[BUG] RuntinmeError, exceeds dimension size (1) #1858
Description
Describe the bug
A clear and concise description of what the bug is.
Thank you for reading my issue. I'm trying to use ZeRO-Infinity on AWS EC2 (g4dn.metal, 8GPUs). Model parameter is 40B. Config file and script are below. When training begins, runtime error occurs.
'RuntimeError: start (0) + length (33554432) exceeds dimension size (1).
Why does this error occur? Please tell me what the problem is.
To Reproduce
Steps to reproduce the behavior:
- Go to '...'
- Click on '....'
- Scroll down to '....'
- See error
Expected behavior
A clear and concise description of what you expected to happen.
Traceback (most recent call last):
File "pretrain_gpt2.py", line 134, in <module>
Traceback (most recent call last):
Traceback (most recent call last):
File "pretrain_gpt2.py", line 134, in <module>
File "pretrain_gpt2.py", line 134, in <module>
args_defaults={'tokenizer_type': 'GPT2BPETokenizer'})
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 110, in pretrain
args_defaults={'tokenizer_type': 'GPT2BPETokenizer'})args_defaults={'tokenizer_type': 'GPT2BPETokenizer'})
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 110, in pretrain
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 110, in pretrain
train_data_iterator, valid_data_iterator)
train_data_iterator, valid_data_iterator)train_data_iterator, valid_data_iterator)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 481, in train
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 481, in train
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 481, in train
lr_scheduler) lr_scheduler)
lr_scheduler)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 336, in train_step
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 336, in train_step
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 336, in train_step
backward_step(optimizer, model, loss)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 283, in backward_step
backward_step(optimizer, model, loss)backward_step(optimizer, model, loss)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 283, in backward_step
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 283, in backward_step
model.backward(loss)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
model.backward(loss)model.backward(loss)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/engine.py", line 1659, in backward
return func(*args, **kwargs)return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/engine.py", line 1659, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/engine.py", line 1659, in backward
Traceback (most recent call last):
File "pretrain_gpt2.py", line 134, in <module>
Traceback (most recent call last):
File "pretrain_gpt2.py", line 134, in <module>
Traceback (most recent call last):
File "pretrain_gpt2.py", line 134, in <module>
args_defaults={'tokenizer_type': 'GPT2BPETokenizer'})
args_defaults={'tokenizer_type': 'GPT2BPETokenizer'}) File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 110, in pretrain
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 110, in pretrain
train_data_iterator, valid_data_iterator)
train_data_iterator, valid_data_iterator)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 481, in train
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 481, in train
self.optimizer.backward(loss)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
self.optimizer.backward(loss) return func(*args, **kwargs)
self.optimizer.backward(loss)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2793, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
args_defaults={'tokenizer_type': 'GPT2BPETokenizer'}) return func(*args, **kwargs)
lr_scheduler) File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 110, in pretrain
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2793, in backward
lr_scheduler)return func(*args, **kwargs) File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 336, in train_step
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 336, in train_step
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2793, in backward
train_data_iterator, valid_data_iterator)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 481, in train
backward_step(optimizer, model, loss)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 283, in backward_step
backward_step(optimizer, model, loss)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 283, in backward_step
model.backward(loss)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
lr_scheduler)model.backward(loss)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 336, in train_step
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/engine.py", line 1659, in backward
Traceback (most recent call last):
File "pretrain_gpt2.py", line 134, in <module>
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/engine.py", line 1659, in backward
backward_step(optimizer, model, loss)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 283, in backward_step
model.backward(loss)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
args_defaults={'tokenizer_type': 'GPT2BPETokenizer'})
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 110, in pretrain
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/engine.py", line 1659, in backward
self.loss_scaler.backward(loss.float(), retain_graph=retain_graph)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/fp16/loss_scaler.py", line 53, in backward
Traceback (most recent call last):
File "pretrain_gpt2.py", line 134, in <module>
train_data_iterator, valid_data_iterator)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 481, in train
scaled_loss.backward(retain_graph=retain_graph)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/_tensor.py", line 307, in backward
self.loss_scaler.backward(loss.float(), retain_graph=retain_graph)
self.loss_scaler.backward(loss.float(), retain_graph=retain_graph) File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/fp16/loss_scaler.py", line 53, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/fp16/loss_scaler.py", line 53, in backward
self.optimizer.backward(loss)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
args_defaults={'tokenizer_type': 'GPT2BPETokenizer'})
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 110, in pretrain
return func(*args, **kwargs)
