This repository holds all data and resources arising from the development of Visual Sense, which aims to integrate the Visual Genome image dataset with the linguistic resource Framester.
Frame evocation from visual data is an essential process for multimodal sensemaking, due to the multimodal abstraction provided by frame semantics. However, there is a scarcity of data-driven approaches and tools to automate it. We propose a novel approach to automated multimodal sensemaking by linking linguistic frames to their physical visual occurrences, using ontology-based knowledge engineering techniques. We pair the evocation of linguistic frames from text to visual data as ``framal visual manifestations.'' We have firstly performed a deep ontological analysis of the implicit data model of the Visual Genome image dataset, and formalizing it as the Visual Sense Ontology (VSO). To enhance the existing multimodal data, we introduce a framal knowledge expansion pipeline that extracts and connects linguistic frames--including values and emotions--to visual data, using multiple linguistic resources for disambiguation. It then introduces the Visual Sense Knowledge Graph (VSKG), a novel resource. VSKG is a queryable knowledge graph that enhances the accessibility and comprehensibility of Visual Genome's multimodal data, based on SPARQL queries. VSKG includes frame visual evocation data, enabling more advanced forms of analysis and sensemaking. Our work represents a significant advancement in the automation of frame evocation and multimodal sense-making, performed in a fully interpretable and transparent way, with potential applications in various fields, including the fields of knowledge representation, computer vision, and natural language processing.
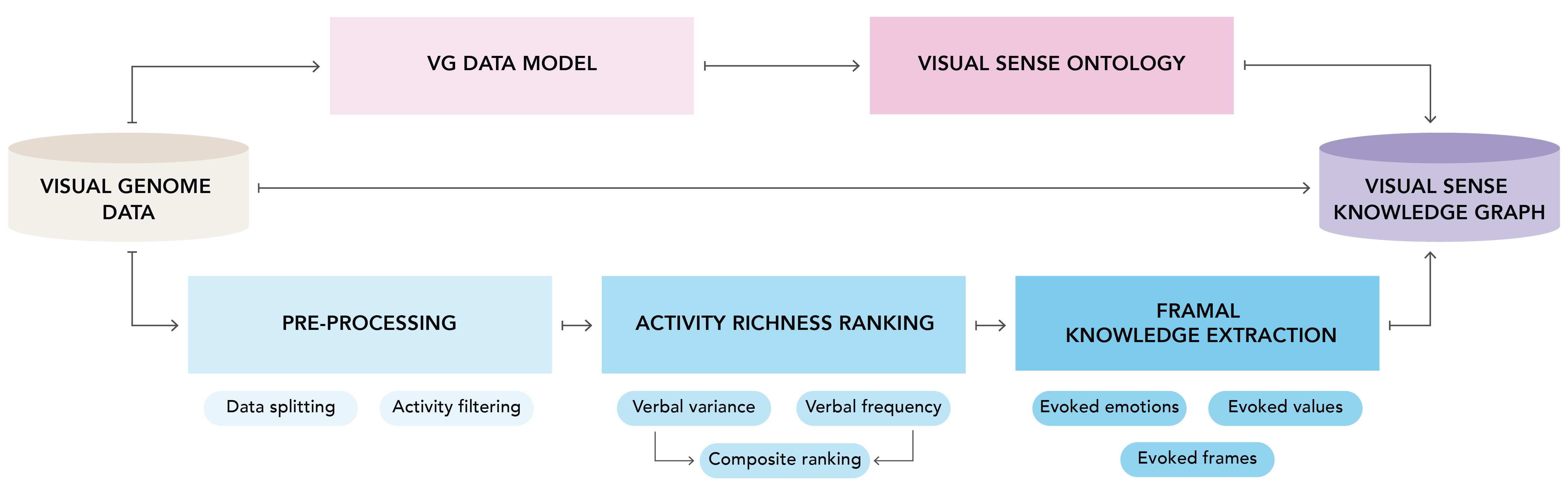
Fig 1. Starting from the data provided by the Visual Genome project (beige), our pipeline allows for the automatic creation of a semantic web knowledge graph containing visual, factual, and linguistic data. Top: Data modeling and ontology engineering branch (pink shades). Bottom: Framal knowledge enhancement branch (blue shades). The combination of the original data, the Visual Sense Ontology, and the extracted framal data are used to create the Visual Sense Knowledge Graph (purple).
