Not getting convergence in Bert Large Training. #830
Description
Hey,
I have been trying out Deepspeed for a while, thank you for all the cool features.
I am trying to train a bert large from scratch using 335Million token sequences. After considering gradient accumulation and number of GPU's involved, the effective batch size comes out to be 1920.
The loss graph looks something like this :
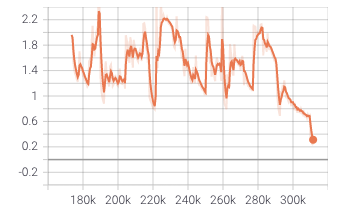
Note that with small batches it converges well, and the loss stays between 0 and 1 but it takes too long and we have more data coming in.
Following is my config :
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 1,
"allgather_partitions": true,
"allgather_bucket_size": 100000000,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 100000000,
"contiguous_gradients": true,
"cpu_offload": false
},
"optimizer": {
"type": "Lamb",
"params": {
"lr": 0.001,
"weight_decay": 0.01,
"bias_correction": false,
"max_coeff": 0.3,
"min_coeff": 0.01
}
},
"zero_allow_untested_optimizer": true,
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.0003,
"warmup_num_steps": 200
}
}
}