scaled_loss.backward(retain_graph=retain_graph) File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2793, in backward
self.optimizer.backward(loss)
scaled_loss.backward(retain_graph=retain_graph)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/_tensor.py", line 307, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
lr_scheduler) File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/_tensor.py", line 307, in backward
train_data_iterator, valid_data_iterator)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 336, in train_step
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 481, in train
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2793, in backward
lr_scheduler)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 336, in train_step
backward_step(optimizer, model, loss)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 283, in backward_step
backward_step(optimizer, model, loss)
File "/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/megatron/training.py", line 283, in backward_step
self.optimizer.backward(loss)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
model.backward(loss)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
return func(*args, **kwargs) File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/engine.py", line 1659, in backward
model.backward(loss) File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2793, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs) File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
return func(*args, **kwargs) File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/engine.py", line 1659, in backward
self.optimizer.backward(loss)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2793, in backward
self.loss_scaler.backward(loss.float(), retain_graph=retain_graph)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/fp16/loss_scaler.py", line 53, in backward
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 199, in apply
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 199, in apply
scaled_loss.backward(retain_graph=retain_graph)
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/_tensor.py", line 307, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 199, in apply
self.optimizer.backward(loss)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
self.loss_scaler.backward(loss.float(), retain_graph=retain_graph)self.loss_scaler.backward(loss.float(), retain_graph=retain_graph)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/fp16/loss_scaler.py", line 53, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/fp16/loss_scaler.py", line 53, in backward
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2793, in backward
scaled_loss.backward(retain_graph=retain_graph)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/_tensor.py", line 307, in backward
scaled_loss.backward(retain_graph=retain_graph)torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/_tensor.py", line 307, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 199, in apply
self.loss_scaler.backward(loss.float(), retain_graph=retain_graph)
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/fp16/loss_scaler.py", line 53, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 199, in apply
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
return user_fn(self, *args)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/activation_checkpointing/checkpointing.py", line 719, in backward
return user_fn(self, *args)return user_fn(self, *args)return user_fn(self, *args)
scaled_loss.backward(retain_graph=retain_graph) File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/activation_checkpointing/checkpointing.py", line 719, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/activation_checkpointing/checkpointing.py", line 719, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/activation_checkpointing/checkpointing.py", line 719, in backward
return user_fn(self, *args)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/activation_checkpointing/checkpointing.py", line 719, in backward
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/_tensor.py", line 307, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 199, in apply
torch.autograd.backward(output_tensors, grad_tensors)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1774, in reduce_partition_and_remove_grads
return user_fn(self, *args)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/activation_checkpointing/checkpointing.py", line 719, in backward
torch.autograd.backward(output_tensors, grad_tensors)torch.autograd.backward(output_tensors, grad_tensors)torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)torch.autograd.backward(output_tensors, grad_tensors)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
torch.autograd.backward(output_tensors, grad_tensors)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flagallow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1774, in reduce_partition_and_remove_grads
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 199, in apply
return func(*args, **kwargs)
self.reduce_ready_partitions_and_remove_grads(param, i)return func(*args, **kwargs) File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1774, in reduce_partition_and_remove_grads
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2049, in reduce_ready_partitions_and_remove_grads
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1774, in reduce_partition_and_remove_grads
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
torch.autograd.backward(output_tensors, grad_tensors)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
return func(*args, **kwargs)return user_fn(self, *args)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1774, in reduce_partition_and_remove_grads
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/activation_checkpointing/checkpointing.py", line 719, in backward
self.loss_scaler.backward(loss.float(), retain_graph=retain_graph)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/fp16/loss_scaler.py", line 53, in backward
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
scaled_loss.backward(retain_graph=retain_graph)
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1774, in reduce_partition_and_remove_grads
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/_tensor.py", line 307, in backward
