Bohan Jia1*, Wenxuan Huang1,4*, Yuntian Tang1*, Junbo Qiao1, Jincheng Liao1, Shaosheng Cao2†, Fei Zhao2, Zhaopeng Feng5, Zhouhong Gu6, Zhenfei Yin7, Lei Bai8, Wanli Ouyang4, Lin Chen9, Fei Zhao10, Yao Hu2, Zihan Wang1, Yuan Xie1, Shaohui Lin1,3†
1East China Normal University 2Xiaohongshu Inc. 3KLATASDS-MOE 4The Chinese University of Hong Kong 5Zhejiang University 6Fudan University 7University of Oxford 8Shanghai Jiao Tong University 9University of Science and Technology of China 10Nanjing University
* Equal contribution † Corresponding author
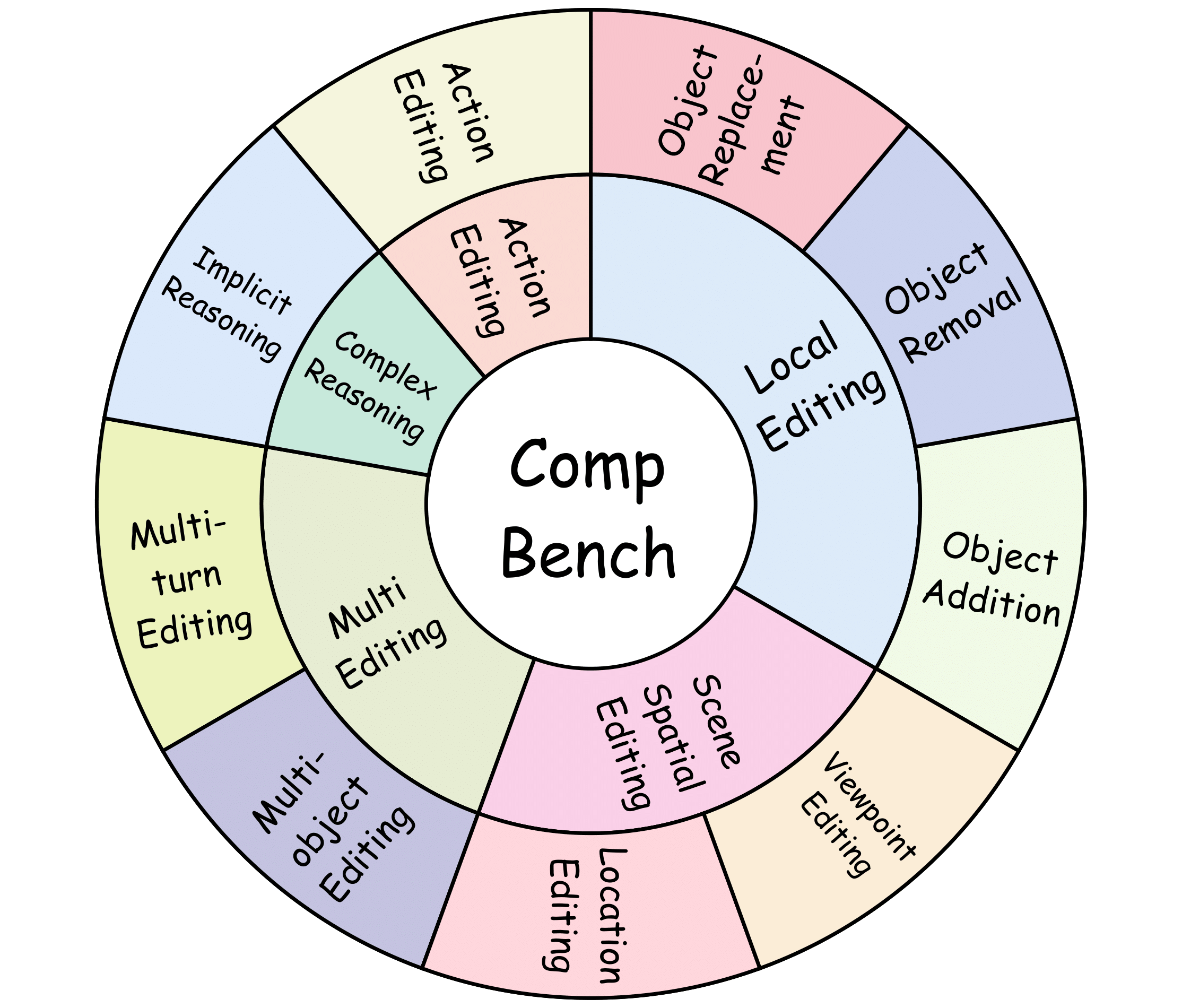
CompBench covers 9 editing tasks spanning 5 major categories, featuring fine-grained, complex instructions that challenge state-of-the-art image editing models.
