SQL (Structured Query Language - Lenguaje de consulta estructurada) es un lenguaje que se basó en 2 principios fundamentales:
Teoría de conjuntos. Álgebra relacional de Edgar Codd (científico informático inglés). ⠀ SQL fue creada en 1974 por IBM. Originalmente fue llamado SEQUEL, posteriormente se cambió el nombre por problemas de derechos de autor. ⠀⠀⠀⠀⠀⠀⠀⠀⠀ Relation Company (actualmente con el nombre Oracle) creó el software Oracle V2 en 1979.
Mas adelante SQL se convertiría en un lenguaje estándar que unifica todo dentro de las bases de datos relacionales, se convierte en una norma ANSI o ISO.
El álgebra relacional estudia basicamente las operaciones que se pueden realizar entre diversos conjuntos de datos. ⠀ No confundir las relaciones del álgebra relacional con las relaciones de una base de datos relacional.
Las relaciones de una base de datos es cuando unes dos tablas. Las relaciones en álgebra relacional se refiere a una tabla.
- La diferencia es conceptual: Las tablas pueden tener tuplas repetidas pero en el álgebra relacional cada relación no tiene un cuerpo, no tiene un primer ni último row. ⠀ Tipos de operadores Operadores unarios.- Requiere una relación o tabla para funcionar.
- Proyección (π): Equivale al comando Select. Saca un número de columnas o atributos sin necesidad de hacer una unión con una segunda tabla. π<Nombre, Apellido, Email>(Tabla_Alumno) ⠀
- Selección (σ): Equivale al comando Where. Consiste en el filtrado de de tuplas. σ<Suscripción=Expert>(Tabla_Alumno) ⠀ Operadores binarios.- Requiere más de una tabla para operar.
- Producto cartesiano (x): Toma todos los elementos de una tabla y los combina con los elementos de la segunda tabla. Docentes_Quinto_A x Alumnos_Quinto_A ⠀
- Unión (∪): Obtiene los elementos que existen en una de las tablas o en la otra de las tablas. Alumnos_Quinto_A x Alumnos_Quinto_B ⠀
- Diferencia (-): Obtiene los elementos que existe en una de las tablas pero que no corresponde a la otra tabla. Alumnos_planExpertPlus - Alumnos_planFree
Instalación y configuración de la Base de Datos Vamos a instalar PostgreSQL en nuestra computadora. A continuación veremos el paso a paso y algunos consejos útiles para instalar y configurar correctamente PostgreSQL en nuestro equipo. En éste caso, usaremos Windows, pero los pasos son bastante similares entre los diferentes sistemas operativos.
Primer paso: ir a https://www.postgresql.org/.
Ten en cuenta que puedes ver esta página en diferentes idiomas, depende de la configuración predeterminada de idioma de tu navegador.
Hacer clic en el botón ‘Download’ (Descarga) que se encuentra en la parte inferior derecha.
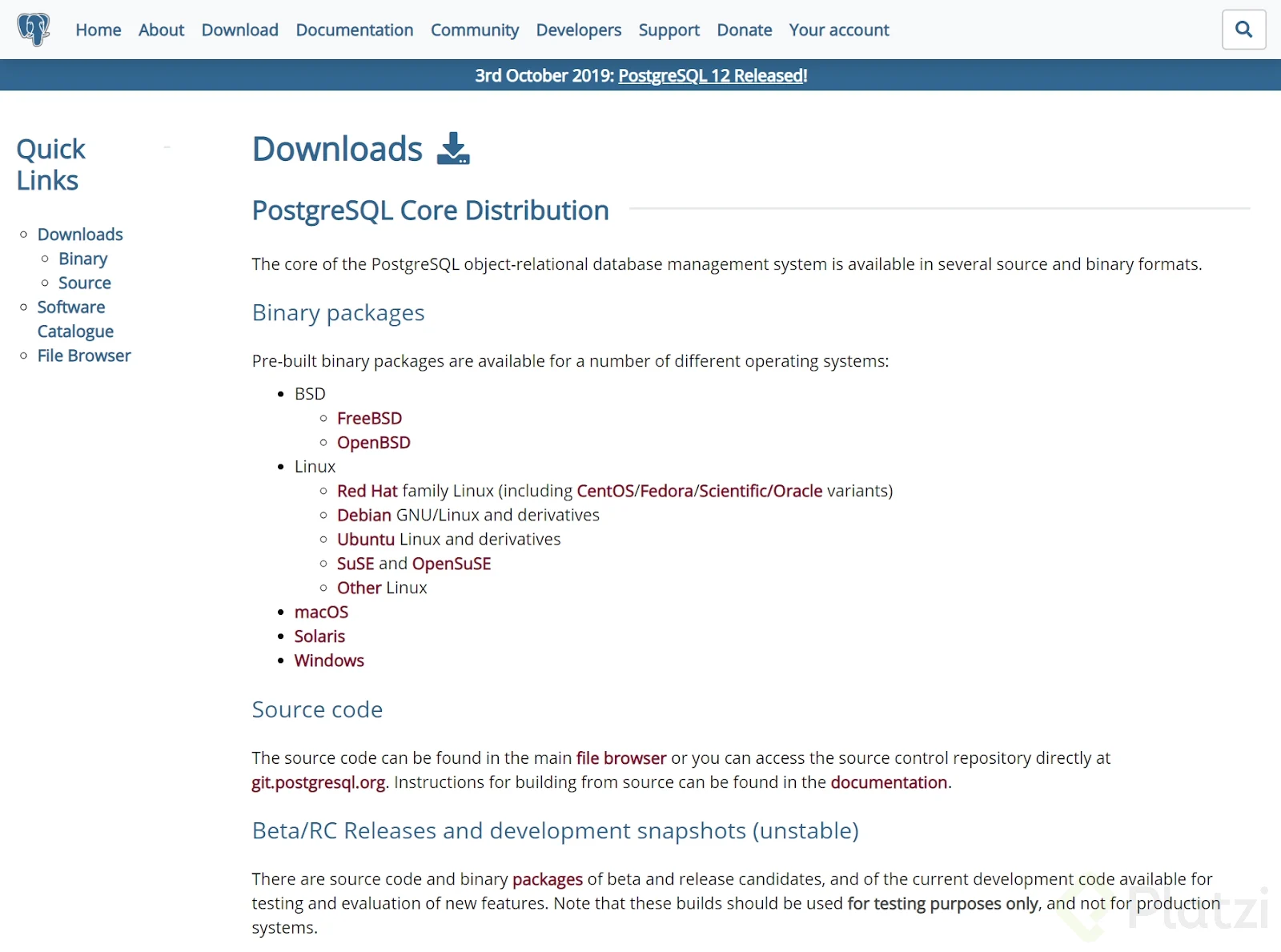 Seleccionamos la opción que corresponda con tu sistema operativo, para éste caso hacemos clic en “Windows”:
Seleccionamos la opción que corresponda con tu sistema operativo, para éste caso hacemos clic en “Windows”:
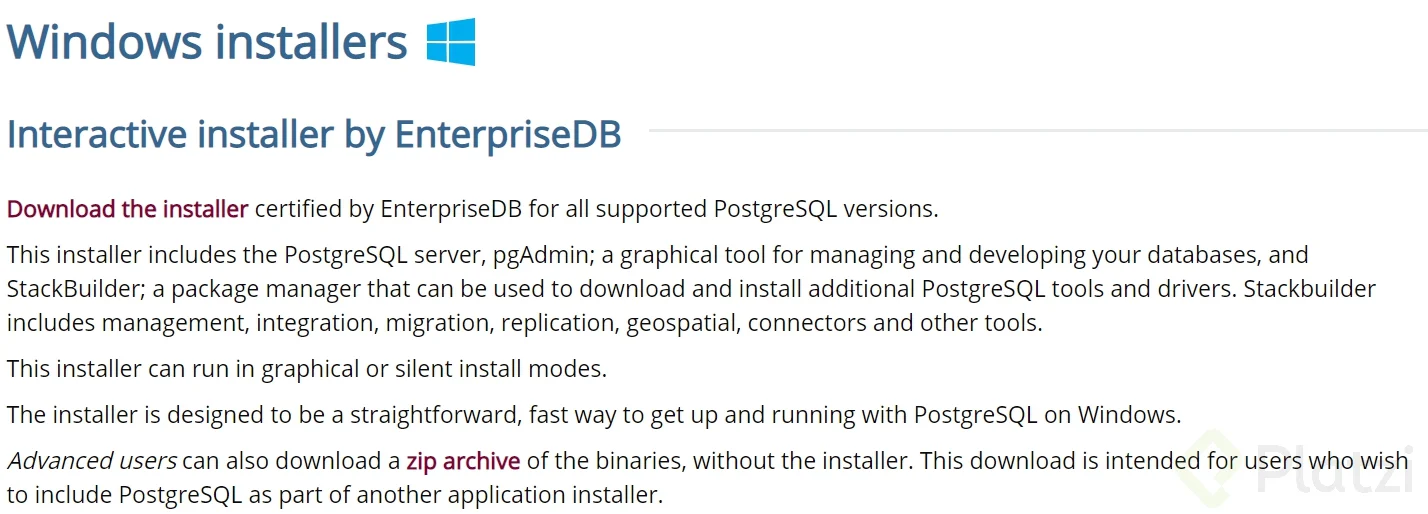 Haz clic en el enlace “Download the installer”. Esto nos va a llevar a la Web de Enterprise DB o EDB. EDB es una empresa que ofrece servicios sobre el motor de base de datos PostgreSQL y ofrece un instalador para Postgres de manera gratuita.
Es altamente recomendable seleccionar la penúltima o antepenúltima versión. Si bien la última versión estable está disponible, en éste caso la 12.0, no es recomendable instalarla en nuestro equipo, ya que al momento de instalarla o usar un servicio en la Nube para Postgres, lo más seguro es que no esté disponible y sólo esté hasta la versión 11.5, que no es la última versión. Esto porque todos los proveedores de Infraestructura no disponen de la versión de Postgres más actual siempre (tardan un poco en apropiar los nuevos lanzamientos).
Si tienes un equipo con Linux, la instalación la puedes hacer directamente desde los repositorios de Linux, EDB ya no ofrece soporte para instaladores en Linux debido a que se ha vuelto innecesario, el repositorio de Linux con PostgreSQL ofrece una manera mucho más sencilla y estándar para instalar PostgreSQL en linux.
Haz clic en el enlace “Download the installer”. Esto nos va a llevar a la Web de Enterprise DB o EDB. EDB es una empresa que ofrece servicios sobre el motor de base de datos PostgreSQL y ofrece un instalador para Postgres de manera gratuita.
Es altamente recomendable seleccionar la penúltima o antepenúltima versión. Si bien la última versión estable está disponible, en éste caso la 12.0, no es recomendable instalarla en nuestro equipo, ya que al momento de instalarla o usar un servicio en la Nube para Postgres, lo más seguro es que no esté disponible y sólo esté hasta la versión 11.5, que no es la última versión. Esto porque todos los proveedores de Infraestructura no disponen de la versión de Postgres más actual siempre (tardan un poco en apropiar los nuevos lanzamientos).
Si tienes un equipo con Linux, la instalación la puedes hacer directamente desde los repositorios de Linux, EDB ya no ofrece soporte para instaladores en Linux debido a que se ha vuelto innecesario, el repositorio de Linux con PostgreSQL ofrece una manera mucho más sencilla y estándar para instalar PostgreSQL en linux.
Segundo paso: descargamos la versión “Windows x86-64” (porque nuestro sistema operativo es de 64 bits). En caso de que tu equipo sea de 32 bits debes seleccionar la opción “Windows x86-32”.
