层级、Tensor Core |
| 2 | NVIDIA GPU 架构演进:从 Volta 到 Blackwell | V100 → A100 → H100 → B200 架构演进 |
| 3 | Transformer 架构:快速入门篇 | Encoder-Decoder 结构、Self-Attention 机制入门 |
| 4 | AI Infra 工程师为什么必须懂 Transformer | 从 Infra 视角理解 Transformer 的计算与显存特性 |
| 5 | Transformer 全貌及代码实现 | 完整 Transformer 架构拆解与 PyTorch 实现 |
从 CUDA 编程入门到经典算子实现(Reduce、GEMM、Softmax、Attention),再到 AI 编译器和性能分析工具链,系统掌握 GPU 编程与算子优化技术。
| 章节 | 主要内容 |
|---|---|
| 第 1 章 CUDA 编程入门 | 开发环境搭建、编程模型、内存模型、第一个实用 Kernel |
| 第 2 章 CUDA 性能优化基础 | Warp 与执行模型、内存访问优化、Occupancy 与资源分配、同步与原子操作 |
| 第 3 章 经典算子实现 - Reduce | 朴素实现、共享内存+树形归约、Warp Shuffle 优化、多级归约 |
| 第 4 章 经典算子实现 - GEMM | 矩阵乘法基础、Shared Memory Tiling、进一步优化、与 cuBLAS 对比 |
| 第 5 章 经典算子实现 - Softmax 与算子融合 | Softmax 数值稳定实现、Online Softmax、算子融合 |
| 第 6 章 Attention 算子 | FlashAttention V1/V2/V3、Decode 阶段加速、PagedAttention CUDA 实现 |
| 第 7 章 AI 编译器 | Triton、torch.compile、TVM/XLA 概述 |
| 第 8 章 性能分析工具链 | Nsight Systems/Compute、PyTorch Profiler |
已更新文章:
| 序号 | 文章 | 说明 |
|---|---|---|
| 1 | CUDA 编程入门指南 | CUDA 编程模型、线程层级、内存模型与 Kernel 编写 |
从分布式训练总论出发,深入数据并行、ZeRO 系列、张量并行、流水线并行、3D 并行策略,最终通过训练框架实战串联全部知识。
| 章节 | 主要内容 |
|---|---|
| 第 1 章 分布式训练总论 | 为什么需要分布式训练、训练状态显存分析、并行策略全景 |
| 第 2 章 数据并行 | DataParallel、DistributedDataParallel、FSDP |
| 第 3 章 ZeRO 系列 | ZeRO 核心思想、ZeRO-1/2/3、ZeRO-Offload、选型指南 |
| 第 4 章 张量并行与序列并行 | 张量并行原理、序列并行、GQA/MQA 下的 TP 切分 |
| 第 5 章 流水线并行 | GPipe、PipeDream、1F1B 调度、气泡率分析 |
| 第 6 章 3D 并行与混合训练策略 | 3D 并行组合、混合精度训练、梯度累积、Activation Checkpointing |
| 第 7 章 训练框架实战 | Megatron-LM、DeepSpeed、实战配置 |
已更新文章:
| 序号 | 文章 | 说明 |
|---|---|---|
| 1 | PyTorch 分布式训练:从原理到实战 | DDP、FSDP、ZeRO、通信原语、torchrun 多机训练 |
覆盖 LLM 推理基础、推理引擎核心技术、主流推理框架、量化、Speculative Decoding、PD 解耦架构,以及性能分析与端到端实战。
| 章节 | 主要内容 |
|---|---|
| 第 1 章 LLM 推理基础 | Prefill/Decode 两阶段、KV Cache、推理性能指标 |
| 第 2 章 推理引擎核心技术 | PagedAttention、Continuous Batching、调度策略 |
| 第 3 章 主流推理框架 | vLLM、SGLang、TensorRT-LLM 等 |
| 第 4 章 量化 | INT8/INT4 量化、GPTQ、AWQ、SmoothQuant |
| 第 5 章 Speculative Decoding | 投机解码原理、Draft Model、验证策略 |
| 第 6 章 PD 解耦架构 | Prefill-Decode 解耦部署、异构推理 |
| 第 7 章 性能分析与 Benchmark | 推理性能评估、延迟/吞吐量分析 |
| 第 8 章 推理优化选型与端到端实战 | 方案选型、部署实战、生产环境最佳实践 |
已更新文章:
| 序号 | 文章 | 说明 |
|---|---|---|
| 1 | vLLM 快速入门 | 从安装到部署你的第一个 LLM 推理服务 |
🚧 施工中,敬请期待...