- [2026-04] CompBench is accepted to CVPR 2026 as a poster presentation.
- [2025-05] Paper released on arXiv.
- [2025-05] Dataset released on HuggingFace.
- [2025-05] Project page live at comp-bench.github.io.
While real-world applications increasingly demand intricate scene manipulation, existing instruction-guided image editing benchmarks often oversimplify task complexity and lack comprehensive, fine-grained instructions. To bridge this gap, we introduce CompBench, a large-scale benchmark specifically designed for complex instruction-guided image editing.
CompBench features challenging editing scenarios that incorporate fine-grained instruction following, spatial and contextual reasoning, thereby enabling comprehensive evaluation of image editing models' precise manipulation capabilities. We propose an MLLM-human collaborative framework with tailored task pipelines, and an instruction decoupling strategy that disentangles editing intents into four key dimensions: location, appearance, dynamics, and objects.
Extensive evaluations reveal that CompBench exposes fundamental limitations of current image editing models and provides critical insights for next-generation instruction-guided image editing.
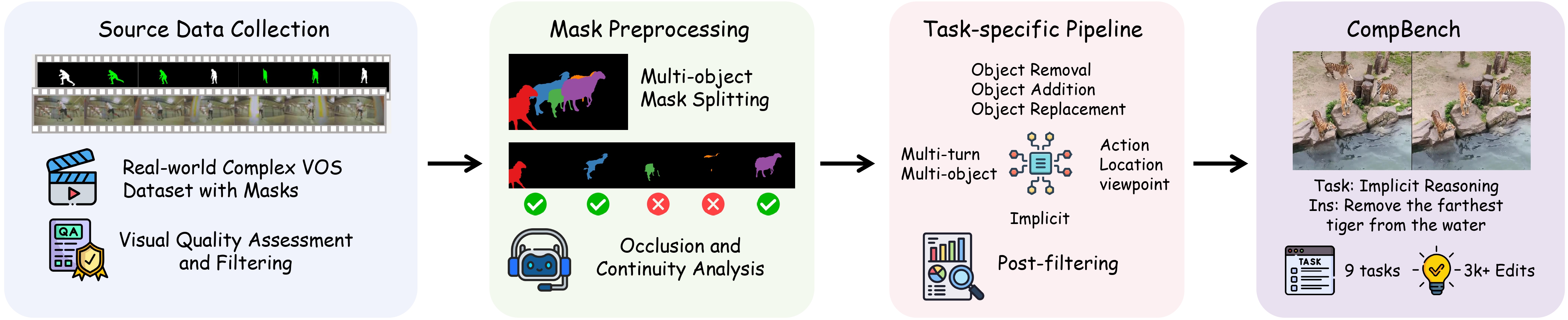
Overview of the MLLM-human collaborative data construction pipeline.
CompBench organizes editing into 5 major categories covering 9 distinct tasks:
| Category | Tasks | Description |
|---|---|---|
| Local Editing | Object Removal, Addition, Replacement | Precise object-level manipulation within a scene |
| Multi-editing | Multi-turn Editing, Multi-object Editing | Chained or simultaneous edits across multiple targets |
| Action Editing | Dynamic State Modification | Modifying object actions, poses, and dynamic states |
| Scene Spatial Editing | Location Editing, Viewpoint Editing | Spatial repositioning and perspective change |
| Complex Reasoning | Implicit Reasoning | Edits requiring contextual or commonsense inference |
Examples of action, location, and viewpoint editing tasks.
