과제 + #8
Description
과제
- CORS란 무엇이며, 어떤 상황에서 일어나는지 / 어떻게 해결하는지 알아보고, 프로젝트에 적용하기
- N+1 문제와 해결법
- 레이지 로딩, 이거 로딩의 원리
CORS란?
교차 출처 리소스 공유(Cross-origin resource sharing, CORS), 교차 출처 자원 공유는 웹 페이지 상의 제한된 리소스를 최초 자원이 서비스된 도메인 밖의 다른 도메인으로부터 요청할 수 있게 허용하는 구조이다.
SOP란
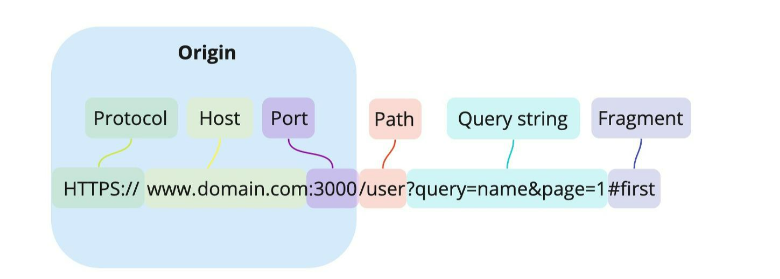
CORS 에러는 SOP라는 브라우저의 원칙으로 인해 발생한다.SOP는 Same Origin Policy로, 동일 출처가 아닌 경우 발생한다.여기서 동일 출처는 프로토콜,호스트,포트가 동일한 경우이다.
SOP가 필요한 이유
동일 출처가 아닐 경우 브라우저가 접근을 차단하는 이유는 무엇일까?
사용자가 웹사이트에 접근할 때는 브라우저의 쿠키에 로그인 세션 토큰을 남기게된다.해당 토큰을 사용해 사용자는 매번 로그인할 필요없이 서비스를 이용할 수 있다.웹사이트는 토큰을 받아 파싱 및 해석하여 로그인되었음을 확인한다.
하지만 로그인 토큰이 남아있는 브라우저에서 사용자가 악성 사이트에 접속한 경우,악성 사이트는 사용자 브라우저의 토큰에 접근할 수 있다.악성 사이트가 해당 토큰으로 다른 웹 사이트에 로그인할 경우, 사용자는 해킹에 노출된다.
이 상황에 브라우저는 SOP에 따라 이러한 상황을 막아준다.브라우저는 악성 사이트의 요청서버와 응답을 주는 응답 서버의 출처가 다른 것을 보고CORS 에러를 뱉는다.
웹 사이트 서버에서 악성사이트를 허가해주지 않는 이상, 악성사이트는 CORS에러로 정상적으로 로그인할 수 없기때문이다.
SOP로 발생하는 에러를 해결하는 방법
SOP로 사용자를 보호할 수 있지만, 서버는 점차 확장되고 가끔은 다른 회사의 서버부를 이용해야(API 사용 등) 하는 상황이 자주 발생한다.따라서 조건에 맞게 이런 다른 출처들을 허가해주어야 한다.
- 단순 요청 Simple요청만으로 서버에 영향을 주지 않는 단순 요청의 경우,
- 서버에게 본 요청을 전달한다.
- 서버가 OK와 Access-Control-Allow-Origin를 보낸 경우 응답을 전달한다.
- Access-Control-Allow-Origin이 안오면 본요청이 fail되고 브라우저는 CORS에러를 발생시킨다.
- 예비요청이 있는 경우 Preflight단순요청이 아닌경우, 예비요청을 통해 허가를 받은 후, 본 요청을 할 수 있습니다.
- OPTIONS 메소드로 Origin(호스트 uri)을 실어서 보낸다. (예비 요청)
- 서버가 요청을 허가할 경우 OK랑 Access-Control-Allow-Origin을 보낸다.
- 브라우저는 서버의 허가를 확인 후 본 요청을 보내게 된다.
CORS의 해결방법
- 프론트엔드에서 프록시 이용우선 cors에러는 브라우저를 통과하며 발생합니다.따라서 온전한 서버끼리의 통신에서는 발생하지 않습니다.프론트엔드 단의 웹서버에서 요청을 프록시 형태로 감싸 백엔드 서버로 바로 요청할 경우, 에러가 발생하지 않습니다.
- 백엔드 서버에서 허가백엔드 서버에서 Access-Control-Allow-Origin 응답을 설정하게 하여, 임의로 허가를 내려줄 수 있습니다.
