![]()
![]()
A standard for structured Markdown Second Brain vaults: a folder of .md files with YAML frontmatter, organized into six base PARA-style layers (extensible).
brainkeeper sits between AI agents and your notes. The Model Context Protocol (MCP) server enforces the vault spec on every read and write that agents make, while you keep editing files directly with Obsidian, VS Code, or any text editor.
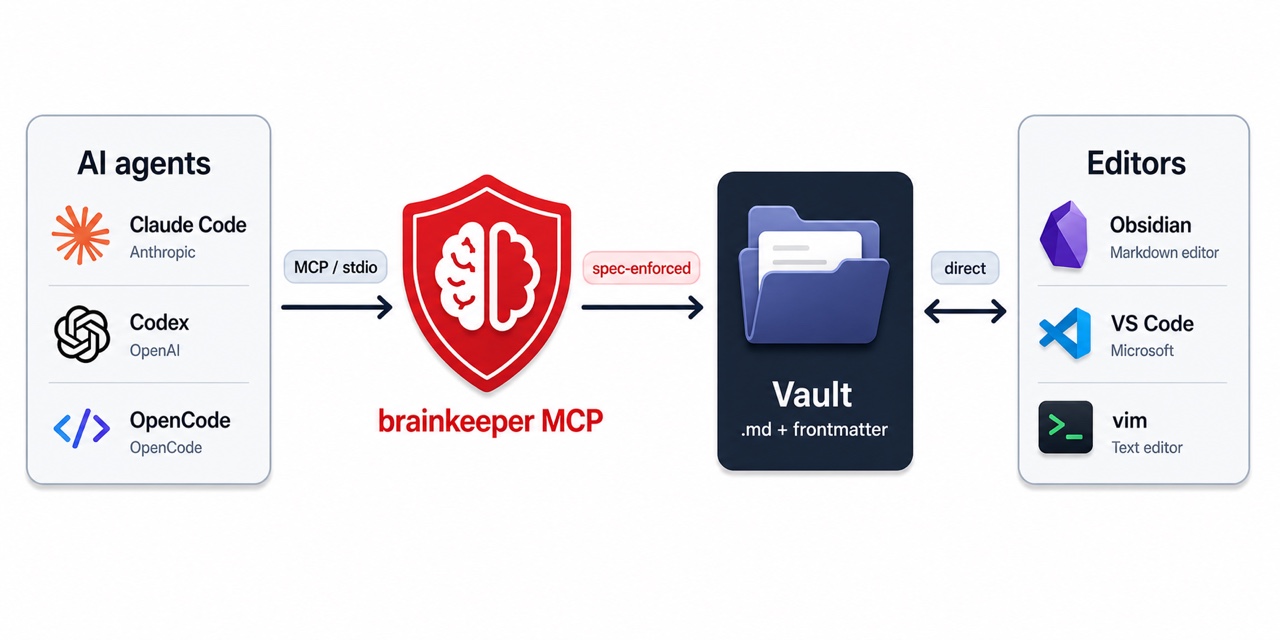
The vault is just a folder of Markdown. You could skip brainkeeper entirely and point an agent at it with filesystem tools. That works for the first few notes. By the tenth, consistency starts to break: similar notes land in different folders, tags drift between forms (pkm vs topic/pkm), some files carry rich metadata and others have none, "deleted" notes keep their active status forever, and your edits race against the agent's. By the hundredth note, a second problem shows up: the agent has to scan the whole vault on every query, which gets slow and eats its context window with file paths and irrelevant content.
brainkeeper prevents both. Every read and write the agent does goes through the MCP, which validates writes against the spec and serves reads from a live in-memory index. Conventions hold no matter how the agent's session went last time, and lookups stay fast even as the vault grows past thousands of notes.
| Without brainkeeper | With brainkeeper |
|---|---|
| Each note has its own structure | Every note follows the same structure |
| The agent guesses which folder a note belongs to | Notes land in the right folder automatically |
| Timestamps drift or get forgotten | Dates set on creation, refreshed on edit |
| Deleting a note loses it | Deleted notes archive by year, with lifecycle preserved |
| Your edits and the agent's overwrite each other | The agent can't overwrite changes you just made |
| Searching the vault gets slower the more notes you have | Lookups stay fast at any vault size |
Telling an LLM "follow these conventions" works inconsistently across sessions and degrades over time. brainkeeper enforces them at the protocol boundary, so the conventions hold whether the agent remembers them or not. Humans (and editors like Obsidian or VS Code) keep writing to the vault directly; only the agent side gets mediated.
The recommended way to run brainkeeper is with uvx, which fetches and executes the package on demand without polluting your environment:
# No install needed; uvx handles it.
uvx brainkeeper --helpIf you prefer a persistent install:
pip install brainkeeperEither way, you need Python 3.11 or newer.
If you don't already have a brainkeeper vault, create one:
uvx brainkeeper init ~/MyVaultThis creates the six layer directories and drops a brainkeeper.yaml (the minimal reference config) at the vault root. Open the YAML to adjust folder names and area substructure to taste. Validate against the schema at any time:
uvx check-jsonschema \
--schemafile https://raw.githubusercontent.com/dasirra/brainkeeper/main/spec/schema/brainkeeper.schema.json \
~/MyVault/brainkeeper.yamlThe MCP server is launched by your LLM harness over stdio. Pick the snippet for your client.