Vamos a descargar la versión 11.5. Hacemos clic en Download y guardamos el archivo que tendrá un nombre similar a: “postgresql-11.5-2-windows-x64.exe”
Ahora vamos a la carpeta donde descargamos el archivo .exe, debe ser de aproximadamente 190 MB, lo ejecutamos.

 Seleccionamos los servicios que queremos instalar. En este caso dejamos seleccionados todos menos “Stack Builder”, pues ofrece la instalación de servicios adicionales que no necesitamos hasta ahora.
Seleccionamos los servicios que queremos instalar. En este caso dejamos seleccionados todos menos “Stack Builder”, pues ofrece la instalación de servicios adicionales que no necesitamos hasta ahora.
 Ahora indicamos la carpeta donde iran guardados los datos de la base de datos, es diferente a la ruta de instalación del Motor de PostgreSQL, pero normalmente será una carpeta de nuestra carpeta de instalación. Puedes cambiar la ruta si quieres tener los datos en otra carpeta.
Ahora indicamos la carpeta donde iran guardados los datos de la base de datos, es diferente a la ruta de instalación del Motor de PostgreSQL, pero normalmente será una carpeta de nuestra carpeta de instalación. Puedes cambiar la ruta si quieres tener los datos en otra carpeta.
 Ingresamos la contraseña del usuario administrador. De manera predeterminada, Postgres crea un usuario super administrador llamado postgres que tiene todos los permisos y acceso a toda la base de datos, tanto para consultarla como para modificarla. En éste paso indicamos la clave de ese usuario super administrador.
Ingresamos la contraseña del usuario administrador. De manera predeterminada, Postgres crea un usuario super administrador llamado postgres que tiene todos los permisos y acceso a toda la base de datos, tanto para consultarla como para modificarla. En éste paso indicamos la clave de ese usuario super administrador.
Debes ingresar una clave muy segura y guardarla porque la vas a necesitar después. Luego hacemos clic en siguiente.
 Ahora si queremos cambiar el puerto por donde el servicio de Postgresql estará escuchando peticiones, podemos hacerlo en la siguiente pantalla, si queremos dejar el predeterminado simplemente hacemos clic en siguiente.
Ahora si queremos cambiar el puerto por donde el servicio de Postgresql estará escuchando peticiones, podemos hacerlo en la siguiente pantalla, si queremos dejar el predeterminado simplemente hacemos clic en siguiente.
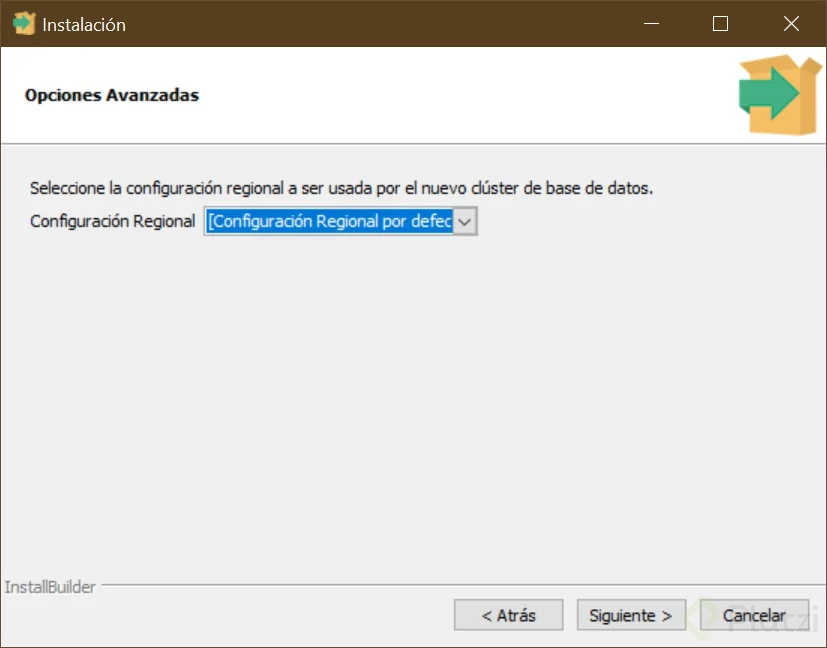
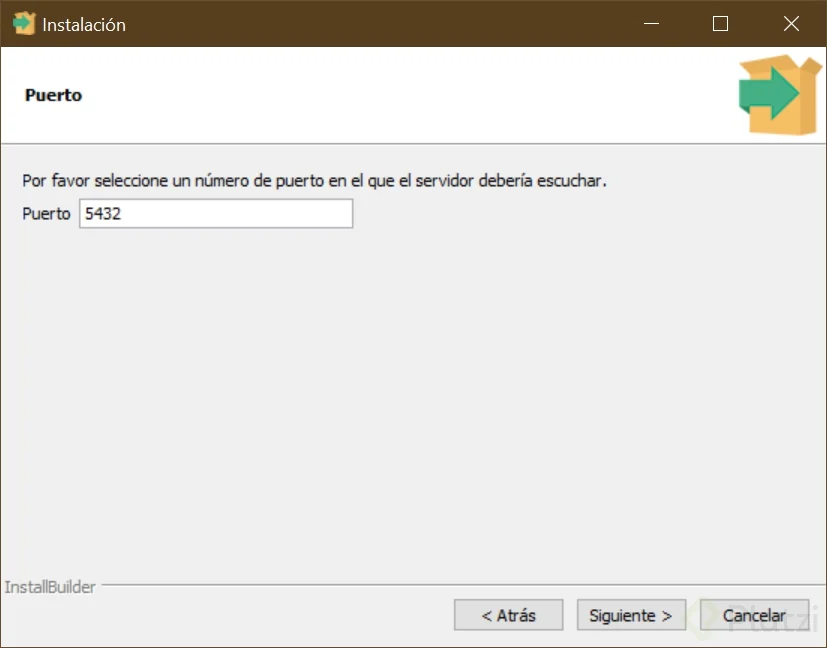 La configuración regional puede ser la predeterminada, no es necesario cambiarla, incluso si vamos a usarla en español, ya que las tildes y las eñes estarán soportadas si dejas la configuración regional predeterminada. Es útil cambiarla cuando quieras dejar de soportar otras funciones de idiomas y lenguajes diferentes a uno específico.
La configuración regional puede ser la predeterminada, no es necesario cambiarla, incluso si vamos a usarla en español, ya que las tildes y las eñes estarán soportadas si dejas la configuración regional predeterminada. Es útil cambiarla cuando quieras dejar de soportar otras funciones de idiomas y lenguajes diferentes a uno específico.
 Al hacer clic en siguiente se muestra una pantalla que indica que PostgreSQL está listo para instalar, al hacer clic de nuevo en siguiente iniciará la instalación, espera un par de minutos hasta que la aplicación termine.
Al hacer clic en siguiente se muestra una pantalla que indica que PostgreSQL está listo para instalar, al hacer clic de nuevo en siguiente iniciará la instalación, espera un par de minutos hasta que la aplicación termine.
Una vez terminada la instalación, aparecerá en pantalla un mensaje mostrando que PostgreSQL ha sido instalado correctamente.
 Podemos cerrar ésta pantalla y proceder a comprobar que todo quedó instalado correctamente.
Podemos cerrar ésta pantalla y proceder a comprobar que todo quedó instalado correctamente.
Vamos a buscar el programa PgAdmin, el cual usaremos como editor favorito para ejecutar en él todas las operaciones sobre nuestra base de datos.
También vamos a buscar la consola… Tanto la consola como PgAdmin son útiles para gestionar nuestra base de datos, una nos permite ingresar comando por comandos y la otra nos ofrece una interfaz visual fácil de entender para realizar todas las operaciones.

Archivos de datos SQL: descarga archivo platzi-carreras.sql y archivo platzi-alumnos.sql.
Una vez tienes instalado PostgreSQL y pgAdmin vamos a crear la estructura de datos que veremos a lo largo del curso.
Para hacerlo abre pgAdmin (normalmente está en la dirección: http://127.0.0.1:63435/browser/), y expande el panel correspondiente a tu base de datos, en mi caso la he nombrado “prueba”.
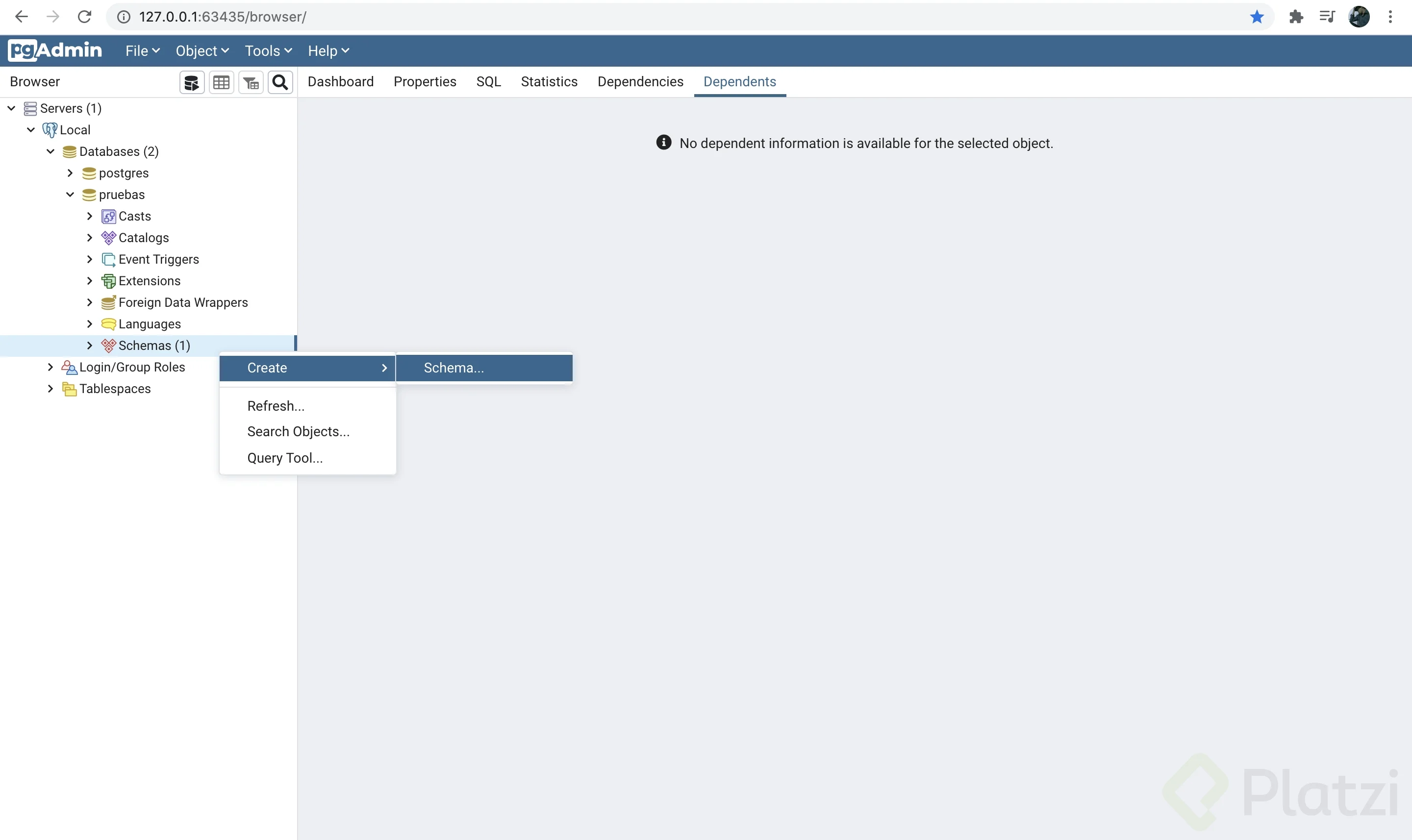
 En la sección esquemas da click secundario y selecciona la opción Create > Schema…
En la sección esquemas da click secundario y selecciona la opción Create > Schema…
 Al seleccionar la opción abrirá un cuadro de diálogo en donde debes escribir el nombre del esquema, en este caso será “platzi”. Si eliges un nombre distinto, asegúrate de seguir los ejemplos en el curso con el nombre elegido; por ejemplo si en el curso mencionamos la sentencia:
Al seleccionar la opción abrirá un cuadro de diálogo en donde debes escribir el nombre del esquema, en este caso será “platzi”. Si eliges un nombre distinto, asegúrate de seguir los ejemplos en el curso con el nombre elegido; por ejemplo si en el curso mencionamos la sentencia:
SELECT * FROM platzi.alumnos
Sustituye platzi por el nombre que elegiste.