Examples of local editing tasks (removal, addition, replacement).
| Statistic | Value |
|---|---|
| Total image-instruction pairs | 3,000+ |
| Editing task categories | 5 |
| Distinct editing tasks | 9 |
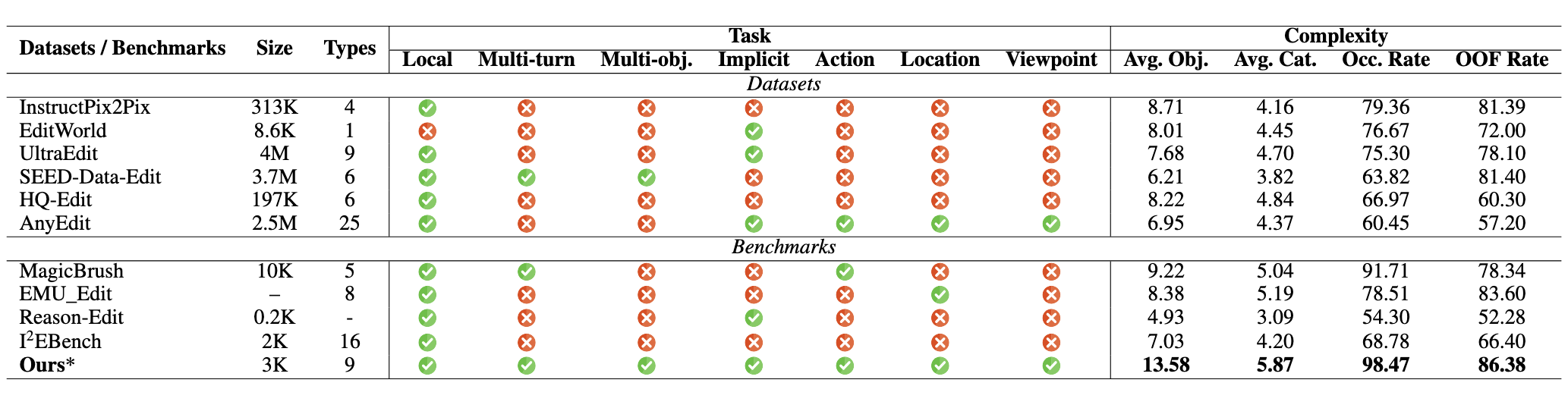
| Average objects per image | 13.58 |
| Occlusion rate | 98.47% |
| Out-of-frame rate | 86.38% |
| Models evaluated | 15+ |
The high occlusion and out-of-frame rates reflect the real-world complexity of