self.reduce_ready_partitions_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2049, in reduce_ready_partitions_and_remove_grads
self.reduce_independent_p_g_buckets_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1810, in reduce_independent_p_g_buckets_and_remove_grads
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
torch.autograd.backward(output_tensors, grad_tensors)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
self.reduce_ready_partitions_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2049, in reduce_ready_partitions_and_remove_grads
self.reduce_ready_partitions_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2049, in reduce_ready_partitions_and_remove_grads
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/function.py", line 199, in apply
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
self.__reduce_and_partition_ipg_grads() File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1774, in reduce_partition_and_remove_grads
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
self.reduce_independent_p_g_buckets_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1810, in reduce_independent_p_g_buckets_and_remove_grads
return func(*args, **kwargs)return user_fn(self, *args)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/activation_checkpointing/checkpointing.py", line 719, in backward
self.reduce_ready_partitions_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2049, in reduce_ready_partitions_and_remove_grads
self.reduce_independent_p_g_buckets_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1810, in reduce_independent_p_g_buckets_and_remove_grads
self.reduce_independent_p_g_buckets_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1810, in reduce_independent_p_g_buckets_and_remove_grads
self.reduce_ready_partitions_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2049, in reduce_ready_partitions_and_remove_grads
torch.autograd.backward(output_tensors, grad_tensors)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/__init__.py", line 156, in backward
self.__reduce_and_partition_ipg_grads()
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1868, in __reduce_and_partition_ipg_grads
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1868, in __reduce_and_partition_ipg_grads
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
self.__reduce_and_partition_ipg_grads()
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)self.__reduce_and_partition_ipg_grads()
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1774, in reduce_partition_and_remove_grads
return func(*args, **kwargs) File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1868, in __reduce_and_partition_ipg_grads
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1868, in __reduce_and_partition_ipg_grads
self.reduce_ready_partitions_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2049, in reduce_ready_partitions_and_remove_grads
self.__partition_grads(self.__params_in_ipg_bucket, grad_partitions)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1984, in __partition_grads
self.__partition_grads(self.__params_in_ipg_bucket, grad_partitions)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1984, in __partition_grads
self.reduce_independent_p_g_buckets_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1810, in reduce_independent_p_g_buckets_and_remove_grads
self.__partition_grads(self.__params_in_ipg_bucket, grad_partitions)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
self.__partition_grads(self.__params_in_ipg_bucket, grad_partitions)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1984, in __partition_grads
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1984, in __partition_grads
self.reduce_independent_p_g_buckets_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1810, in reduce_independent_p_g_buckets_and_remove_grads
grad_partition.numel())
RuntimeError: start (0) + length (33554432) exceeds dimension size (1).
self.reduce_ready_partitions_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 2049, in reduce_ready_partitions_and_remove_grads
grad_partition.numel())
RuntimeError: start (0) + length (33554432) exceeds dimension size (1).
grad_partition.numel())
RuntimeErrorgrad_partition.numel()):
start (0) + length (33554432) exceeds dimension size (1).
RuntimeError: start (0) + length (33554432) exceeds dimension size (1).
self.reduce_independent_p_g_buckets_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1810, in reduce_independent_p_g_buckets_and_remove_grads
self.__reduce_and_partition_ipg_grads()
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
self.__reduce_and_partition_ipg_grads()
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1868, in __reduce_and_partition_ipg_grads
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
self.reduce_independent_p_g_buckets_and_remove_grads(param, i)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1810, in reduce_independent_p_g_buckets_and_remove_grads
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1868, in __reduce_and_partition_ipg_grads
self.__reduce_and_partition_ipg_grads()
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1868, in __reduce_and_partition_ipg_grads
self.__partition_grads(self.__params_in_ipg_bucket, grad_partitions)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1984, in __partition_grads
self.__partition_grads(self.__params_in_ipg_bucket, grad_partitions)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1984, in __partition_grads
self.__reduce_and_partition_ipg_grads()
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1868, in __reduce_and_partition_ipg_grads
self.__partition_grads(self.__params_in_ipg_bucket, grad_partitions)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1984, in __partition_grads
grad_partition.numel())
RuntimeError: start (0) + length (33554432) exceeds dimension size (1).
grad_partition.numel())
RuntimeError: start (0) + length (33554432) exceeds dimension size (1).
self.__partition_grads(self.__params_in_ipg_bucket, grad_partitions)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/ubuntu/.local/lib/python3.7/site-packages/deepspeed/runtime/zero/stage3.py", line 1984, in __partition_grads
grad_partition.numel())
RuntimeError: start (0) + length (33554432) exceeds dimension size (1).
grad_partition.numel())
RuntimeError: start (0) + length (33554432) exceeds dimension size (1).