Finalmente selecciona tu usuario de postgres en el campo Owner, esto es para que asigne todos los permisos del nuevo esquema a tu usuario
 Revisa que tu esquema se haya generado de manera correcta recargando la página y expandiendo el panel Schemas en tu base de datos.
Revisa que tu esquema se haya generado de manera correcta recargando la página y expandiendo el panel Schemas en tu base de datos.
 Dirígete al menú superior y selecciona el menú Tools > Query Tool.
Dirígete al menú superior y selecciona el menú Tools > Query Tool.
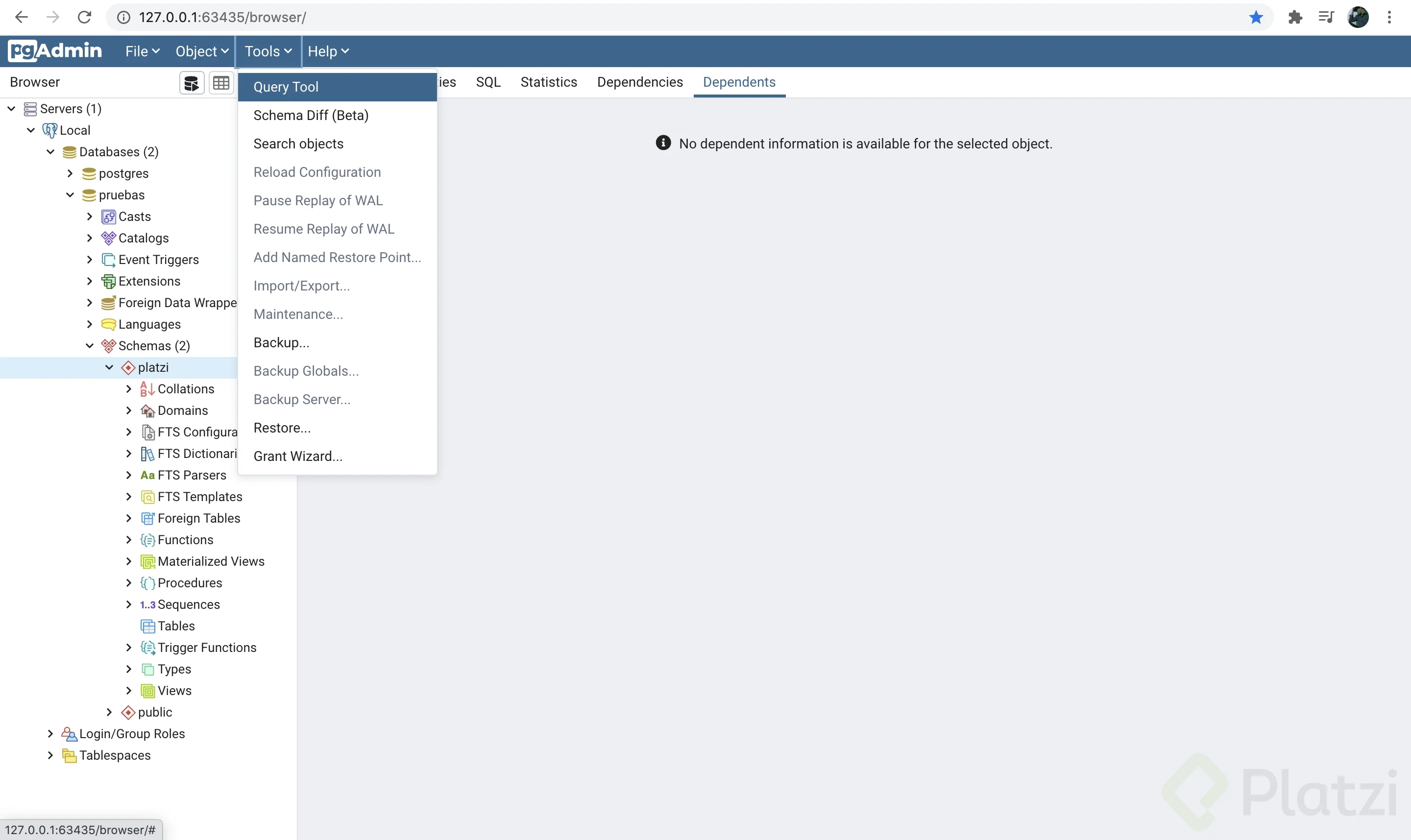 Esto desplegará la herramienta en la ventana principal. Da click en el botón “Open File” ilustrado por un icono de folder abierto.
Esto desplegará la herramienta en la ventana principal. Da click en el botón “Open File” ilustrado por un icono de folder abierto.
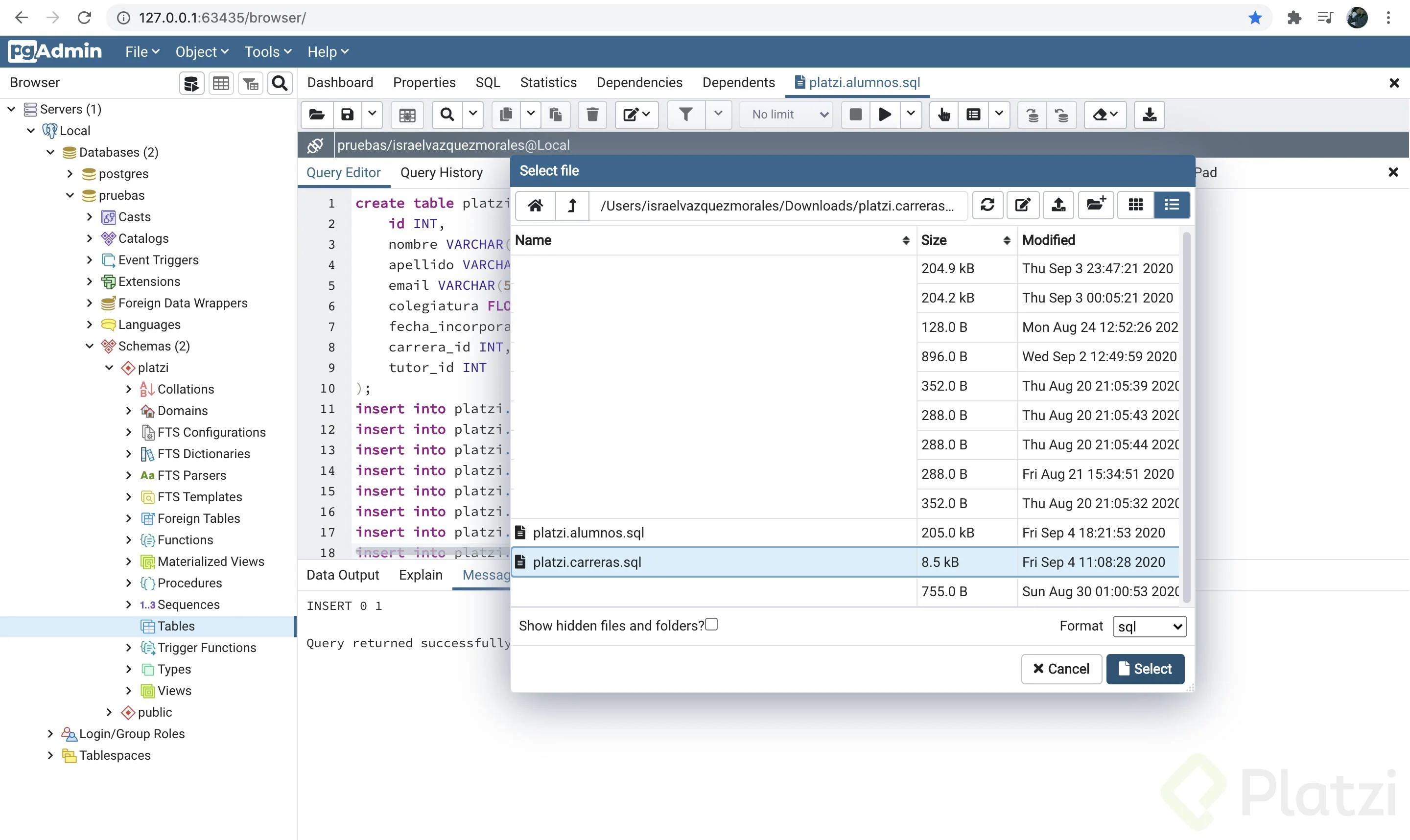
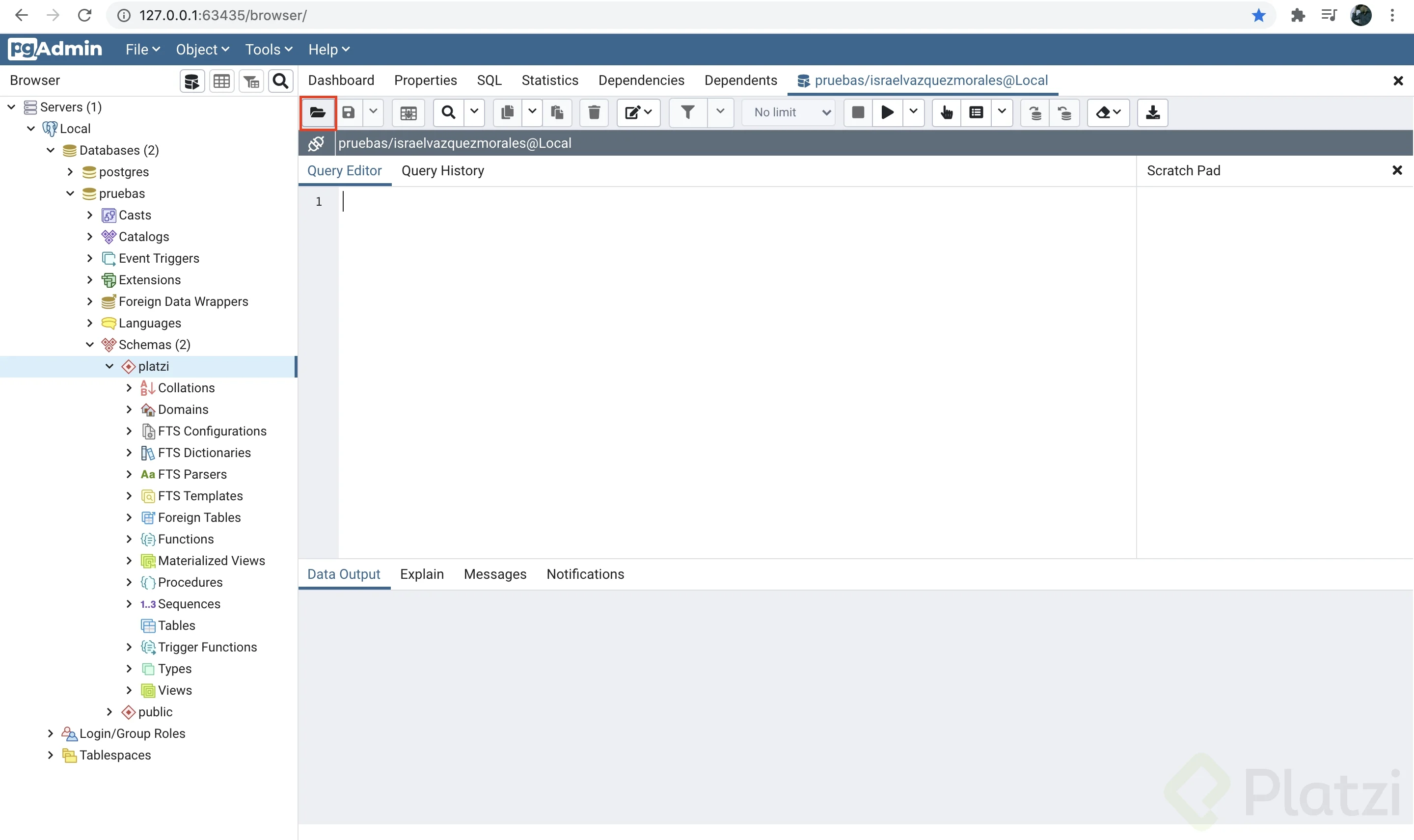 Busca en tus archivos y selecciona el archivo platzi.alumnos.sql que descargaste de este curso, da click en el botón “Select”.