CompBench scenes, making it significantly more challenging than prior benchmarks.
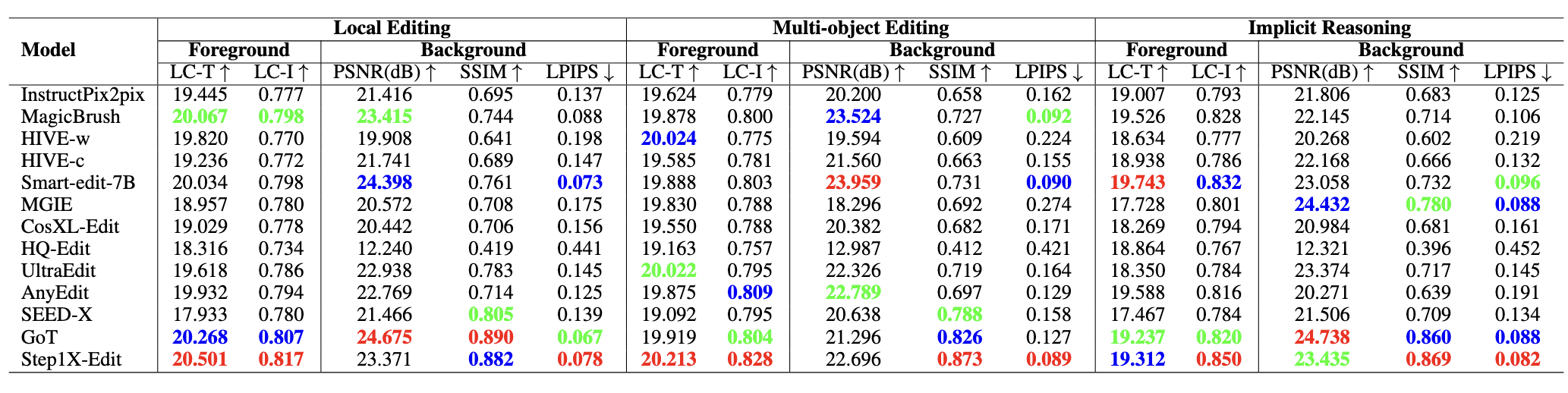
CompBench uses a suite of complementary metrics to capture both editing quality and background preservation:
| Metric | Name | Measures |
|---|---|---|
| LC-T | Local CLIP Text Score | Instruction-following fidelity in the edited region |
| LC-I | Local CLIP Image Similarity | Edited region accuracy compared to ground truth |