 Figure 2. Four examples of framal visual manifestations on images from the VG dataset, with visible bounding boxes of depicted regions labeled with evoked frames, emotions, and values. Clockwise: the first image shows how frames refer to concrete entities (fs:Clothing) can co-activate with more abstract frames such as (fs:Temperature) in the same image region. The second image provides visual instantiations of general frames like fs:CommerceScenario and folk:BodyMovement. The third image shows visual instantiations of frames like fs:Electricity around the electric guitar, and folk:PerceptionActive in the area of spectators paying attention to the performers. The last image demonstrates a visual instantiation of the value of folk:Partnership, among others.
Figure 2. Four examples of framal visual manifestations on images from the VG dataset, with visible bounding boxes of depicted regions labeled with evoked frames, emotions, and values. Clockwise: the first image shows how frames refer to concrete entities (fs:Clothing) can co-activate with more abstract frames such as (fs:Temperature) in the same image region. The second image provides visual instantiations of general frames like fs:CommerceScenario and folk:BodyMovement. The third image shows visual instantiations of frames like fs:Electricity around the electric guitar, and folk:PerceptionActive in the area of spectators paying attention to the performers. The last image demonstrates a visual instantiation of the value of folk:Partnership, among others.
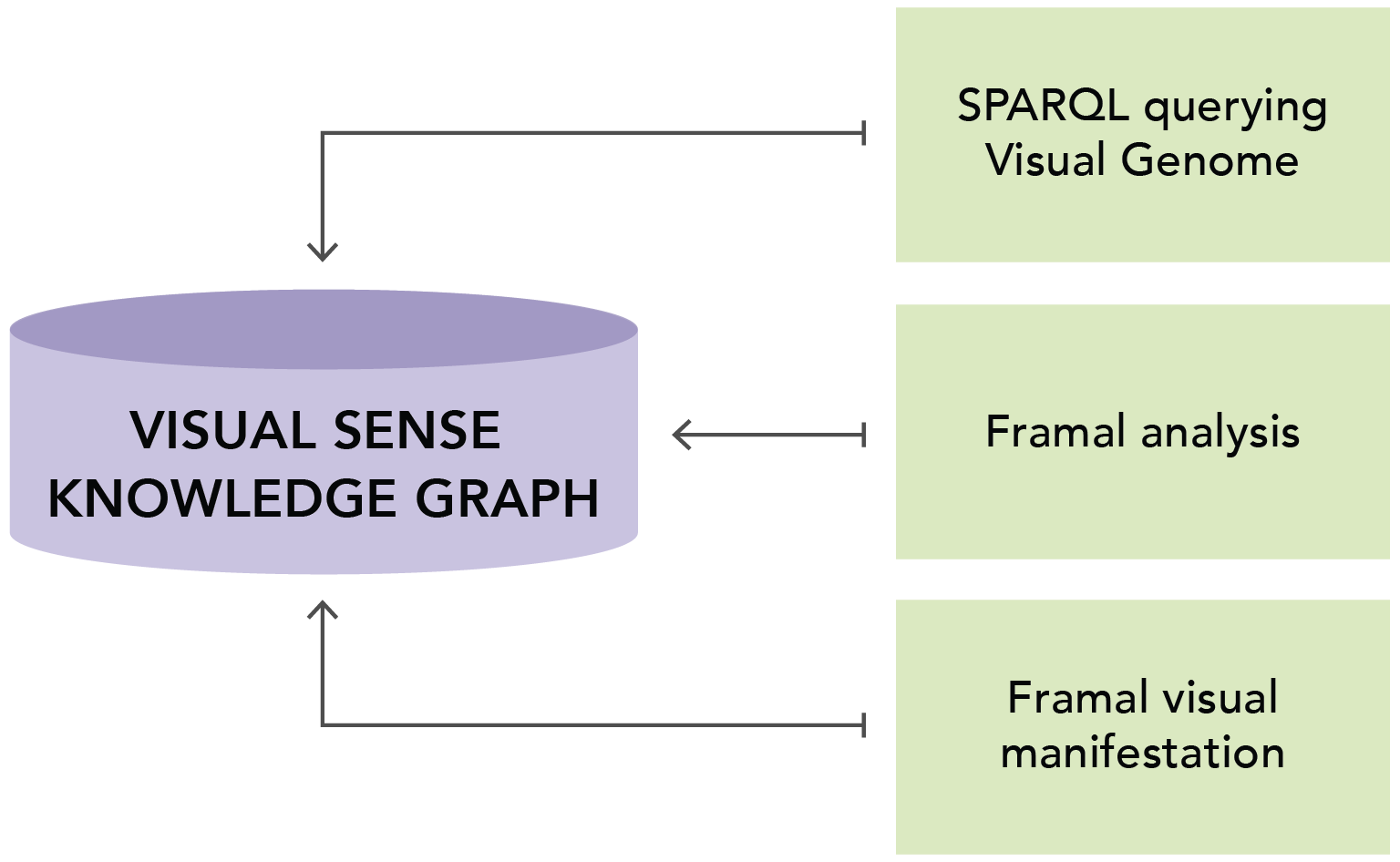 Figure 3. The Visual Sense Knowledge Graph (VSKG) is a versatile multimodal resource that offers multiple benefits. Not only does it store multimodal information pertaining to Visual Genome (VG) images, but it also enables direct and explicit queries on relationships within and between images and their contents. As a result, it facilitates sophisticated frame analysis of images, as well as exploration of patterns of frame compositionality. Furthermore, the VSKG's inclusion of both linguistic frame information and precise evocation coordinates allows for literal visualization of linguistic frame visual manifestations.