Busca en tus archivos y selecciona el archivo platzi.alumnos.sql que descargaste de este curso, da click en el botón “Select”.
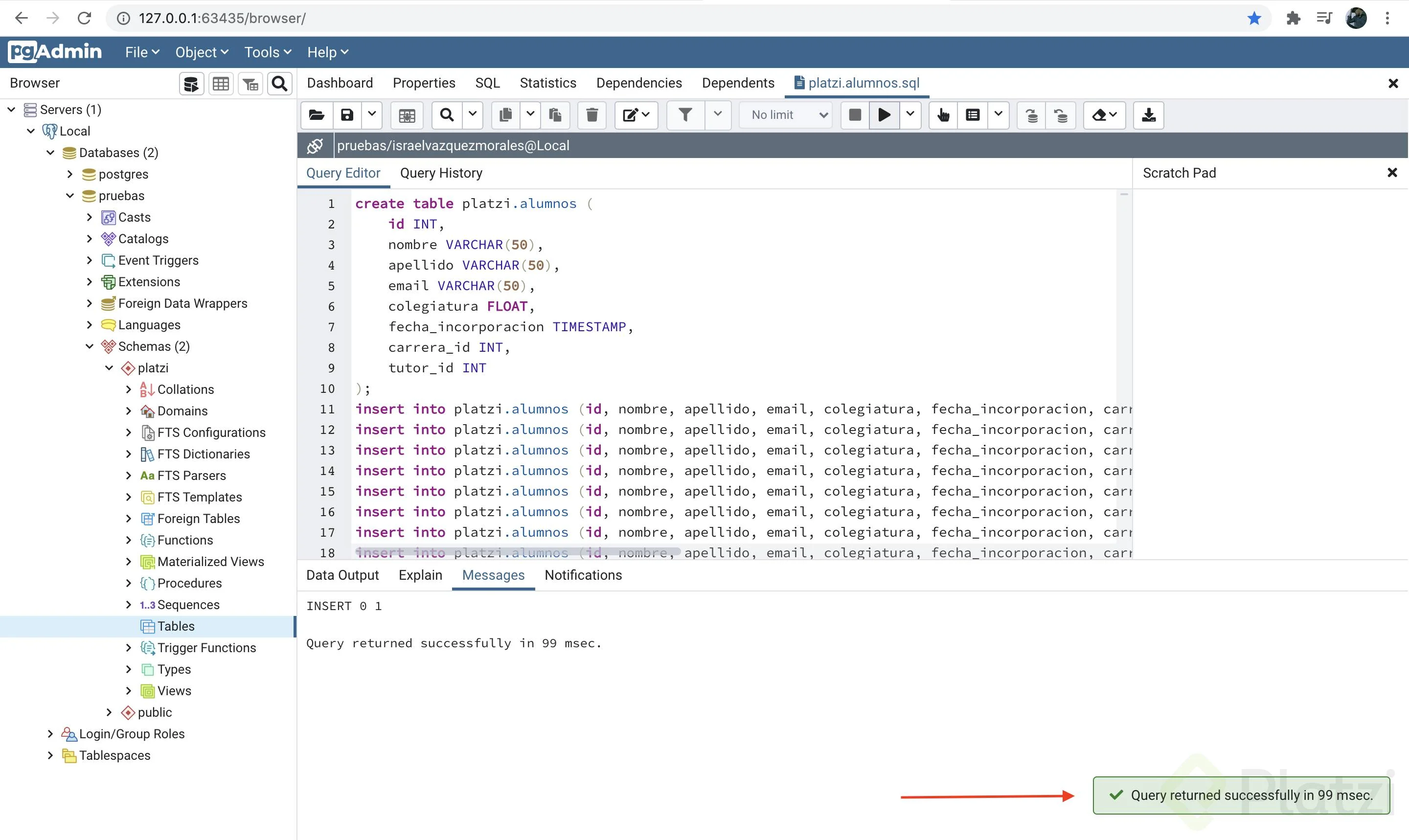
 Esto abrirá el código SQL que deberás ejecutar dando click en el botón ”Execute/Refresh” con el icono play.
Esto abrirá el código SQL que deberás ejecutar dando click en el botón ”Execute/Refresh” con el icono play.
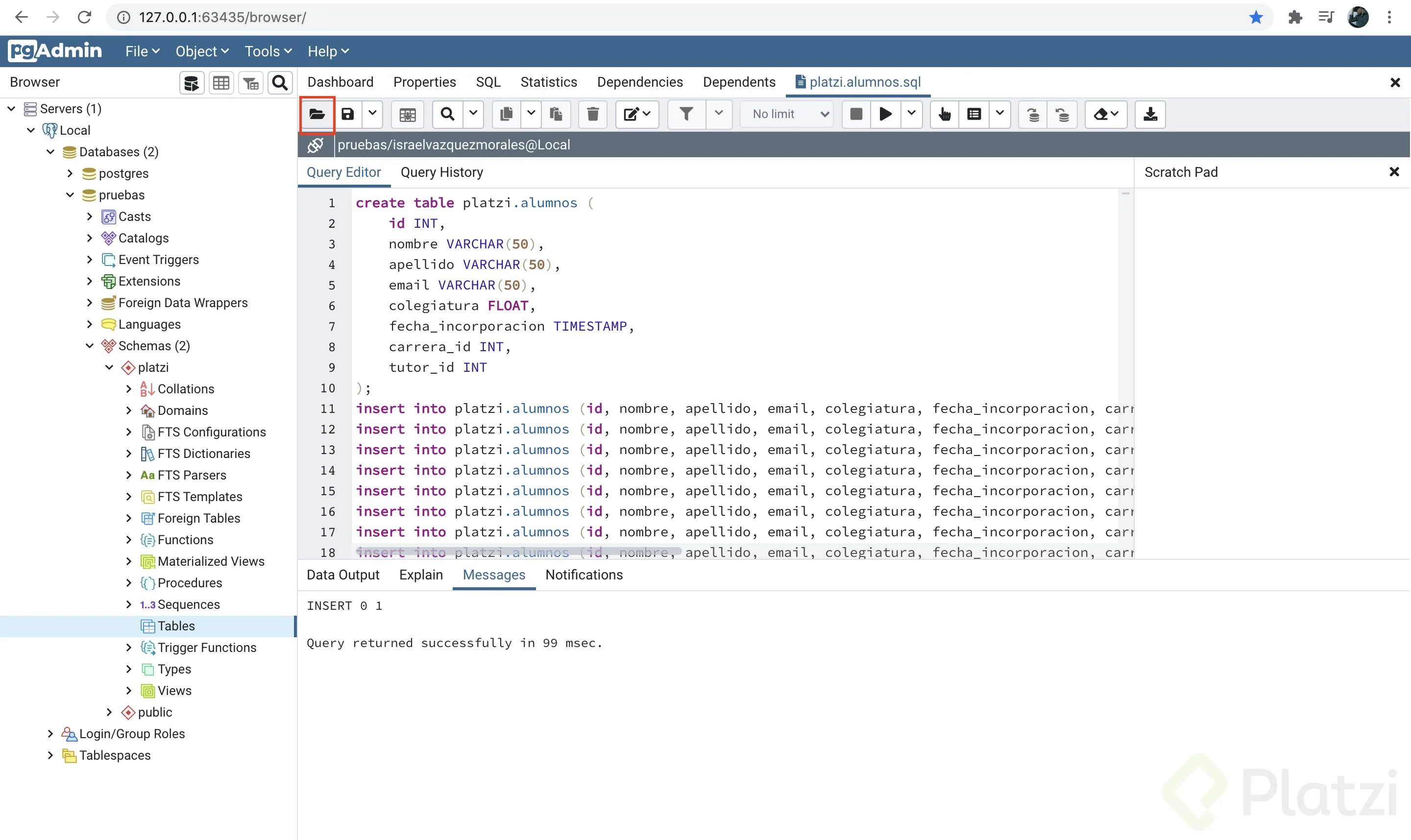
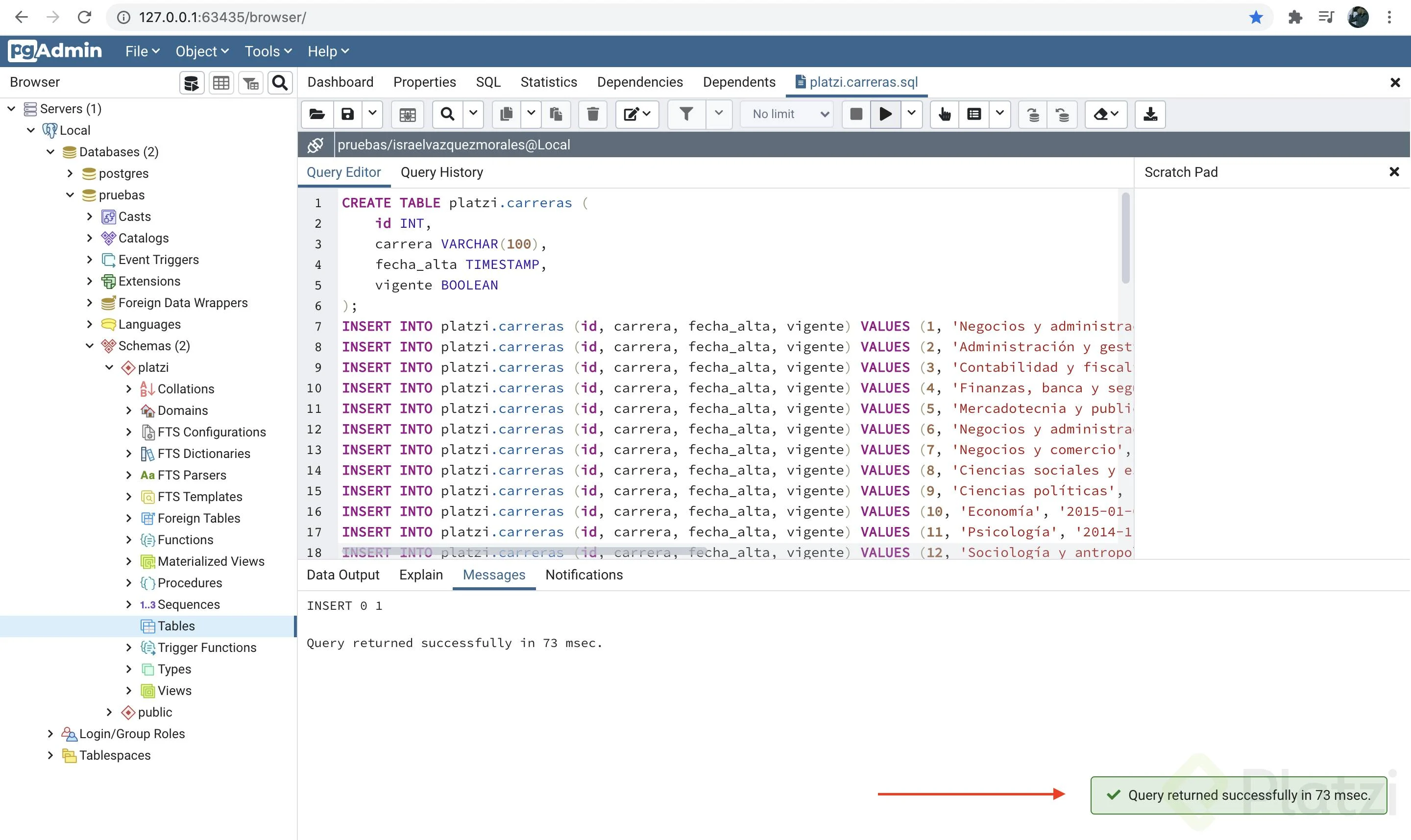
 Al terminar debes ver un aviso similar al siguiente:
Al terminar debes ver un aviso similar al siguiente:
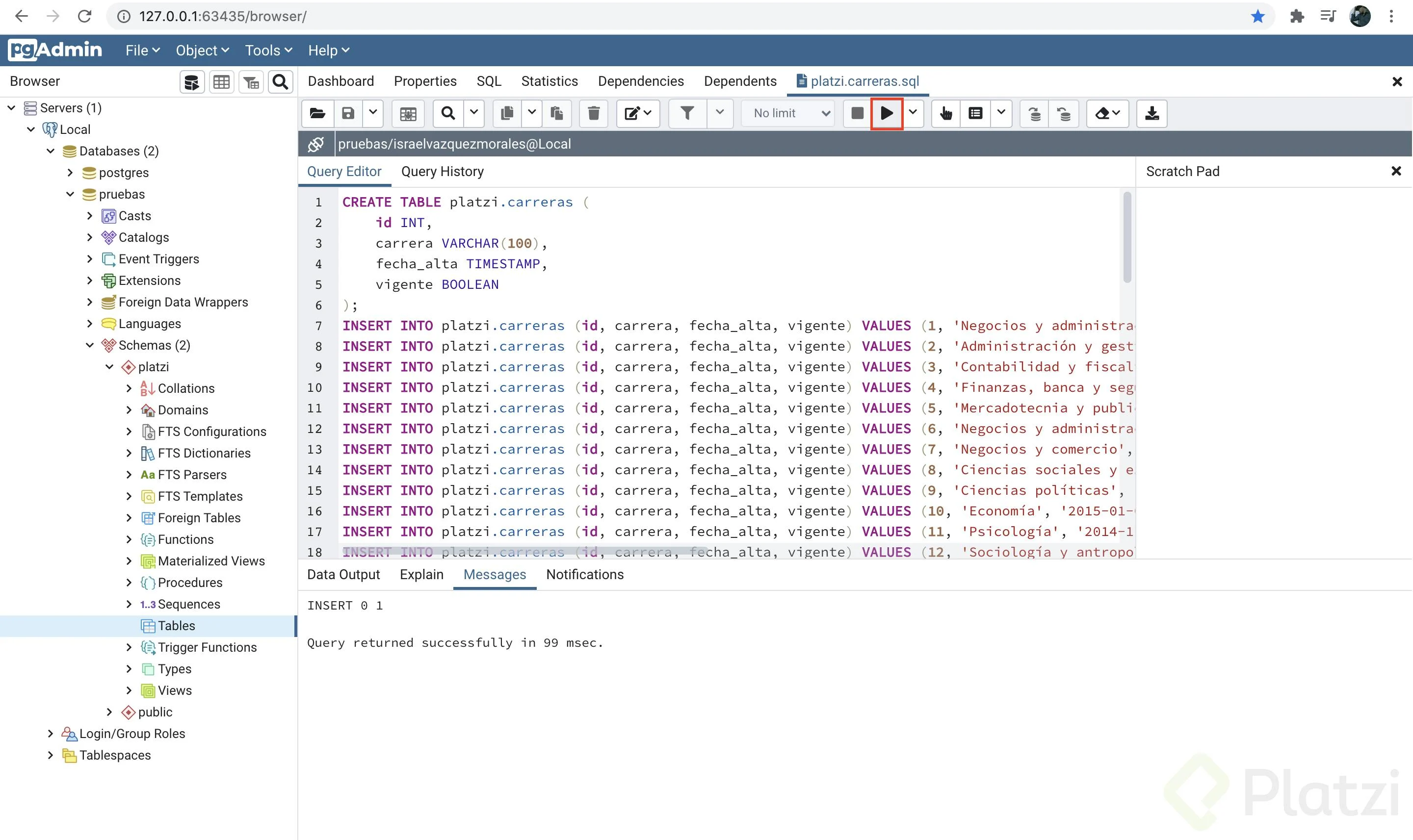
 Ahora repetiremos el proceso para la tabla platzi.carreras
Ahora repetiremos el proceso para la tabla platzi.carreras
Proyección significa elegir QUE columnas (o expresiones) la consulta debe retornar. Selección significa CUALES SON las columnas retornadas.
Supongamos la siguiente consulta:
select Columna1, Columna2, Columna3 from table_1 where n=3; La proyección sería: Columna1, Columna2 y Columna3 y la parte de Selección es n*=3,* debido a esto es que denominamos a la clausula SELECT como la proyección y los filtros aplicados en la clausula WHERE como Selección.
La Consulta más Básica sería
SELECT * FROM Tabla1; El astrisco (*) es un comodín que indica que queremos traer una proyección completa (Todos los campos o columnas existentes en la tabla)
Alias Un alias (..AS…), es otra forma de llamar a una tabla o a una columna, y se utiliza para simplificar las sentencias SQL cuando los nombres de tablas o columnas son largos o complicados.
SELECT Columna1 AS Alias1 FROM Tabla1; (Para referirnos a la Columna1, podremos denominarla como Alias1)
… .
Funciones de agregación Las funciones de agregación en SQL nos permiten efectuar operaciones sobre un conjunto de resultados, pero devolviendo un único valor agregado para todos ellos. Es decir, nos permiten obtener medias, máximos, etc… sobre un conjunto de valores.
Las funciones de agregación básicas que soportan todos los gestores de datos son las siguientes:
COUNT: devuelve el número total de filas seleccionadas por la consulta, como particularidad se puede usar COUNT()* donde contará todos los registros de la tabla incluyendo nulos. MIN: devuelve el valor mínimo del campo que especifiquemos. MAX: devuelve el valor máximo del campo que especifiquemos. SUM: suma los valores del campo que especifiquemos. Sólo se puede utilizar en columnas numéricas. AVG: devuelve el valor promedio del campo que especifiquemos. Sólo se puede utilizar en columnas numéricas. . Función IF() Función que evalúa una sola expresión y retorna lo que se le especifica en el caso que sea Verdadera o Falsa
IF (expresion, resultado_true, resultado_else) Función CASE() Sirve para evaluar una lista de condiciones y retornar uno o múltiples posibles resultados.
Comienza con la sentencia CASE, luego evalua expresiones comenzando con WHEN y en caso que sea verdadera, devolverá el resultado especificado para esa condición luego del THEN… . La sentencia ELSE es opcional y devolverá este valor en caso que todas las condiciones WHEN anteriores sean Falsas.
Si todas las condiciones son falsas, y no existe la clausula ELSE, se devolverá NULL.
