ATM {job} for appveyor is a random ID, e.g.
$> ls logs/2021/06/*/pr/**/*appveyor-*/*
logs/2021/06/01/pr/68/c30b87e7/03f35ebb-appveyor-132/8ka4r2bfy28kipyr.txt logs/2021/06/07/pr/71/3e24e039/edd97c55-appveyor-137/bnyb0100ojmie5n5.txt
logs/2021/06/01/pr/68/c30b87e7/03f35ebb-appveyor-132/cngwpof9ihphuvyt.txt logs/2021/06/07/pr/71/3e24e039/edd97c55-appveyor-137/h524mgca9jbet68x.txt
logs/2021/06/01/pr/68/c30b87e7/03f35ebb-appveyor-132/oc8g6obu4gi6xxkb.txt logs/2021/06/07/pr/71/3e24e039/edd97c55-appveyor-137/h5rwrienuauavg9n.txt
logs/2021/06/01/pr/68/c30b87e7/03f35ebb-appveyor-132/xc522ci6wtm7esb9.txt logs/2021/06/07/pr/71/3e24e039/edd97c55-appveyor-137/nuaxlqmm2a3k5ywa.txt
logs/2021/06/04/pr/71/47613d0b/8c34e069-appveyor-135/05r1wg627kdsj1dm.txt logs/2021/06/07/pr/71/9c9adf52/a3c03a3c-appveyor-139/4rcps2npvjhvg1ba.txt
logs/2021/06/04/pr/71/47613d0b/8c34e069-appveyor-135/9xnjwambkfmlib39.txt logs/2021/06/07/pr/71/9c9adf52/a3c03a3c-appveyor-139/735h1h87bvd7d4qn.txt
logs/2021/06/04/pr/71/47613d0b/8c34e069-appveyor-135/d4rkdri3olfb8qsd.txt logs/2021/06/07/pr/71/9c9adf52/a3c03a3c-appveyor-139/lyrb1piy4prjnpss.txt
logs/2021/06/04/pr/71/47613d0b/8c34e069-appveyor-135/r1vuvjda4xnnj3pn.txt logs/2021/06/07/pr/71/9c9adf52/a3c03a3c-appveyor-139/vag7vdn5j02adudj.txt
so it is impossible to correspond jobs for the "same" run (the same environment/setup) across builds.
For appveyor I guess we could just enumerate across them (if their order is as in the table reported by appveyor so should stay consistent across builds unless matrix changes). That would bring it closer to what we have for Travis's {job} I guess, and for consistency we could name it {job_index} and even have it also for github actions I think since they also have some index prefixed.
But again -- those indexes could change if something about setup/matrix changes so wouldn't be convenience for longitudinal analysis across time points. I still think they are worth adding, but documentation for {job_index} should mention that they might change through time whenever matrix of runs changes etc.
Both Travis and Appveyor in their display show env setup. E.g. travis:
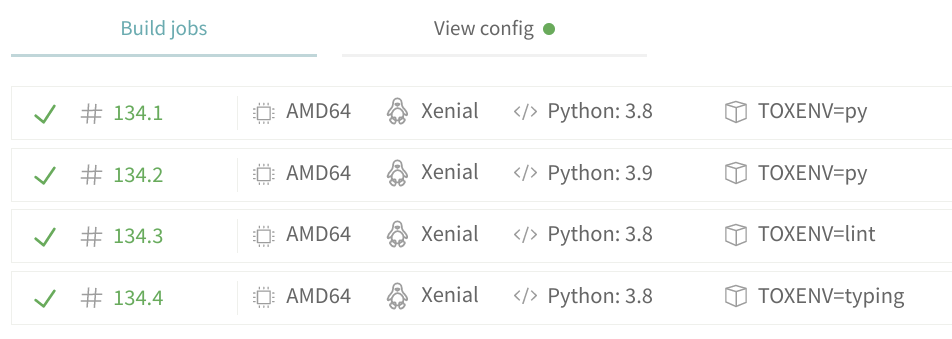
and appveyor:

although for some projects it could become quite wild as in
https://ci.appveyor.com/project/mih/datalad/builds/39494084
Thus I think it would be worthwhile to equip with both
{job_env} -- _ joined strs of env vars e.g. PY=3.8_TOXENV=py in the above example. Note that for travis it should also include architecture and base image, not just env vars. Then I could even use {job_index}-{job_env} and have them nicely ordered and still grep through time ignoring index if needed etc.{job_env_hash} -- some shortish hash [*] of the {job_env} so for projects like datalad I could use that one instead since full listing might get too wild.
this way I could create persistent (across builds, and even changes to matrix) IDs for appveyor and travis jobs to e.g. grep results through time.
[*] e.g. in dandi-cli we use np.base_repr(binascii.crc32(object_id.encode("ascii")), 36).lower() but we do not want to drag np here , so needs some tune up
ATM
{job}for appveyor is a random ID, e.g.so it is impossible to correspond jobs for the "same" run (the same environment/setup) across builds.
For appveyor I guess we could just
enumerateacross them (if their order is as in the table reported by appveyor so should stay consistent across builds unless matrix changes). That would bring it closer to what we have for Travis's{job}I guess, and for consistency we could name it{job_index}and even have it also for github actions I think since they also have some index prefixed.But again -- those indexes could change if something about setup/matrix changes so wouldn't be convenience for longitudinal analysis across time points. I still think they are worth adding, but documentation for
{job_index}should mention that they might change through time whenever matrix of runs changes etc.Both Travis and Appveyor in their display show env setup. E.g. travis:

and appveyor:

although for some projects it could become quite wild as in
https://ci.appveyor.com/project/mih/datalad/builds/39494084
Thus I think it would be worthwhile to equip with both
{job_env}--_joined strs of env vars e.g.PY=3.8_TOXENV=pyin the above example. Note that for travis it should also include architecture and base image, not just env vars. Then I could even use{job_index}-{job_env}and have them nicely ordered and still grep through time ignoring index if needed etc.{job_env_hash}-- some shortish hash [*] of the{job_env}so for projects like datalad I could use that one instead since full listing might get too wild.this way I could create persistent (across builds, and even changes to matrix) IDs for appveyor and travis jobs to e.g. grep results through time.
[*] e.g. in dandi-cli we use
np.base_repr(binascii.crc32(object_id.encode("ascii")), 36).lower()but we do not want to dragnphere , so needs some tune up