[2022-03-23 05:58:40,896] [INFO] [launch.py:178:sigkill_handler] Killing subprocess 11942
[2022-03-23 05:58:40,896] [INFO] [launch.py:178:sigkill_handler] Killing subprocess 11943
[2022-03-23 05:58:40,896] [INFO] [launch.py:178:sigkill_handler] Killing subprocess 11944
[2022-03-23 05:58:40,896] [INFO] [launch.py:178:sigkill_handler] Killing subprocess 11945
[2022-03-23 05:58:40,896] [INFO] [launch.py:178:sigkill_handler] Killing subprocess 11946
[2022-03-23 05:58:40,896] [INFO] [launch.py:178:sigkill_handler] Killing subprocess 11947
[2022-03-23 05:58:40,897] [INFO] [launch.py:178:sigkill_handler] Killing subprocess 11948
[2022-03-23 05:58:40,897] [INFO] [launch.py:178:sigkill_handler] Killing subprocess 11949
[2022-03-23 05:58:40,897] [ERROR] [launch.py:184:sigkill_handler] ['/usr/bin/python3', '-u', 'pretrain_gpt2.py', '--local_rank=7', '--model-parallel-size', '1', '--num-layers', '50', '--hidden-size', '8192', '--num-attention-heads', '32', '--seq-length', '1024', '--max-position-embeddings', '1024', '--batch-size', '8', '--train-iters', '320000', '--lr-decay-iters', '320000', '--save', 'checkpoints/gpt2_345m_ds', '--load', 'checkpoints/gpt2_345m_ds', '--data-path', '/data/Megatron-LM/data/indexed_datasets/megatron', '--vocab-file', '/data/Megatron-LM/data/gpt2-vocab.json', '--merge-file', '/data/Megatron-LM/data/gpt2-merges.txt', '--data-impl', 'mmap', '--split', '949,50,1', '--distributed-backend', 'nccl', '--lr', '1.5e-4', '--lr-decay-style', 'cosine', '--min-lr', '1.0e-5', '--weight-decay', '1e-2', '--clip-grad', '1.0', '--warmup', '0.01', '--checkpoint-activations', '--log-interval', '1', '--save-interval', '10000', '--eval-interval', '2000', '--eval-iters', '10', '--fp16', '--scattered-embeddings', '--split-transformers', '--deepspeed', '--deepspeed_config', '/home/ubuntu/git/DeepSpeed/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3/examples/infinity1.json', '--zero-stage', '3', '--zero-reduce-bucket-size', '50000000', '--zero-allgather-bucket-size', '5000000000', '--zero-contigious-gradients', '--zero-reduce-scatter', '--deepspeed-activation-checkpointing', '--checkpoint-num-layers', '1', '--partition-activations', '--checkpoint-in-cpu', '--synchronize-each-layer', '--contigious-checkpointing'] exits with return code = 1
ds_report output
Please
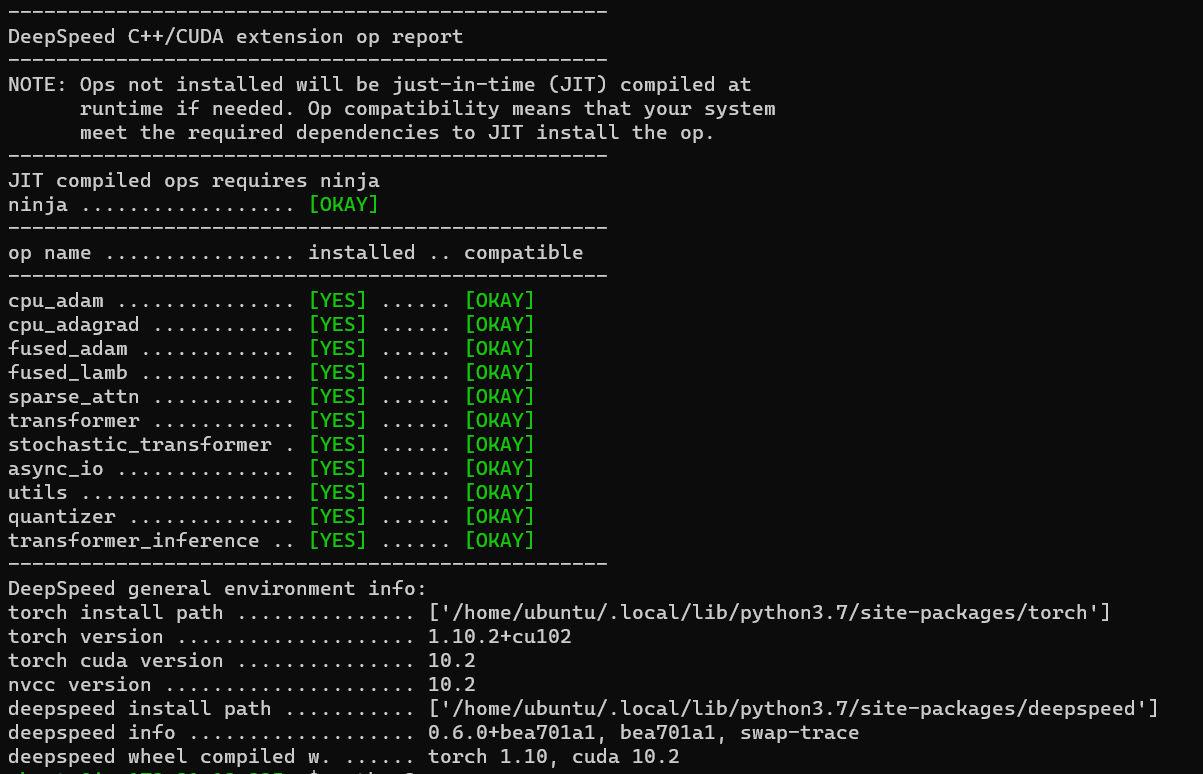
run ds_report to give us details about your setup.
Screenshots
If applicable, add screenshots to help explain your problem.
OS: ubuntu18.04
GPU 8, T4 (g4dn.metal)