| PSNR | Peak Signal-to-Noise Ratio | Background reconstruction quality |
| SSIM | Structural Similarity Index | Structural fidelity of background |
| LPIPS | Learned Perceptual Image Patch Similarity | Perceptual background consistency |
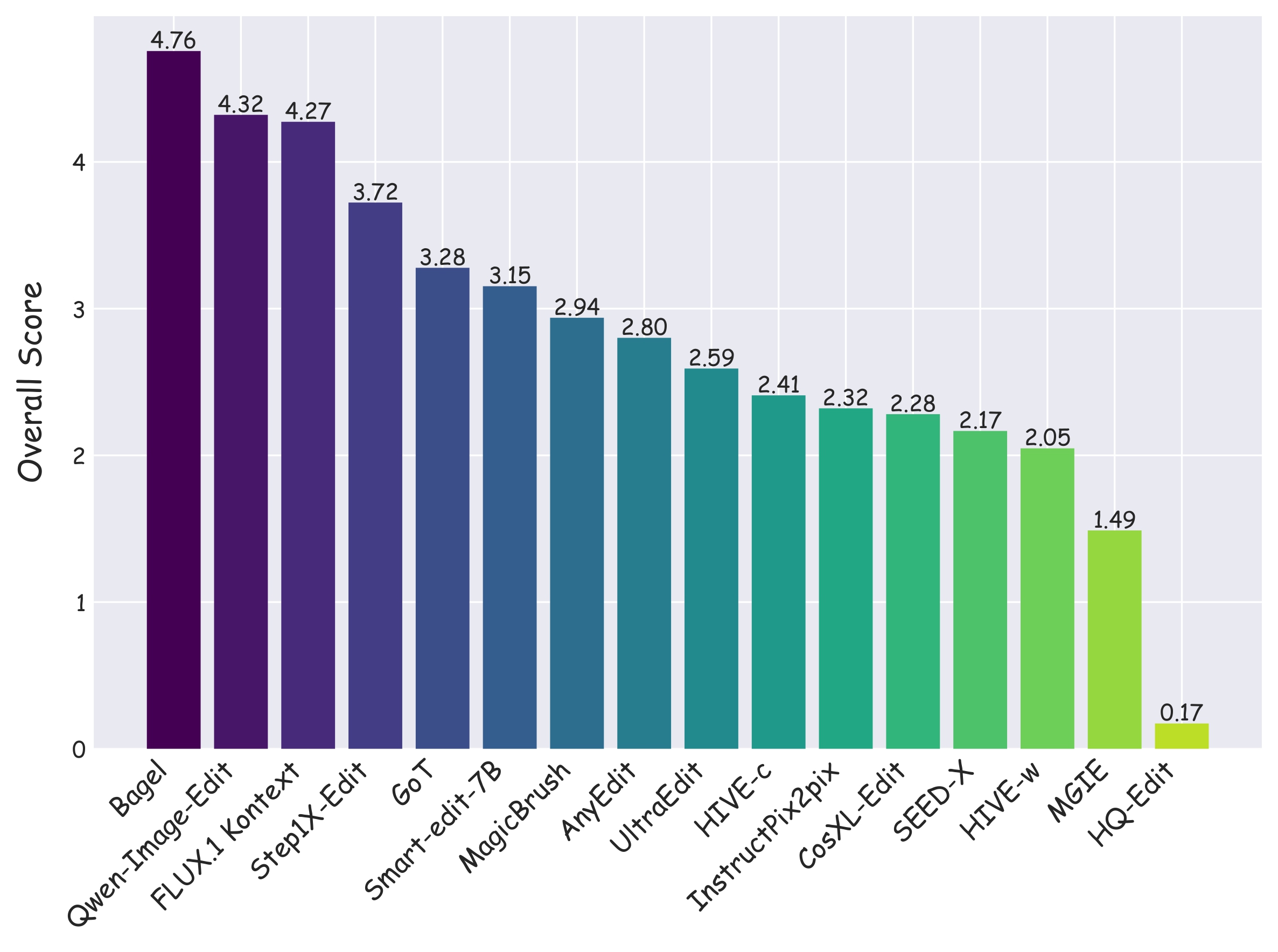
Overall model ranking across all CompBench tasks.
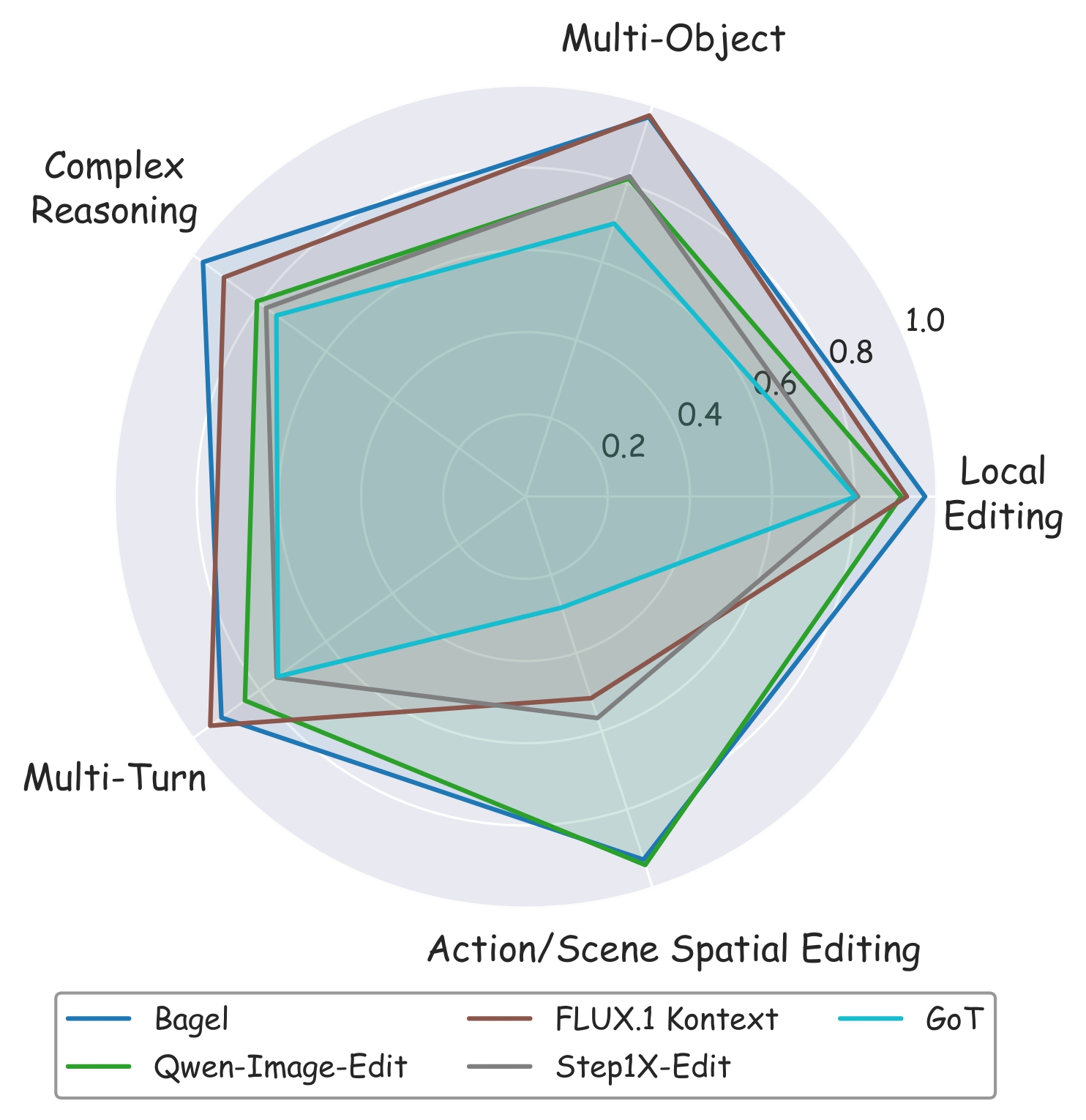
Radar chart comparing top-performing models across evaluation dimensions.