CASE WHEN eval_1 THEN resultado_1 WHEN eval_2 THEN resultado_2 ... WHEN value_n THEN resultado_n ELSE resultado END AS ValorResultado;
Con SELECT se especifica que columnas queremos obtener de una tabla determinada y con FROM se indica de donde se va a obtener la información que se va proyectar con SELECT. FROM va después de SELECT
SELECT * FROM base_de_datos.tabla En la sentencia anterior el manejador de base de datos (DBMS) va al esquema y proyecta lo solicitado.
Las sentencias SQL no son sensibles a minúsculas o mayúsculas pero se recomienda escribir las palabras claves en MAÝUSCULAS y el resto en minúsculas
JOIN es un complemento de FROM.
También se puede obtener la información de una base de datos remota, es decir que el esquema de donde que queremos obtener información se encuentra en otro DBMS.
Para obtener información de una tabla que se encuentra remotamente se utiliza la función dblink, dicha función recibe dos parámetros:
configuración de conexión al DBMS remoto consulta SQL
Ejemplo de dblink
SELECT *
FROM dblink('
dbname=somedb
port=5432 host=someserver
user=someuser
password=somepwd',
'SELECT gid, area, parimeter,
state, country,
tract, blockgroup,
block, the_geom
FROM massgis.cens2000blocks')
AS blockgroups
Cúales son las TOP 10 carreras con mayor cantidad de alumnos que aun siguen vigentes?
SELECT carrera, count(alumnos.id) as "Total de alumnos", vigente
FROM platzi.alumnos
JOIN platzi.carreras as carr
ON platzi.alumnos.carrera_id = carr.id
WHERE vigente = true
GROUP BY carrera, vigente
ORDER BY "Total de alumnos" DESC
El producto cartesiano es una operación de la teoría de conjuntos en la que dos o más conjuntos se combinan entre sí. En el modelo de base de datos relacional se utiliza el producto cartesiano para interconectar conjuntos de tuplas en la forma de una tabla. El resultado de esta operación es otro conjunto de tuplas ordenadas, donde cada tupla está compuesta por un elemento de cada conjunto inicial.


WHERE es usado para filtrar registros. WHERE es cuando para extraer solamente las condiciones que cumplen con esa condición.
SELECT *
FROM tabla_diaria
WHERE id=1;
SELECT *
FROM tabla_diaria
WHERE cantidad>10;
SELECT *
FROM tabla_diaria
WHERE cantidad<100;
Este puede ser combinado con AND ,OR y NOT.
AND y OR son usados para filtrar registros de más de una condición.
AND muestra un registro si todas las condiciones separadas por AND son TRUE. OR muestra un registro si alguna de las condiciones separadas por OR son TRUE.
SELECT *
FROM tabla_diaria
WHERE cantidad > 10
AND cantidad < 100;
SELECT *
FROM tabla_diaria
WHERE cantidad BETWEEN 10
AND cantidad < 100;
BETWEEN puede ser usado para definir límites.
La separación por paréntesis es muy importante.
SELECT *
FROM users
WHERE name = "Israel"
AND (
lastname = "Vázquez"
OR
lastname = "López"
);
SELECT *
FROM users
WHERE name = "Israel"
AND
lastname = "Vázquez"
OR
lastname = "López";
En el primero va a devolver todos los que son Israel Vázquez o Israel López, en el segundo devolverá a todos los que se llaman Israel Vázquez o se apellida López(sólo apellido).
NOT valida que un dato no sea TRUE.
SELECT column1, column2, ...