스프링 서버 전역적으로 CORS 설정
static class AppConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/api/**")
.allowedMethods("GET", "POST") //메소드 지정 가능
.allowedOrigins("*"); //와일드 카드: 전체 다 허락
}
}
특정 컨트롤러나 메소드에 개별적 CORS 설정@controller
@CrossOrigin(origins = "*", methods = RequestMethod.GET)
public class customController {
@GetMapping("/url")
//특정 메소드에만 CORS 적용 가능
@CrossOrigin(origins = "*", methods = RequestMethod.GET)
@ResponseBody
public List< > findAll(){
return service.getAll();
}
}
- Chrome 확장 프로그램 이용
https://chrome.google.com/webstore/detail/allow-cors-access-control/lhobafahddgcelffkeicbaginigeejlf
- 서버에서 Access-Control-Allow-Origin 세팅하기
서버에서 해결하기스프링 CORS@CrossOrigin 어노테이션 사용하기메소드 레벨 및 글로벌 레벨에서 srping mvc 애플리케이션에서 spring cors를 지원하는 방법이다. sprign mvc는 @CorssOrigin 어노테이션을 제공한다. 이 어노테이션은 어노테이션이 달린 메소드 또는 타입을 교차 출처를 허용하는 것으로 표시한다.
기본적으로 @crossorigin은 모든 출처, 모든 헤더, @RequestMapping 주석에 지정된 Http 메소드에 최대 30분을 허용한다. 어노테이션에 속성 값을 넣어 기본 값을 대체할 수 있다.
속성값을 살펴보면,
origins허용된 출처, 이 값은 pre-flight 응답과 실제 응답 모두에 access-control-allow-origin헤더에 배치된다.allowedHeaders실제 요청 중에 사용할 수 있는 요청 헤더 목록이다. pre-flight의 응답 헤더인 access-control-allow-header에 값이 사용된다.allowCredential브라우저가 요청과 관련된 쿠키를 포함해야 되는지 여부를 결정한다.이 값이 true이면, pre-flight 응답에는 값이 true로 설정된 access-control-allow-credentials 헤더가 포함된다.
@CrossOrigin(origin="*", allowedHeaders = "*")
@Controller
public class MainController {
@GetMapping(path = "/")
public String main(Model model) {
return "main";
}
}
지연로딩과 즉시로딩
지연로딩과 즉시로딩을 알아보기 전에 프록시를 알아야 했다.그래서 프록시에 대해 직접 정리한 내용을 그대로 가지고 와서 활용했다.
객체는 객체 그래프로 연관된 객체들을 탐색한다.JPA 구현체들은 이 문제를 해결하기 위해 프록시라는 기술을 사용한다.프록시를 사용하면 연관된 객체를 처음부터 데이터베이스에서 조회하는 것이 아니라실제 사용하는 시점에 데이터베이스에서 조회할 수 있다.하지만 자주 함께 사용하는 객체들은 조인을 사용해서 함께 조회하는 것이 효과적이다.JPA는 즉시 로딩과 지연 로딩이라는 방법으로 둘을 모두 지원한다.
영속성 전이와 고아객체
JPA는 연관된 객체를 함께 저장하거나 함께 삭제할 수 있는 영속성 전이와 고아 객체 제거라는 편리한 기능을 제공한다.
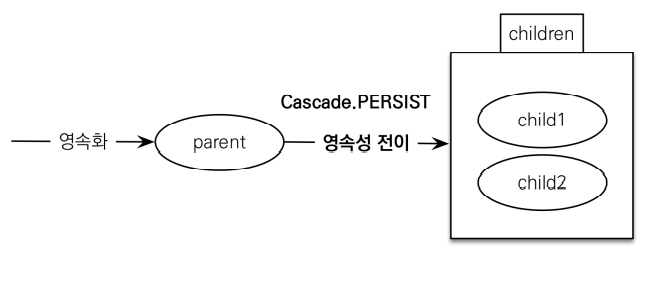
영속성 전이:CASCADE
- 특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들고 싶을 때
- 예 : 부모 엔티티를 저장할 대 자식 엔티티도 함께 저장
영속성 전이:저장
@onetomany(mappedBy="parent", cascade=CascadeType.PERSIST)
영속성 전이 : CASCADE- 주의사항
- 영속성 전이는 연관관계를 매핑하는 것과 아무 관련이 없음
- 엔티티를 영속화할 때 연관된 엔티티도 함께 영속화하는 편리함을 제공할 뿐
프록시 초기화 과정
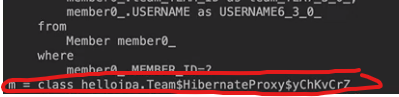
프록시 객체에 member.getrName()을 호출해서 실제 데이터를 조회프록시 객체는 실제 엔티티가 생성되어 있지 않으면 영속성 컨텍스트에 실제 엔티티 생성을 요청하는데 이것을 초기화라고 한다.영속성 컨텐스트는 데이터베이스를 조회해서 실제 엔티티 객체를 생성한다.프록시 객체는 생성된 실제 엔티티 객체의 참조를 Member target 멤버변수에 보관한다.프록시 객체는 실제 엔티티 객체의 getName()을 호출해서 결과를 반환한다.
