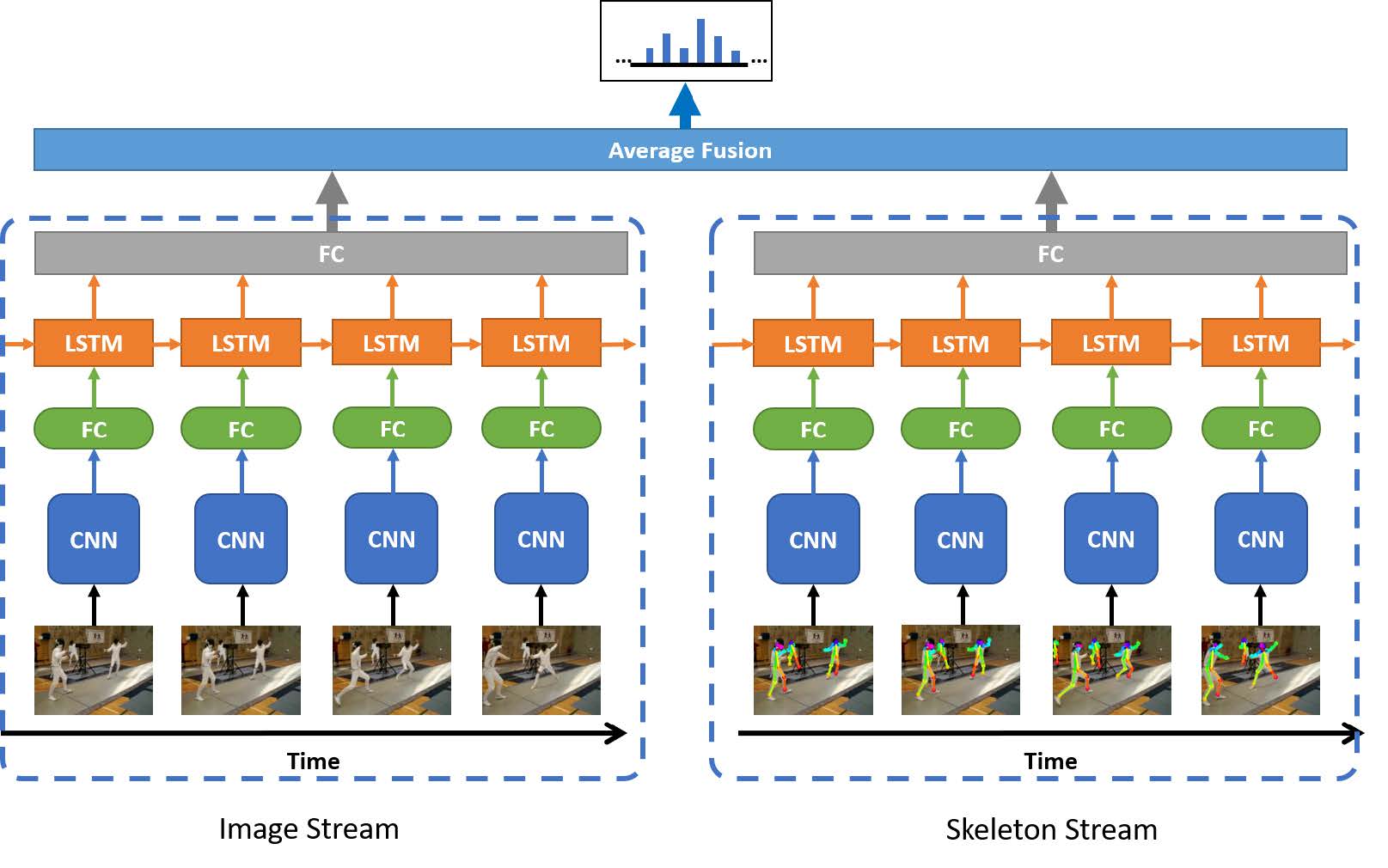
This project aims to recognize human's action in a series of video frames through Two Stream with Skeleton.
-
Python 3.6.5 (Anaconda 4.5.4)
-
PyTorch 1.5.1
-
TensorFlow 2.2.0
-
CUDA 10.1
Other packages needed are listed in requirements. The "Openpose" install details refer to https://github.com/ildoonet/tf-pose-estimation.
-
For preparing dataset, you should make the structure of your folder to be in this form:
video_data ├── brush_hair │ ├── April_09_brush_hair_u_nm_np1_ba_goo_0.avi │ ├── April_09_brush_hair_u_nm_np1_ba_goo_1.avi │ ├── ... │ ├── My_Hair_Routine_brush_hair_h_nm_np1_le_goo_0.avi ├── cartwheel │ ├── (Rad)Schlag_die_Bank!_cartwheel_f_cm_np1_le_med_0.avi │ ├── Acrobacias_de_un_fenomeno_cartwheel_f_cm_np1_ba_bad_8.avi │ ├── ... │ ├── Zwei_hoffnungslose_Pflegef_lle_beim_Turnen(Part4)_cartwheel_f_cm_np1_ri_bad_0.avi ├── .... ├── .... ├── wave │ ├── _I_ll_Just_Wave_My_Hand__sung_by_Cornerstone_Male_Choir_wave_u_cm_np1_fr_med_0.avi │ ├── _I_ll_Just_Wave_My_Hand__sung_by_Cornerstone_Male_Choir_wave_u_cm_np1_fr_med_1.avi │ ├── ... │ ├── winKen_wave_u_cm_np1_ri_bad_1.avi └── ... -
Convert Videos to Images
cd util
python video2jpg.py ../dataset/video_data ../dataset/train_rgb- Extract Skeleton Data
cd tf-pose-estimation
python run.py --image_path ../dataset/train_rgb --result_path ../dataset/train_pose_cmu --resize=656x368Use the following command to train the model:
python train.py
python train_cmu.py
After training, the model settings and results will be saved in /save_model .
python average_fusion.py
You can use Single Stream (faster) which has trained before to predict the human's action:
python pred.py --twostream False
or use Two Stream (slower but higher accuracy):
python pred.py
| Top-1 | Top-5 | |
|---|---|---|
| Single Image Stream | 68.32% | 88.07% |
| Single Skeleton Stream | 63.35% | 85.23% |
| Two Stream with Skeleton | 70.71% | 89.57% |