SSIM comparison bubble chart across evaluated models.
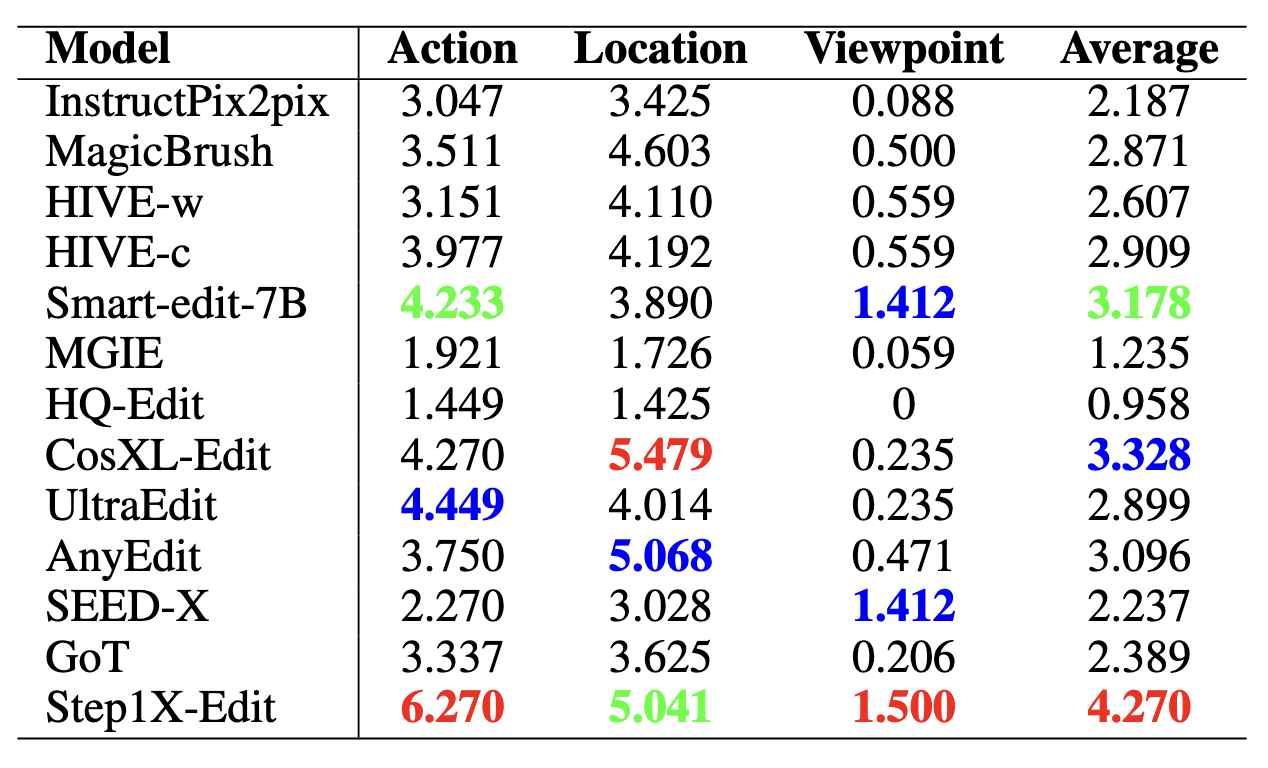
CompBench evaluates 15+ models spanning the full spectrum of instruction-guided image editing, from early approaches (InstructPix2pix) to the latest generation (FLUX.1 Kontext, Bagel, Qwen-Image-Edit). Results demonstrate that even state-of-the-art models struggle with complex, fine-grained editing instructions, highlighting the benchmark's discriminative power.