프록시엔티티를 조회할 때 연관된 엔티티들이 항상 사용되는 것은 아니다.예를 들어 회원엔티티를 조회할 때 연관된 팀 엔티티는 비즈니스 로직에 따라 사용될 때도 있지만 그렇지 않을 때도 있다.
public void printUserAndTeam(String memberId) {
Member member = em.find(Member.class,memberId);
Team team = member.getTeam();
}
printUserAndTeam() 메소드는 memberId로 회원 엔티티를 찾아서 회원과 연관된 팀의 이름도 출력한다.
public String printUser(String memberId) {
Member member = em.find(Member.class, memberId);
}
printUser() 메소드는 회원 엔티티만 사용하므로 em.find()로 회원 엔티티를 조회할 대 회원과 연관된 팀 엔티티까지 데이터베이스에서 함께 조회해 두는 것은 효율적이지 않다.
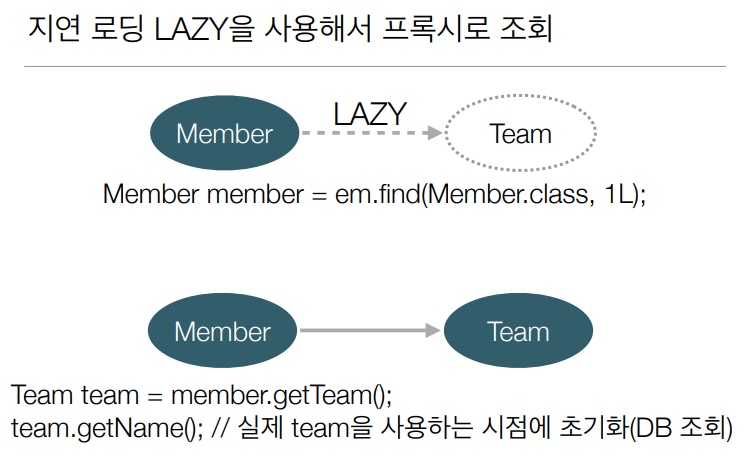
JPA는 이런 문제를 해결하기 위해 엔티티가 실제 사용될 때까지 데이터베이스 조회를 지연하는 방법을 제공하는데 이것을 지연로딩이라고 한다.
지연로딩 기능을 사용하려면 실제 엔티티 객체 대신에 데이터베이스 조회를 지연할 수 있는 가짜 객체가 필요한데 이것을 프록시 객체라고 한다.
ref
JPA 표준 명세는 지연 로딩의 구현 방법을 JPA구현체에 위임했다.하이버네이트는 지연 로딩을 지원하기 위해 프록시를 사용하는 방법과 바이트 코드를 수정하는 두 가지 방법을 제공한다.
프록시 기초
JPA에서 식별자로 엔티티 하나를 조회할 때는 EntityManager.find() 를 사용한다이 메소드는 영속성 컨텐스트에 엔티티가 없으면 데이터베이스를 조회한다.
Member member = em.find(Member.class, "member1");엔티티를 실제 사용하는 시점까지 데이터 베이스 조회를 미루고 싶으면 EntityManager.getReference() 메소드를 사용하면 된다.
Member member = em.getReference(Member.class,"member1")JPA는 데이터베이스를 조회하지 않고 실제 엔티티 객체도 생성하지 않는다.
프록시의 특징
프록시 객체는 처음 사용할 때 한 번만 초기화된다.프록시 객체를 초기화한다고 프록시 객체가 실제 엔티티로 바뀌는 것은 아니다.프록시 객체가 초기화되면 프록시 객체를 통해서 실제 엔티티에 접근할 수 있다.프록시 객체는 원본 엔티티를 상속받은 객체이므로 타입 체크 시에 주의해서 사용한다.영속성 컨텍스트에 찾는 엔티티가 이미 있으면 데이터 베이스를 조회할 필요가 없으므로 em.getReference()를 호출해도 프록시가 아닌 실제 엔티티를 반환한다.초기화는 영속성 컨텍스트의 도움을 받아야 가능하다. 따라서 영속성 컨텍스트의 도움을 받을 수 없는 준영속 상태의 프록시를 초기화하면 문제가 발생한다.