1 node
Python version: 3.7.5
System info (please complete the following information):
- OS: [e.g. Ubuntu 18.04]
- GPU count and types [e.g. two machines with x8 A100s each]
- Interconnects (if applicable) [e.g., two machines connected with 100 Gbps IB]
- Python version
- Any other relevant info about your setup
Launcher context
Are you launching your experiment with the deepspeed launcher, MPI, or something else?
bash script.sh (below file)
#! /bin/bash
# Change for multinode config
MP_SIZE=1
DEBUG=1
if [[ ${DEBUG} == 1 ]]; then
MP_SIZE=1
NUM_WORKERS=1
NUM_GPUS_PER_WORKER=8
HIDDEN_SIZE=8192
NUM_ATTN_HEADS=32
NUM_LAYERS=50
BATCHSIZE=8
else
NUM_WORKERS=${DLTS_NUM_WORKER}
NUM_GPUS_PER_WORKER=${DLTS_NUM_GPU_PER_WORKER}
HIDDEN_SIZE=8192
NUM_ATTN_HEADS=32
NUM_LAYERS=50
BATCHSIZE=4
#HIDDEN_SIZE=4096
#NUM_LAYERS=24 # 50
#BATCHSIZE=16
fi
BASE_DATA_PATH=/data/Megatron-LM/data
DATA_PATH=${BASE_DATA_PATH}/indexed_datasets/megatron
VOCAB_PATH=${BASE_DATA_PATH}/gpt2-vocab.json
MERGE_PATH=${BASE_DATA_PATH}/gpt2-merges.txt
CHECKPOINT_PATH=checkpoints/gpt2_345m_ds
script_path=$(realpath $0)
script_dir=$(dirname $script_path)
if [[ -z $1 ]]; then
#config_json="$script_dir/ds_zero_stage_3_config.json"
# offloads to NVMe
config_json="$script_dir/infinity1.json"
else
config_json=$script_dir/`basename $1`
fi
#ZeRO Configs
stage=3
reduce_scatter=true
contigious_gradients=true
rbs=50000000
agbs=5000000000
#Activation Checkpointing and Contigious Memory
chkp_layers=1
PA=true
PA_CPU=true
CC=true
SYNCHRONIZE=true
PROFILE=false
# TiledLinear splits, 0 is disable
TILED_LINEAR="false"
TILE_DIM=1
# Megatron Model Parallelism
LOGDIR="tboard-zero3/stage${stage}-lazyscatter-${NUM_LAYERS}l_${HIDDEN_SIZE}h_${NUM_WORKERS}n_${NUM_GPUS_PER_WORKER}g_${MP_SIZE}mp_${BATCHSIZE}b"
gpt_options=" \
--model-parallel-size ${MP_SIZE} \
--num-layers $NUM_LAYERS \
--hidden-size $HIDDEN_SIZE \
--num-attention-heads ${NUM_ATTN_HEADS} \
--seq-length 1024 \
--max-position-embeddings 1024 \
--batch-size $BATCHSIZE \
--train-iters 320000 \
--lr-decay-iters 320000 \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
--vocab-file $VOCAB_PATH \
--merge-file $MERGE_PATH \
--data-impl mmap \
--split 949,50,1 \
--distributed-backend nccl \
--lr 1.5e-4 \
--lr-decay-style cosine \
--min-lr 1.0e-5 \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--warmup 0.01 \
--checkpoint-activations \
--log-interval 1 \
--save-interval 10000 \
--eval-interval 2000 \
--eval-iters 10 \
--fp16 \
--scattered-embeddings \