FROM table_name
WHERE NOT condition;
Para especificar patrones en una columna usamos LIKE. Podemos mostrar diferentes cosas que buscamos.
SELECT *
FROM users
WHERE name LIKE "Is%";
SELECT *
FROM users
WHERE name LIKE "Is_ael";
SELECT *
FROM users
WHERE name NOT LIKE "Is_ael";
En el primero, colocamos un % para representar que se va a buscar lo que tenga is% pero que no importa los carácteres después de %. En el segundo le estamos diciendo con _ que puede haber lo que sea en medio de Is y ael. Y en el último le decimos que ponga todas las filas que no sean igual a lo que arriba estabamos buscando. Igual podemos decir que nos traiga registros que estén vacíos o que no lo estén.
SELECT *
FROM users
WHERE name IS NULL;
SELECT *
FROM users
WHERE name IS NOT NULL;
Y para seleccionar filas con datos específicos, usamos IN.
SELECT *
FROM users
WHERE name IN ('Israel','Laura','Luis');
Ejemplo comentarios
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE colegiatura = 2000;
Mayor que
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE colegiatura > 2000;
Menor que
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE colegiatura < 4000;
Entre Opcion No. 1
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE colegiatura > 2000
AND colegiatura < 4000;
Entre Opcion No. 2
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE colegiatura BETWEEN 2000 AND 4000;
And y Or Opcion No. 1
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE nombre = 'Edin'
AND (apellido = 'Keatch' OR apellido = 'Grishin');
And y Or Opcion No. 2
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE nombre = 'Edin'
AND apellido = 'Keatch'
OR apellido = 'Grishin';
Comodin que empieza con Al
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE nombre LIKE 'Al%';
Comodin que termina con Al
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE nombre LIKE '%er';
Comodin que contiene con er
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE nombre LIKE '%er%';
Comodin que no contiene con er
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE nombre NOT LIKE '%er%';
Comodin que varia la ultima letra
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE nombre LIKE 'Ali_'
Null
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE apellido IS NULL;
Not Null
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE apellido IS NOT NULL;
In
SELECT *
FROM PRUEBAS.ALUMNOS
WHERE nombre IN ('Wanda', 'Hilde', 'Veriee');
Las partes más importantes y más usadas de los queries de SQL son: -La proyección (con SELECT) -El origen de los datos (Con FROM y sus JOIN) -WHERE, que nos ayuda a filtrar las tuplas dependiendo de las condiciones que se cumplan.
Hay otras partes de los queries que son opcionales, que no encontraremos en todos los queries pero que igual juegan un papel muy importantes. Una de ellas es el ordenamiento (ORDER BY)
INDICES: excelentes para búsquedas y ordenamientos, cuando estamos haciendo queries complejos, cuando estamos tratando de extraer información constantemente, haciendo joins complicados a través de esos campos y nos sirve tener un índice que guarde el orden de ese campo en particular para hacer extracciones muy rápidas.
CUIDAR PARA ALTA TRANSACCIONALIDAD: la contrapartida de esto es que cuando tienes un índice, la parte de escritura, cuando llegas a hacer un Update de esa columna en particular en la que pusiste un índice, entonces cada escritura tardará un poco más que la anterior porque básicamente agrega un nuevo elemento, revisa todos elementos anteriores y posteriores y vuelve a ordenarlos en el índice y si agregamos otro elemento vuelve a revisar todos y a ordenarlos.
No debemos poner índices por poner sino ser muy cuidadosos de aquellas columnas que hacemos JOIN muy seguido o que tienen muchísimos datos y siempre estamos ordenando por esa columna. Es válido ponerlo pero siempre teniendo en cuenta que cuando tenemos que ingerir muchos datos o hacer muchos INSERT no es bueno tener índices en esas tablas (o tener la menor cantidad de índices posible). Es importante tener en mente cuántas lecturas Vs cuántas escrituras haces en una tabla o en un campo particular para decidir si conviene poner un índice. Si vas a hacer muchas escrituras por segundo no es conveniente poner índices o tratar de mantenerlo al mínimo. En cambio, si realmente escribes muy poco en esa tabla pero haces búsquedas constantes y muchos Joins sobre esa tabla entonces vale la pena usar el índice sobre ese campo en particular donde haces el Join o donde haces el ordenamiento porque es un gran complemento para nuestra cláusula ORDER BY.
Ordenamiento
SELECT *
FROM PRUEBAS.ALUMNOS
ORDER BY fecha_incorporacion;
Ascendente
SELECT *
FROM PRUEBAS.ALUMNOS
ORDER BY fecha_incorporacion ASC;
Descendente
SELECT *
FROM PRUEBAS.ALUMNOS
ORDER BY fecha_incorporacion DESC;
GROUP BY es una sentencia que agrupa filas que tienen el mismo valor en columnas con el sumatorio. Como decirle ‘encuentra el número de clientes en cada país’.
Suele usarse frecuentemente con las funciones COUNT MAX MIN MAX SUM AVG a un grupo de una o más columnas.
SELECT *
FROM tabla_diaria
GROUP BY marca;
SELECT *
FROM tabla_diaria;
GROUP BY marca, modelo;
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
ORDER BY COUNT(CustomerID) DESC;
SELECT TOP es usada para especificar el número de registros que se van a retornar.
SELECT TOP es útil para tablas con miles de registros, pues un gran número de registros puede afectar el rendimiento.
SELECT TOP number
FROM table1
WHERE condition;
SELECT TOP 1500
FROM tabla_diaria;
SELECT *
--el row que queremos medir y la totalidad de row en un grupo,
--si no seleccionas nada es toda la tabla
from (
--window function row_number
--trae el numero de registro indiferente al criterio que seponga
-- over si no pone nada trae toda la tabla es agnostico
select row_number() over() as row_id, *
from platzi.alumnos
) as alumnos_with_row_num
;
Reto: Primeros 5 registros de la tabla 1.
SELECT *
from (
select row_number() over() as row_id, *
from platzi.alumnos
) as alumnos_with_row_num
limit 5;
SELECT *
from (
select row_number() over() as row_id, *
from platzi.alumnos
) as alumnos_with_row_num
where row_id <= 5;
SELECT * from platzi.alumnos
limit 5;
SELECT * from platzi.alumnos
where id <= 5;
SELECT * from platzi.alumnos
fetch first 5 rows only;
SELECT *
from (
select row_number() over() as row_id, *
from platzi.alumnos
) as alumnos_with_row_num
fetch first 5 row_id only;
SELECT * from platzi.alumnos
where id BETWEEN 1 and 5;
SELECT *
from (
select row_number() over() as row_id, *
from platzi.alumnos
) as alumnos_with_row_num
where row_id BETWEEN 1 and 5;
SELECT * from platzi.alumnos
where 1<= id and id <=5;
Ejemplo 1
-- distinct trae los valores no repetidos
SELECT DISTINCT colegiatura
from platzi.alumnos as al
where 2 =(
select count(distinct colegiatura)
from platzi.alumnos as al2
where al.colegiatura<=al2.colegiatura
);
select distinct colegiatura,tutor_id
from platzi.alumnos
where tutor_id=20
order by colegiatura DESC
limit 1 offset 1;
select *
from platzi.alumnos as datos
inner join
(
select distinct colegiatura
from platzi.alumnos
where tutor_id=20
order by colegiatura desc
limit 1 offset 1
) as segunda_mayor_colegiatura
on datos.colegiatura = segunda_mayor_colegiatura.colegiatura;
select *
from platzi.alumnos as datos
where colegiatura=(
select distinct colegiatura
from platzi.alumnos
where tutor_id=20
order by colegiatura DESC
limit 1 offset 1
)
Reto la segundo mitad de la tabla
SELECT *
FROM platzi.alumnos
OFFSET ( SELECT (COUNT(id)/2) FROM platzi.alumnos )
SELECT *
FROM platzi.alumnos
WHERE id > 500
;
SELECT * FROM platzi.alumnos
LIMIT 500 OFFSET 500;
SELECT *
FROM platzi.alumnos
OFFSET 499;
Ejemplos:
select *
from(
select row_number() over() as row_id,*
from platzi.alumnos
)as alumnos_with_row_num
-- valores separados por coma recibe in para que los traiga especificamente
where row_id in (1,5,10,12,15,20);
select *
from platzi.alumnos
where id in(
select id
from platzi.alumnos
where tutor_id=30
);
Retos
select *
from platzi.alumnos
where id not in(
select id
from platzi.alumnos
where tutor_id=30
);
select *
from platzi.alumnos
where id in(
select id
from platzi.alumnos
where tutor_id!=30
);
select *
from platzi.alumnos
where id in(
select id
from platzi.alumnos
where tutor_id<>30
);
Ejemplos:
select extract( year from fecha_incorporacion) as years
from platzi.alumnos;
select date_part('Year',fecha_incorporacion) as years
from platzi.alumnos;
select date_part('Year',fecha_incorporacion) as years,
date_part('Month',fecha_incorporacion) as months,
date_part('Days',fecha_incorporacion) as days
from platzi.alumnos;
Reto Hora Minuto Segundo
select date_part('Hour',fecha_incorporacion) as Hours,
date_part('Minute',fecha_incorporacion) as Minutes,
date_part('Second',fecha_incorporacion) as Seconds
from platzi.alumnos;
SELECT
extract( HOUR from fecha_incorporacion) as hora,
extract( MINUTE from fecha_incorporacion) as minutos,
extract( SECOND from fecha_incorporacion) as segundos
from platzi.alumnos;
Ejemplos
select *
from platzi.alumnos
where (
extract(year from fecha_incorporacion))=2019;
select *
from platzi.alumnos
where ( Date_part('Year',fecha_incorporacion))=2019;
select *
from (
select*,
Date_part('Year',fecha_incorporacion) as years
from platzi.alumnos
)as alumnos_year
where years=2020
Reto
select *
from platzi.alumnos
where
extract(year from fecha_incorporacion)=2018
and
extract(month from fecha_incorporacion)=05;
SELECT *
FROM (
SELECT *,
DATE_PART('YEAR', fecha_incorporacion) AS annio_inicio,
DATE_PART('MONTH', fecha_incorporacion) AS mes_inicio
FROM platzi.alumnos
) AS year_alumnos
WHERE annio_inicio = 2018 AND mes_inicio = 5;
Ejercicios interesantes 1 Dia 2018
--el día de la semana en donde
--mas se registraron personas para el 2018
SELECT
case
when extract(DOW from fecha_incorporacion) = 0 then'domingo'
when extract(DOW from fecha_incorporacion) = 1 then'lunes'
when extract(DOW from fecha_incorporacion) = 2 then'martes'
when extract(DOW from fecha_incorporacion) = 3 then'miercoles'
when extract(DOW from fecha_incorporacion) = 4 then'jueves'
when extract(DOW from fecha_incorporacion) = 5 then'viernes'
when extract(DOW from fecha_incorporacion) = 6 then'sabado'
end dia_semana,
COUNT(*) AS total
from platzi.alumnos
where extract(YEAR from fecha_incorporacion) = 2018
group by dia_semana
order by total desc;
2 dia 2018
--el día de la semana en donde
--mas se registraron personas para el 2018
select extract(dow from fecha_incorporacion) as dia,
count(extract(dow from fecha_incorporacion)) as conteo
FROM platzi.alumnos
where extract(YEAR from fecha_incorporacion) = 2018
GROUP by dia
order by conteo desc;
3 mes 2018
--el mes en donde mas se registraron personas para el 2018
select extract(month from fecha_incorporacion) as mes,
count(extract(month from fecha_incorporacion)) as conteo
FROM platzi.alumnos
GROUP by mes
order by mes asc;
En el ejercicio de encontrar un DUPLICADO, se está haciendo una partición de la tabla de todos los valores en filas de cada una de las variables o columnas de la tabla a excepción del id, el cual no puede ser igual y no se repite al ser una primary key.