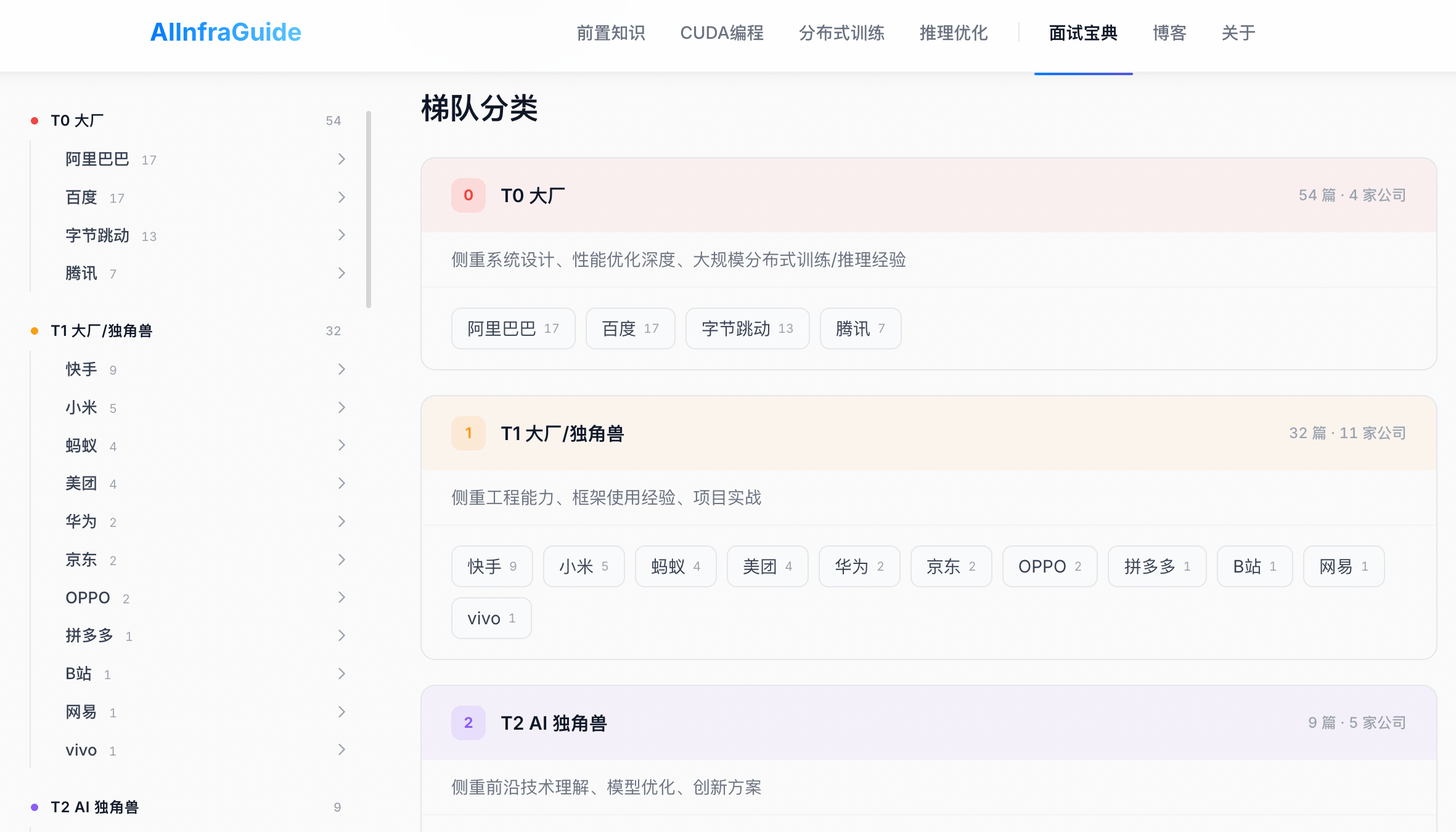
共收录 180+ 场面试真题,覆盖 40+ 家公司,按梯队分类组织。在线浏览 →
涵盖公司包括字节跳动、阿里巴巴、腾讯、百度、快手、美团、蚂蚁、英伟达、MiniMax、蔚来、小鹏、理想等。
投递总览:
| 梯队 | 公司 | 主要 AI Infra 岗位 |
|---|---|---|
| T0 大厂 | 字节跳动、阿里巴巴、腾讯、百度 | AI Infra 工程师、高性能计算研发、推理优化工程师、分布式训练框架 |
| T1 大厂/独角兽 | 快手、拼多多、美团、蚂蚁、OPPO、华为、蔚来 | AI Infra、高性能计算、大模型推理优化、AI 平台开发 |
| T2 AI 独角兽 | MiniMax、阶跃星辰、智谱AI、面壁智能、月之暗面 | AI Infra、大模型算法 (偏 Infra)、推理系统开发、Agent Infra |
| T3 芯片/硬件厂商 | 英伟达、摩尔线程、海光、寒武纪、壁仞科技、飞腾 | 算子开发、CUDA 优化、GPU 软件工程师、AI 编译器、高性能计算 |
| T4 自动驾驶/车企 | 小鹏汽车、蔚来、理想、卓驭(大疆车载)、小马智行、元戎启行 | AI Infra、高性能计算、大模型推理优化、AI 平台 |
| T5 其他 | 科大讯飞、网易、海康威视、联想、猿辅导、好未来等 | AI Infra、高性能计算、推理引擎开发、大模型算法 |
注:分布式训练相关的岗位特别少,一般只有搞大模型的大厂才有,所有大家在准备的求职的过程中,可以重点关注算子优化、推理优化、推理框架这类岗位,训练相关的技术点了解即可,不用深钻。
| 梯队 | 考察侧重 |
|---|---|
| T0 大厂(字节/阿里/腾讯/百度) | 结构化面试 2-3 轮,项目深挖 + 模型架构 + 推理/训练优化 + C++ 八股 + LeetCode Medium |
