Fix transform to support multi-index columns.#800
Conversation
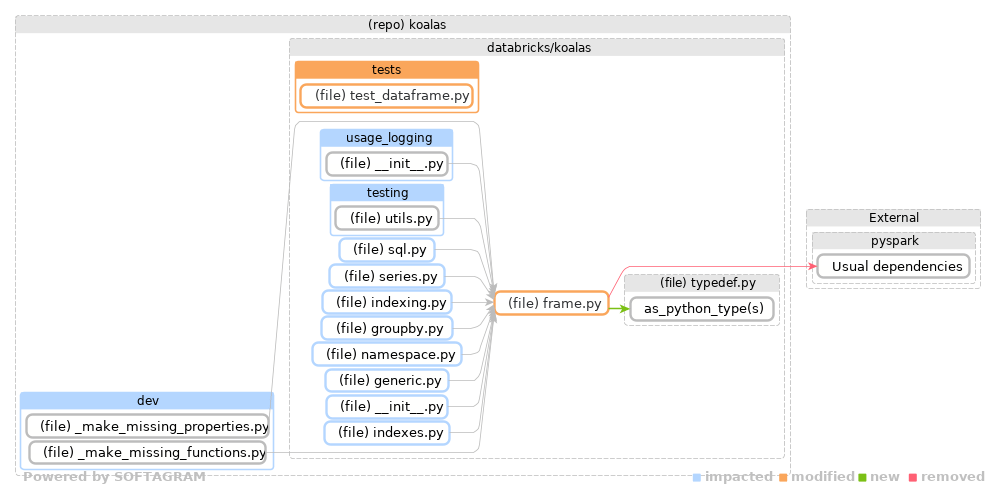
Softagram Impact Report for pull/800 (head commit: a90966b)⭐ Change Overview
📄 Full report
Impact Report explained. Give feedback on this report to support@softagram.com |
Codecov Report
@@ Coverage Diff @@
## master #800 +/- ##
==========================================
- Coverage 94.3% 92.03% -2.27%
==========================================
Files 32 32
Lines 5828 5827 -1
==========================================
- Hits 5496 5363 -133
- Misses 332 464 +132
Continue to review full report at Codecov.
|

| from pandas.core.dtypes.inference import is_sequence | ||
| from pyspark import sql as spark | ||
| from pyspark.sql import functions as F, Column | ||
| from pyspark.sql.functions import pandas_udf |
There was a problem hiding this comment.
looks like we don't need this.
There was a problem hiding this comment.
Actually it is used at line 446.
koalas/databricks/koalas/frame.py
Lines 446 to 448 in a90966b
There was a problem hiding this comment.
We can use F.pandas_udf there, but let me merge this for now.
Please feel free to submit the PR if needed.
|
Thanks! merging. |
No description provided.