Figure 3. The Visual Sense Knowledge Graph (VSKG) is a versatile multimodal resource that offers multiple benefits. Not only does it store multimodal information pertaining to Visual Genome (VG) images, but it also enables direct and explicit queries on relationships within and between images and their contents. As a result, it facilitates sophisticated frame analysis of images, as well as exploration of patterns of frame compositionality. Furthermore, the VSKG's inclusion of both linguistic frame information and precise evocation coordinates allows for literal visualization of linguistic frame visual manifestations.
Visual Genome (VG) is an annotated image dataset containing over 108K images where each image is annotated with an average of 35 objects, 26 attributes, and 21 pairwise relationships between objects. Regarding relationships and attributes as first-class citizens of the annotation space, in addition to the traditional focus on objects, VG’s annotations represent the densest and largest dataset of image descriptions, objects, attributes, relationships, and question answer pairs. The Visual Genome dataset is among the first to provide a detailed labeling of object interactions and attributes, providing a first step of grounding visual concepts to language by canonicalizing the objects, attributes, relationships, noun phrases in region descriptions, and question & answer pairs to WordNet synsets.
Framester is a frame-based ontological resource acting as a hub between linguistic resources such as FrameNet, WordNet, VerbNet, BabelNet, DBpedia, Yago, DOLCE-Zero, and leveraging this wealth of links to create an interoperable predicate space formalized according to frame semantics and semiotics principles. Framester uses WordNet and FrameNet at its core, expanding to other resources transitively, and represents them in a formal version of frame semantics. Framester has a freely available dedicated SPARQL endpoint and an API. The schema of Framester is also available as an ontology.
Visual Genome: https://visualgenome.org/
Visual Genome JSON datasets: https://visualgenome.org/api/v0/api_home.html
Visual Genome API: https://visualgenome.org/api/v0/api_endpoint_reference.html
Framester: https://github.com/framester/Framester
Framester SPARQL Endpoint: http://etna.istc.cnr.it/framester2/sparql
Framester API: http://etna.istc.cnr.it/framester_web/
Framester schema: https://raw.githubusercontent.com/framester/schema/master/ontology.owl
Contents of the repository so far:
-
1 A-Data_Modeling_Ontology_Engineering_Branch: Contains information about VG, the reconstructed ("old") underlying model of Visual Genome, based on the JSON files to be queried, images of the kinds of repetitions/complications found in the model, and a "cleaner" version ("new") underlying model of VG, that attempts to take care of the repetitive situations. It also contains our application of the eXtreme Design (XD) methodology proposed by Bloomqvist. eXtreme Design (XD) is an ontology design methodology whose core principle is ontology design patterns (ODP) reuse, as an explicit activity. This folder contains information about our XD methodolofy (stories, competency questions, SPARQL test queries). Finally, it includes the Visual Sense Ontology: contains the visual sense ontology (in owl format), information about ontology alignment, ontology design pattern (ODP) reuse, graphs of the TBox, and documentation.
-
B-Framal_Knowledge_Enhancement_Branch: Contains scripts to split big json files in smaller, more processable files, as well as the preprocessing pipeline with activity presence and richness criteria and ranking. It also includes the Frame Evocation pipeline, with information, code, and instructions about how we tested the evocation of Framester frames from the VG data.
-
C-Visual_Sense_Knowledge_Graph_Creationn: Contains the scripts used to populate the VGO ontology to create teh Visual Sense Knowledge Graph, using the RDFLib python library. We converted the data of the 76 "most activity rich" images into the KG using the Visual Sense ontology, as well as the published first version of the KG.
-
D-Testing: This folder contains the test cases for ontology testing, as well as scripts and instructions for frame visualizations.
This project was authored by Delfina S. M. Pandiani, Stefano De Giorgis, and Fiorela Ciroku.