Qualitative comparison of editing results across models on representative CompBench samples.
Requirements: Python 3.8+, PyTorch with CUDA support recommended.
# Clone the repository
git clone https://github.com/BhJia/CompBench.git
cd CompBench
# Install dependencies
pip install torch torchvision
pip install torchmetrics[multimodal] transformers pillow tqdm pandas numpyDownload the CompBench dataset from HuggingFace to your local filesystem:
python download_from_hf.pyThis script fetches the dataset from BohanJia/CompBench and organizes it into the expected local directory structure under ./tasks/.
The dataset is organized by task:
tasks/
├── add/ # Object addition
├── remove/ # Object removal
├── replace/ # Object replacement
├── act_loc_view/ # Action, location, viewpoint editing
├── implicit_reasoning/ # Complex reasoning
└── multi_turn_editing/ # Multi-turn editing
Each task directory contains source images, editing instructions, segmentation masks, and ground-truth edited images.
Place your model's edited images under ./editing_results/ following this structure:
editing_results/
└── <model_name>/
└── <task_name>/
└── <image_id>.png
python eval_all.py \
--model_names model1 model2 \
--tasks all \
--metric all \
--data_root ./tasks \
--results_root ./editing_results \
--output_dir ./eval_results \
--resumeSee eval_all.sh for a concrete example with multiple models and metrics.
Arguments:
| Argument | Description | Default |
|---|---|---|
--model_names |
Space-separated list of model names to evaluate | required |
--tasks |
Task(s) to evaluate (all or specific task names) |
all |
--metric |
Metric(s) to compute (all, LC-T, LC-I, PSNR, SSIM, LPIPS) |
all |
--data_root |
Path to the dataset root directory | ./tasks |
--results_root |
Path to model editing results | ./editing_results |
--output_dir |
Directory to save evaluation outputs | ./eval_results |
--resume |
Skip already-evaluated samples | flag |
python download_from_hf.pyDownloads the full CompBench dataset from HuggingFace Hub to the local ./tasks/ directory.
python update_hf_dataset.pySyncs local metadata changes back to the HuggingFace dataset repository. Useful for maintainers contributing new annotations or corrections.
CompBench/
├── tasks/ # Dataset organized by editing task
│ ├── add/
│ ├── remove/
│ ├── replace/
│ ├── act_loc_view/
│ ├── implicit_reasoning/
│ └── multi_turn_editing/
├── eval_all.py # Main evaluation script
├── eval_all.sh # Example evaluation command
├── download_from_hf.py # Download dataset from HuggingFace
└── update_hf_dataset.py # Sync local metadata to HuggingFace
If you find CompBench useful in your research, please consider citing:
@article{jia2025compbench,
title={Compbench: Benchmarking complex instruction-guided image editing},
author={Jia, Bohan and Huang, Wenxuan and Tang, Yuntian and Qiao, Junbo and Liao, Jincheng and Cao, Shaosheng and Zhao, Fei and Feng, Zhaopeng and Gu, Zhouhong and Yin, Zhenfei and others},
journal={arXiv preprint arXiv:2505.12200},
year={2025}
}For questions or feedback, please open an issue on GitHub or reach out via the project page.