지연로딩 동작원리
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne(fetch = FetchType.LAZY) //**
@JoinColumn(name = "TEAM_ID")
private Team team;
..
}
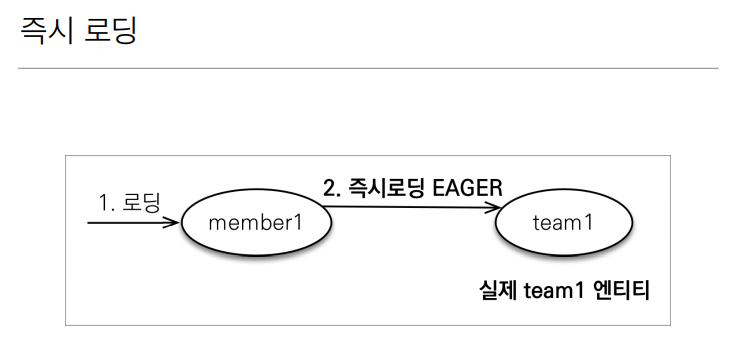
@manytoone(fetch = FetchType.LAZY)단순히 한가지 정보만 사용하는 비즈니스 로직이라면 두 개의 정보를 조회할 때 DB에서 큰 손실을 보인다. 그래서 JPA에서는 LAZY라는 옵션을 제공한다.
위 예제코드처럼 작성할 경우 아래 Team 객체는 프록시 객체로 조회한다.
즉시로딩 동작원리
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne(fetch = FetchType.EAGER) //**
@JoinColumn(name = "TEAM_ID")
private Team team;
..
}
프록시와 즉시로딩에서 주의할 점
- 가급적 지연 로딩만 사용할 것
- 즉시 로딩을 적용하면 예상하지 못한 SQL이 발생한다.
- 즉시 로딩은 JPQL에서 N+1 문제를 일으킨다.
- @manytoone, @OnetoOne은 기본이 즉시 로딩 -> LAZY로 설정!
- @onetomany, @manytomany는 기본이 지연 로딩
N+1 쿼리 문제의 원인 ?
Spring Data JPA에서 제공하는 Repository의 ‘findAll()’, ‘findById()’ 등과 같은 메소드를 사용하면 바로 DB에 SQL 쿼리를 날리는 것이 아닙니다.
JPQL이라는 객체지향 쿼리 언어를 생성, 실행시킨 후 JPA는 이것을 분석해서 SQL을 생성, 실행하는 동작에서 N+1 쿼리 문제가 발생합니다.
JPQL 입장에서는 LAZY 로딩, EAGER 로딩과 같은 글로벌 패치 전략을 신경쓰지 않고 JPQL만 사용해서 SQL을 생성합니다.
N+1 쿼리 문제는 언제 발생할까 ?
발생하는 경우는 다음과 같은 2가지 경우가 있습니다.
두 개의 엔티티가 1:N 관계를 가지며 JPQL로 객체를 조회할 때
EAGER 전략으로 데이터를 가져오는 경우LAZY 전략으로 데이터를 가져온 이후에 가져온 데이터에서 하위 엔티티를 다시 조회하는 경우

요약
많은 블로그 글들, 강의 등을 보고 요약하면서 알게 된 것은 결국 DB를 조회하는 데에도 각 객체마다 하나씩 조회하는 것이어야될까 하는 생각이 들었다. 지연로딩을 왠만하면 권장해야겠고,우선 최초 엔티티 설계 시에는 LAZY로딩으로 설정해두어야겠다.
이를 해결하기 위한 방법이 3가지가 있는데
- JPQL의 FETCH JOIN(실무에서 많이 쓰인다고 함)
- 기존 SQL의 조인이 아님JPQL의 성능 튜닝을 위해 제공되는 조인연관된 엔티티 or 컬렉션을 SQL 한번에 함께 조회하는 기능
- Entity Graph엔티티 조회시점에 연관된 엔티티들을 함께 조회하는 기능- 정적으로 정의하는 Named 엔티 티 그래프- 동적으로 정의하는 엔티티 그래프
- 여러 자식들이 있을때 N+1 문제를 회피하기 위해hibernate.default_batch_fetch_size 옵션 활용이 batch-size 옵션은 하위 엔티티를 로딩할때 한번에 상위 엔티티 ID를 지정한 숫자만큼 in Query로 로딩한다.
해결방안에 대해서만 알아보았고, 실제로 적용은 해보지 못했는데, 차근차근 해봐야겠다...