| T1 大厂/独角兽(快手/美团/蚂蚁等) | 与 T0 类似,推理优化问得多,部分公司重视系统设计 |
| T2 AI 独角兽(MiniMax/阶跃/智谱) | 偏研究导向,深挖 MoE 路由优化、RLHF 细节、前沿 paper,传统八股较少 |
| T3 芯片/硬件(英伟达/壁仞/寒武纪) | 重 GPU 架构、CUDA 编程、HPC 基础,手写 kernel 频率最高 |
| T4 车企/自动驾驶(蔚来/大疆车载/小鹏) | 重 C++ 功底、推理部署(TensorRT/TVM/量化)、边缘实时性能,LLM 问得少 |
| T5 其他(海康/科大讯飞等) | 难度适中,C++ 和推理部署为主 |
投递时间线:
| 时间段 | 投递策略 |
|---|---|
| 3-4月 | 暑期实习提前批(字节、阿里、腾讯、快手) |
| 5-6月 | 暑期实习正式批 + 日常实习(美团、拼多多、中小厂) |
| 7-8月 | 秋招提前批(字节 AML、百度、华为) |
| 9-10月 | 秋招正式批(全面投递) |
| 11-12月 | 秋招补录 + 春招准备 |
| 次年2-4月 | 春招(HC 较少,竞争激烈) |
AIInfraGuide 是一个开源项目,欢迎通过以下方式参与共建:
- 提交 Issue:发现错误、提出建议,或者告诉我们你希望看到的主题
- 贡献 PR:分享你的实践经验、补充技术细节、改进现有内容
- Star & Share:如果觉得有帮助,请在 GitHub 上给个 Star,让更多人发现这个项目
💡 提示:如果你不确定从哪里开始,推荐先阅读知识库中的「AIInfra 学习路线」,它会帮你梳理一条清晰的学习路径。
让我们一起构建 AI Infra 社区的知识基础设施。
MIT