--split-transformers \
"
#--tensorboard-dir ${LOGDIR}
deepspeed_options=" \
--deepspeed \
--deepspeed_config ${config_json} \
--zero-stage ${stage} \
--zero-reduce-bucket-size ${rbs} \
--zero-allgather-bucket-size ${agbs}
"
if [ "${contigious_gradients}" = "true" ]; then
deepspeed_options="${deepspeed_options} \
--zero-contigious-gradients"
fi
if [ "${reduce_scatter}" = "true" ]; then
deepspeed_options="${deepspeed_options} \
--zero-reduce-scatter"
fi
chkp_opt=" \
--deepspeed-activation-checkpointing \
--checkpoint-num-layers ${chkp_layers}"
if [ "${PA}" = "true" ]; then
chkp_opt="${chkp_opt} --partition-activations"
fi
if [ "${PA_CPU}" = "true" ]; then
chkp_opt="${chkp_opt} \
--checkpoint-in-cpu"
fi
if [ "${SYNCHRONIZE}" = "true" ]; then
chkp_opt="${chkp_opt} \
--synchronize-each-layer"
fi
if [ "${CC}" = "true" ]; then
chkp_opt="${chkp_opt} \
--contigious-checkpointing"
fi
if [ "${PROFILE}" = "true" ]; then
chkp_opt="${chkp_opt} \
--profile-backward"
fi
if [ "${TILED_LINEAR}" = "true" ]; then
tile_opt="${tile_opt} \
--memory-centric-tiled-linear \
--tile-factor=${TILE_DIM}"
fi
full_options="${gpt_options} ${deepspeed_options} ${chkp_opt} ${tile_opt}"
run_cmd="deepspeed --num_nodes ${NUM_WORKERS} --num_gpus ${NUM_GPUS_PER_WORKER} pretrain_gpt2.py ${@:2} ${full_options}"
echo ${run_cmd}
eval ${run_cmd}
set +x
config file
{
"train_micro_batch_size_per_gpu": 1,
"gradient_accumulation_steps": 1,
"steps_per_print": 1,
"zero_optimization": {
"stage": 3,
"stage3_max_live_parameters": 1e8,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"stage3_max_reuse_distance": 1e8,
"stage3_param_persitence_threshold": 1e8,
"stage3_prefetch_bucket_size": 1e8,
"contiguous_gradients": true,
"overlap_comm": true,
"sub_group_size": 1e8,
"offload_optimizer": {
"device": "nvme",
"nvme_path": "/mnt/nvme2" ,
"buffer_count": 4,
"buffer_size": 1e9,
"pipeline_read": false,
"pipeline_write": false,
"pin_memory": true
},
"offload_param": {
"device": "nvme",
"nvme_path": "/mnt/nvme3",
"buffer_count": 5,
"max_in_cpu": 1e9,
"max_in_nvme": 1e9,
"buffer_size": 1e9,
"pin_memory": true
}
},
"activation_checkpointing": {
"profile": true,
"cpu_checkpointing": true,
"partition_activations": true
},
"gradient_clipping": 1.0,
"fp16": {
"enabled": true,
"loss_scale": 1024,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"wall_clock_breakdown": true,
"zero_allow_untested_optimizer": false,
"aio": {
"block_size": 1048576,
"queue_depth": 8,
"single_submit": false,
"overlap_events": true,
"thread_count": 1
}
}