Claude Code (one command):
claude mcp add --scope user brainkeeper -- uvx brainkeeper serve --vault ~/MyVaultClaude Desktop: edit the config file at
- macOS:
~/Library/Application Support/Claude/claude_desktop_config.json - Windows:
%APPDATA%/Claude/claude_desktop_config.json
and add:
{
"mcpServers": {
"brainkeeper": {
"command": "uvx",
"args": ["brainkeeper", "serve", "--vault", "/Users/you/MyVault"]
}
}
}Then restart Claude Desktop. Use an absolute path; ~ is not expanded inside this JSON.
Other clients: any MCP-capable harness that speaks stdio works. The command is uvx brainkeeper serve --vault /absolute/path/to/vault (or brainkeeper serve --vault ... if you pip installed).
Once your client restarts, the LLM gains a brainkeeper toolset (mcp__brainkeeper__list_layers, mcp__brainkeeper__find_by_tag, etc.). Ask it something like "list the layers in my vault" or "find all notes tagged pkm" to confirm the connection.
The brainkeeper distribution installs four Python modules:
| Module | Purpose |
|---|---|
brainkeeper.core |
Vault engine: parser, validator, indexer, atomic writer. Usable as a library. |
brainkeeper.mcp |
FastMCP server that exposes the vault to LLMs over stdio. |
brainkeeper.cli |
The brainkeeper command (init, serve). |
brainkeeper.spec |
Bundled spec data: SPEC.md, JSON Schema, reference configs. |
The CLI is the user surface. The MCP server is what your LLM talks to. The library is for anyone building their own tooling on top of brainkeeper-shaped vaults.
The server registers thirteen tools across three layers. All vault access goes through these; bypassing them with raw filesystem tools produces non-compliant data.
Primitives (file operations):
| Tool | Description |
|---|---|
read_note |
Read a note. Returns parsed frontmatter, body, and mtime. |
list_notes |
List managed notes, optionally filtered by layer or path glob. |
write_note_atomic |
Create or overwrite a note. Auto-fills created and updated. |
move_note |
Move or rename a note. Does not rewrite wikilinks (v1 limitation). |
delete_note |
Delete a note. soft=True (default) moves it to <archive>/<YYYY>/. |
Convention (spec-aware lookups):
| Tool | Description |
|---|---|
read_convention |
Return the parsed brainkeeper.yaml. |
list_layers |
Resolve the six canonical layer keys to their on-disk folder names. |
get_template |
Fetch a per-layer template from <layer>/_templates/. |
Semantic (spec-level queries):
| Tool | Description |
|---|---|
find_by_tag |
Find notes by tag. Prefix match by default; exact match optional. |
find_orphans |
List notes that fail spec validation. |
validate_frontmatter |
Validate a single note against the spec contract. |
update_frontmatter |
Patch frontmatter fields on an existing note. Refreshes updated. |
list_tags |
List all tags in the vault, optionally filtered by prefix. |
The server's instructions block (sent to every connected client) covers the recommended workflow and the access rule.
In addition to tools, the server exposes prompts (slash commands the user invokes from their MCP client):
| Prompt | Description |
|---|---|
triage_inbox |
Walk the inbox layer and propose a destination for each managed note. |
The format and lifecycle rules live in spec/SPEC.md. It is a standalone document. You do not need this Python package to build a brainkeeper-compatible tool: implement against the spec, validate brainkeeper.yaml against the JSON Schema, and you can interoperate.
The current spec version is v0.1.4. See CHANGELOG.md for revision history. Spec and package version independently.
This is the first public release. Known constraints:
- One vault per server instance. Each MCP process serves a single
--vault. Multi-vault setups need multiple server entries in your client config. move_notedoes not rewrite wikilinks. Inbound links to a moved note become stale until you fix them manually. Planned for a later release.- No always-on indexing. The MCP runs only while its host (Claude Code, Claude Desktop, etc.) is running. There is no background daemon.
- The MCP encodes the spec contract. If you let an LLM use raw filesystem tools (Read, Write, Edit) on the vault path, it will produce notes that violate the frontmatter contract or land in the wrong layer. Tell your agent to use only the brainkeeper tools when working inside the vault.
brainkeeper/
├── spec/ # the standard (versioned independently)
│ ├── SPEC.md
│ ├── schema/ # JSON Schema for brainkeeper.yaml
│ └── examples/ # reference configs
├── src/brainkeeper/
│ ├── core/ # vault engine library
│ ├── mcp/ # MCP server + tools/
│ ├── cli/ # `brainkeeper` command
│ └── spec/ # bundled spec assets (installed alongside code)
├── tests/
├── docs/ # design notes, plans
│ └── branding/ # logo and brand assets
├── pyproject.toml
├── CHANGELOG.md
└── README.md
- Spec:
spec/SPEC.md - Changelog:
CHANGELOG.md - Issues: https://github.com/dasirra/brainkeeper/issues
- Repository: https://github.com/dasirra/brainkeeper
MIT. See LICENSE.