Cuando se aplica esta partición en cada valor se hace único los valores, es decir, cada row viene siendo una partición, y al utilizar la función agregada que en este caso es ROW_NUMBER() va a contar los valores de cada una de las particiones haciendo que se reinicie los “números de fila” cuando salta de partición en partición. por eso, cuando encuentra dos valores iguales, enumera los dos valores, dejando como valor en su row un 2. Ejemplos
--seleccionar aquel registro que esta repetido
select *
from platzi.alumnos as ou
where(
select count(*)
from platzi.alumnos as inr
where ou.id=inr.id
)>1;
--select a todos los campos de la tabla
-- :: es hacer un case, que convierte todos
--los campos en un texto
select(platzi.alumnos.*)::text, count(*)
from platzi.alumnos
group by platzi.alumnos.*
HAVING count(*)>1
select(platzi.alumnos.nombre,
platzi.alumnos.apellido,
platzi.alumnos.email,
platzi.alumnos.colegiatura,
platzi.alumnos.fecha_incorporacion
)::text, count(*)
from platzi.alumnos
group by platzi.alumnos.nombre,platzi.alumnos.apellido,
platzi.alumnos.email, platzi.alumnos.colegiatura,
platzi.alumnos.fecha_incorporacion
HAVING count(*)>1
select*
from(
select id,
row_number() over(
partition by
nombre,
apellido,
email,
colegiatura,
fecha_incorporacion,
carrera_id,
tutor_id
order by id asc
)AS row,
*
from platzi.alumnos
)AS duplicados
where duplicados.row > 1
Reto
DELETE FROM platzi.alumnos
WHERE id IN (
SELECT id
FROM (
SELECT id,
ROW_NUMBER() over(
PARTITION BY
nombre,
apellido,
email,
colegiatura,
fecha_incorporacion,
carrera_id,
tutor_id
ORDER BY id ASC
)AS row
FROM platzi.alumnos
)AS duplicados
WHERE duplicados.row > 1)
Los tipos de rango que vienen en PostgreSQL son:
int4range: Que trae un rango de enteros.
int8range: Es un rango de enteros grandes.
numrange: Es un rango numérico.
tsrange: Es un rango del tipo timestamp pero sin la zona horaria.
tstzrange: Es un rango del tipo timestamp con la zona horaria
daterange: Es un rango del tipo fecha.
=>’ Significa ‘devuelve’ en este apunte
‘&&’ si se solapan estos dos rangos
(11.1,22.2) && (20.0,30.0) => TRUE (11.1,19.9) && (20.0,30.0) => FALSE
- Para seleccionar los elementos de la interseccion entre los dos rangos. SI no hay, marca error
SELECT int4ramge(10,20) * int4range(15,25) =>[15,20)
@> si el rango se encuentra en el grupo
SELECT *
FROM platzi.alumnos
WHERE int4range(10,20) @> tutor_id
select *
from platzi.alumnos
where tutor_id in (1,2,3,4);
select *
from platzi.alumnos
where tutor_id >=1
and tutor_id <=10;
--genera enteros de 10 a 20 @> si pertenece o no
select int4range(10,20)@>3;
-- genera un rango numerico mas amplio que incluye decimales
select numrange(11.1,22.2) && numrange(20.0,30.0);
-- upper valor mas alto del rango
select upper (int8range(15,25));
-- lower valor mas bajo del rango
select lower (int8range(15,25));
--* nos devuelve la interseccion entre ambos rangos
select int4range(10,20)* int4range(15,25);
--nos comprueba si el conjunto es vacio o no
select isempty (numrange(1,5));
select *
from platzi.alumnos
where int4range(10,20) @> tutor_id;
reto
select
int8range(min(tutor_id),max(tutor_id))
* int8range(min(carrera_id),max(carrera_id))
from platzi.alumnos
Ejemplos:
select fecha_incorporacion
from platzi.alumnos
order by fecha_incorporacion desc
limit 1;
--trae todos los registros por que la fecha tiene hasta segundos
--haciendo diferente cada dato
select carrera_id, fecha_incorporacion
from platzi.alumnos
group by carrera_id, fecha_incorporacion
order by fecha_incorporacion desc;
--limit permite solamente de la tabla completa
--max permite agrupar de acuerdo a mas criterios
-- cual es la fecha mas reciente en la que un alumno
--ingreso a una carrera
select carrera_id, max(fecha_incorporacion)
from platzi.alumnos
group by carrera_id
order by carrera_id;
Retos:
--minimo nombre
select min(nombre)
from platzi.alumnos
-- minimo por id de tutor
select tutor_id,min(nombre)
from platzi.alumnos
group by tutor_id
order by tutor_id;
SELF JOINS
Personalmente considero que a la hora de hacer self-joins es de especial importancia más que en otros casos el hecho de comentar el código En este caso aclararía en el código que recurrí a esta técnica, ya que los tutores a la vez son alumnos, de ahí que puedo obtener toda la información de la propia tabla
select a.nombre,a.apellido,t.nombre,t.apellido
from platzi.alumnos as a
inner join platzi.alumnos as t
on a.tutor_id = t.id
-- 10 tutores que tienen mas alumnos
select concat(t.nombre,'-',t.apellido) as tutor ,
count(*) as alumnos_por_tutor
from platzi.alumnos as a
inner join platzi.alumnos as t
on a.tutor_id = t.id
group by tutor
order by alumnos_por_tutor desc
limit 10;
Reto version 1
select AVG(alumnos_por_tutor) as promedio_alumnos
from(
select concat(t.nombre,' ',t.apellido) as tutor ,
count(*) as alumnos_por_tutor
from platzi.alumnos as a
--se asume que los tutores son alumnos pero no todos los alumnos son tutores
inner join platzi.alumnos as t on a.tutor_id = t.id
group by tutor
order by alumnos_por_tutor desc)
as promedio;
Version 2
SELECT AVG(n_alumnos) AS promedio_alumnos
FROM (
SELECT COUNT(*) AS n_alumnos FROM platzi.alumnos
GROUP BY tutor_id
) AS tabla_num_alumnos_por_tutor;
tutores promedio por carrera v1
select AVG(prom_tutor.tutor_carrera) as promedio_alumnos
from(
select concat(t.nombre,' ',t.apellido) as tutor ,
count(*) as tutor_carrera, a.carrera_id
from platzi.alumnos as a
inner join platzi.alumnos as t on a.tutor_id = t.id
and a.carrera_id=t.tutor_id
group by tutor,a.carrera_id
order by tutor_carrera desc)
as prom_tutor;
Ejemplos
select carrera_id, count(*) as cuenta
from platzi.alumnos
group by carrera_id
order by cuenta desc;
De la tabla carrera Borrar id entre 30-40
delete from platzi.carreras
where id between 30 and 40;
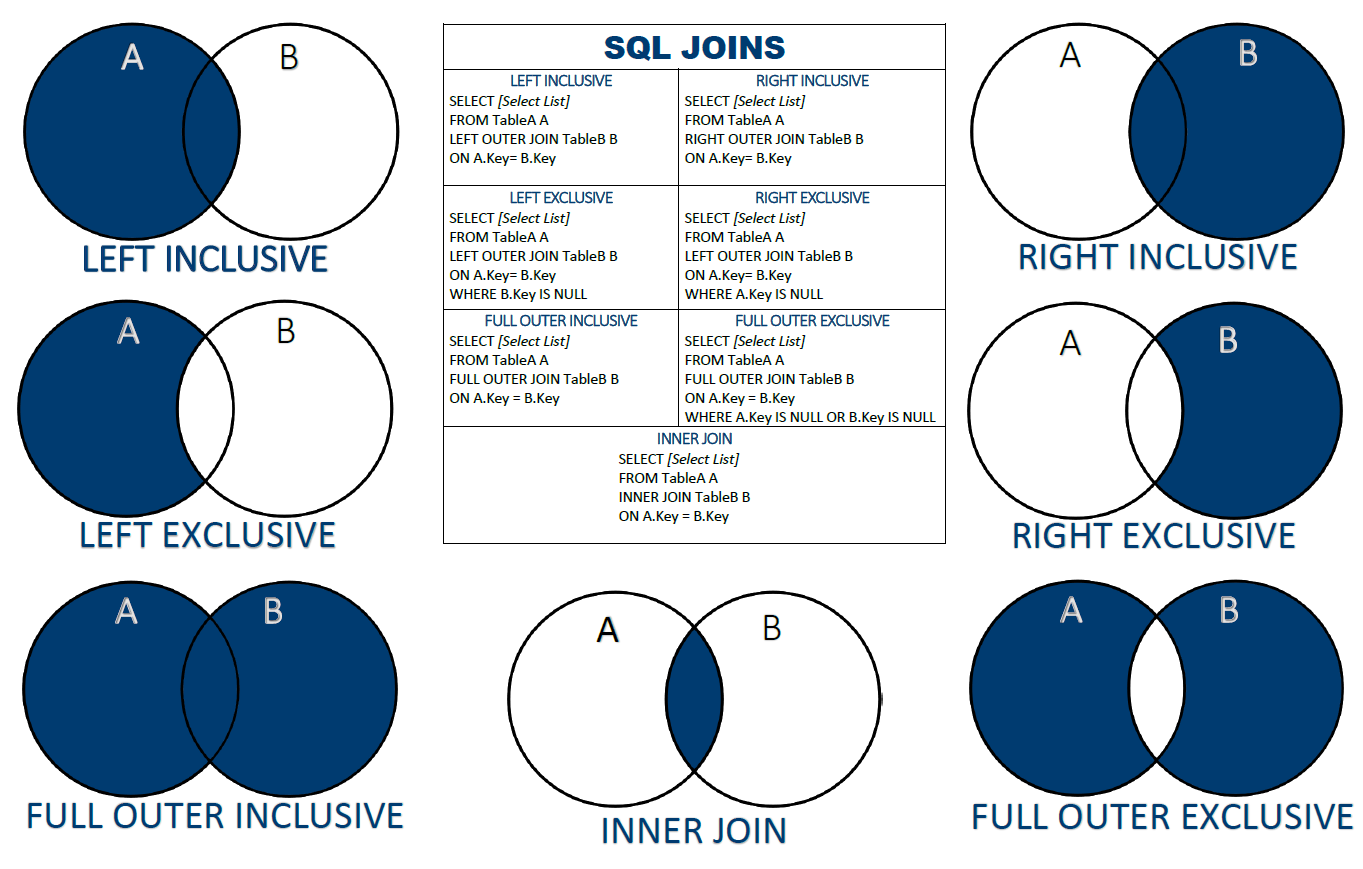
left join exclusive
select concat(a.nombre,'-',a.apellido) as alumno,
a.carrera_id,
c.id,
c.carrera
from platzi.alumnos as a
--left join nos interesa la tabla a la izquierda
-- que es la primera tabla que ponemos
--en el from
left join platzi.carreras as c
on a.carrera_id = c.id
-- solo los datos tabla alumnos
-- cuales son los alumnos que se quedaron sin carrera
where c.id is null
order by a.carrera_id desc;
Reto
select concat(a.nombre,'-',a.apellido) as alumno,
a.carrera_id,
c.id,
c.carrera
from platzi.alumnos as a
full outer join platzi.carreras as c
on a.carrera_id = c.id
order by a.carrera_id desc;
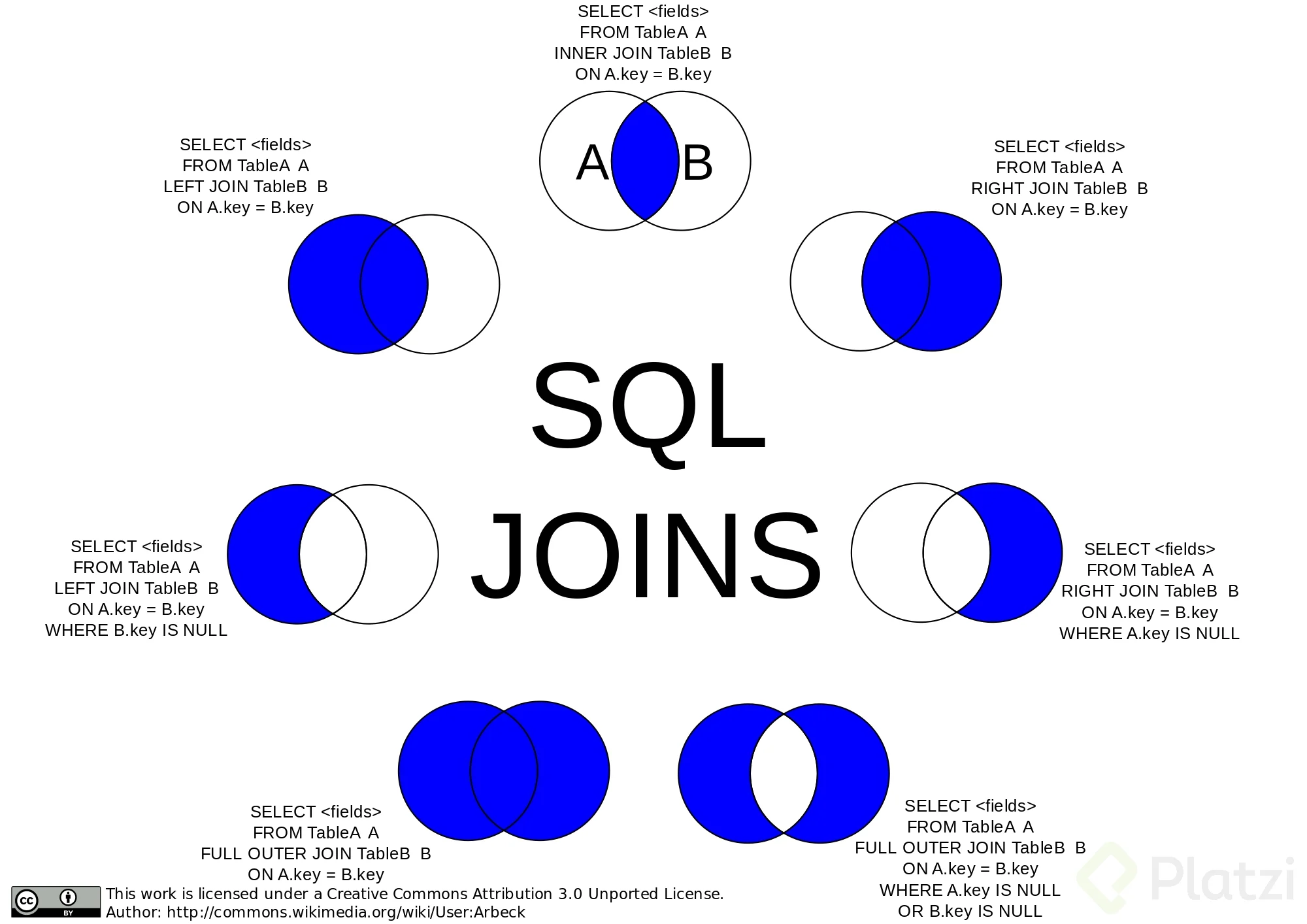 Ejemplos:
Left join exlusivo
Ejemplos:
Left join exlusivo
--la tabla alumnos sin interseccion
select concat(a.nombre,'-',a.apellido) as alumno,
a.carrera_id,
c.id,
c.carrera
from platzi.alumnos as a
left join platzi.carreras as c
on a.carrera_id = c.id
where c.id is null
order by c.id desc;
left join
--tabla alumnos incluyendo la interseccion
select concat(a.nombre,'-',a.apellido) as alumno,
a.carrera_id,
c.id,
c.carrera
from platzi.alumnos as a
left join platzi.carreras as c
on a.carrera_id = c.id
order by c.id desc;
right join
-- tabla carrera con intersecion
select concat(a.nombre,'-',a.apellido) as alumno,
a.carrera_id,
c.id,
c.carrera
from platzi.alumnos as a
right join platzi.carreras as c
on a.carrera_id = c.id
order by c.id desc;
right join exlusivo
-- tabla carrera sin intersecion
select concat(a.nombre,'-',a.apellido) as alumno,
a.carrera_id,
c.id,
c.carrera
from platzi.alumnos as a
right join platzi.carreras as c
on a.carrera_id = c.id
where a.id is null
order by c.id desc;
Inner join join por default es el inner join
-- la parte en comun que tiene ambas tablas
-- la interseccion
select concat(a.nombre,'-',a.apellido) as alumno,
a.carrera_id,
c.id,
c.carrera
from platzi.alumnos as a
inner join platzi.carreras as c
on a.carrera_id = c.id
order by c.id desc;
Full outer join ambas tablas completas
-- ambas tablas
select concat(a.nombre,'-',a.apellido) as alumno,
a.carrera_id,
c.id,
c.carrera
from platzi.alumnos as a
full outer join platzi.carreras as c
on a.carrera_id = c.id
order by a.carrera_id desc, c.id desc;
Diferencia simetrica
-- es la tabla carrera y alumnos sin la interseccion
select concat(a.nombre,'-',a.apellido) as alumno,
a.carrera_id,
c.id,
c.carrera
from platzi.alumnos as a
full outer join platzi.carreras as c
on a.carrera_id = c.id
where a.id is null or c.id is null
order by a.carrera_id desc, c.id desc;
Lpad: rellena por la izquierda. P.e. lpad(‘437’,5,‘0’) tendría como resultado 00437.
RPad: rellena por la derecha. P.e. rpad(‘437’,5,‘0’) tendría como resultado 43700.
Lpad -- que sql se muestre al final -- despues de * aparesca 15 veces --lpad alconchonamiento a la izquierda --con que rellenas a la izquierda -- para que al final aparezca la cadena --del principio o primer '' --lpad estatico
select lpad('sql',15,'*')
lpad dinamico
--a sql le va añadiendo
--cuando id 1 solo sale s
--cuando id 2 solo sale sq
--cuando id 3 sale sql
--apartir de id 4 en adelante
--va agregando * por cada id adicional
select lpad('sql',id,'*')
from platzi.alumnos
where id<10
select lpad('*',cast(row_id as int),'*')
from(
select row_number() over(order by carrera_id) as row_id, *
from platzi.alumnos
)as alumnos_row
where row_id <=5
order by carrera_id;
Reto rpad realiza la funcion contraria a lpd empieza por sql luego llena con 15 *
select rpad('sql',15,'*')
/* TOKENIZANDO */ para esconder informacion de usuarios
SELECT nombre,rpad(SUBSTR(nombre, 1, 2),LENGTH(nombre),'*'),
apellido,rpad(SUBSTR(apellido, 1, 2),LENGTH(apellido),'*'),
email,rpad(SUBSTR(email, 1, 2),LENGTH(email),'*')
FROM platzi.alumnos
Generando Rangos
Se hace con la función generate_series() Genera una tabla con una única columna dinámica Recibe tres parámetros El primero es el número de inicio de la serie El segundo es el final de la serie El tercero es el delta o paso, que puede ser negativo si hay overlap Overlap es cuando el numero de inicio > numero de final Se pueden utilizar fechas El delta se puede escribir literal para el caso de timestamps
El tercer parámetro de generate_series tiene el formato : {optional}step/interval]
El cual indica que no siempre es necesario, como los primeros ejemplos.
El parámetro “step” numérico o timestamp
El tercer parámetro es el intervalo y en caso de ser timestamp puede pasarse cualquiera de estos :
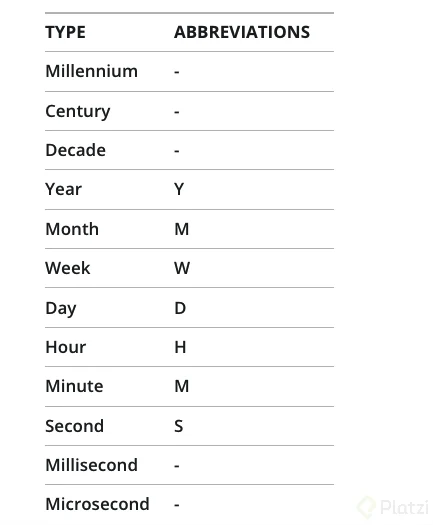
Ejemplos:
--generar series
select *
from generate_series(1,4);
-- tercer parametro se indican los pasos o delta
select *
from generate_series(5,1,-2);
--si el primero es mayor al segundo intervalo
-- se genera un resultado vacio
select *
from generate_series(4,3);
--tambien funciona con numeros decimales
select *
from generate_series(1.1,4,1.3);
--series de tiempo
-- fecha actual mas el numero de dias que vaya
-- en cada tupla generada
select current_date +s.a as dates
from generate_series(0,14,7) as s(a)
select *
from generate_series('2020-09-01 00:00:00'::timestamp,
'2020-09-04 12:00:00','10 hours')
-- alumnos que tienen un carrera id 1 al 10
select a.id,a.nombre, a.carrera_id, s.a
from platzi.alumnos as a
inner join generate_series(0,10) as s(a)
on s.a=a.carrera_id
order by a.carrera_id
Reto
select lpad('-',generate_series(10,0,-1),'*')
select lpad('-',generate_series(0,10),'*')
SELECT lpad('\', s.a, rpad(lpad('/', d.e, ' '), s.a, '*'))
FROM generate_series(18, 26) AS s(a),
generate_series(17,0,-2) AS d(e)
LIMIT 10;
--expresiones regulares sirven para hacer
--comprobaciones
-- de la a a la z por 9 espacios
--luego el arroba de la a a la z 9 espacios
select email
from platzi.alumnos
where email ~*'[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}'
select email
from platzi.alumnos
where email ~*'[A-Z0-9._%+-]+@google[A-Z0-9.-]+\.[A-Z]{2,4}'
Resumen: Las bases de datos distribuidas: es una colección de múltiples bases de datos separadas físicamente que se comunican mediante una red informática.
VENTAJAS:
-desarrollo modular. -incrementa la confiabilidad. -mejora el rendimiento. -mayor disponibilidad. -rapidez de respuesta.
DESVENTAJAS:
-Manejo de seguridad. -complejidad de procesamiento. -Integridad de datos más compleja. -Costo.
TIPOS:
Homogéneas: mismo tipo de BD, manejador y sistema operativo. (aunque esté distribuida). Heterogénea: puede que varíen alguna de los anteriores características. -OS -Sistema de bases de datos. -Modelo de datos.
ARQUITECTURAS: -** cliente- servidor**: donde hay una BD principal y tiene varias BD que sirven como clientes o como esclavas que tratarán de obtener datos de la principal, a la que normalmente se hacen las escrituras.
Par a par (peer 2 peer): donde todos los puntos en la red de bd son iguales y se hablan como iguales sin tener que responder a una sola entidad. multi manejador de bases de datos. ESTRATEGIA DE DISEÑO:
top down: es cuando planeas muy bien la BD y la vas configurando de arriba hacia abajo de acuerdo a tus necesidades. bottom up: ya existe esa BD y tratas de construir encima. ALMACENAMIENTO DISTRIBUIDO:
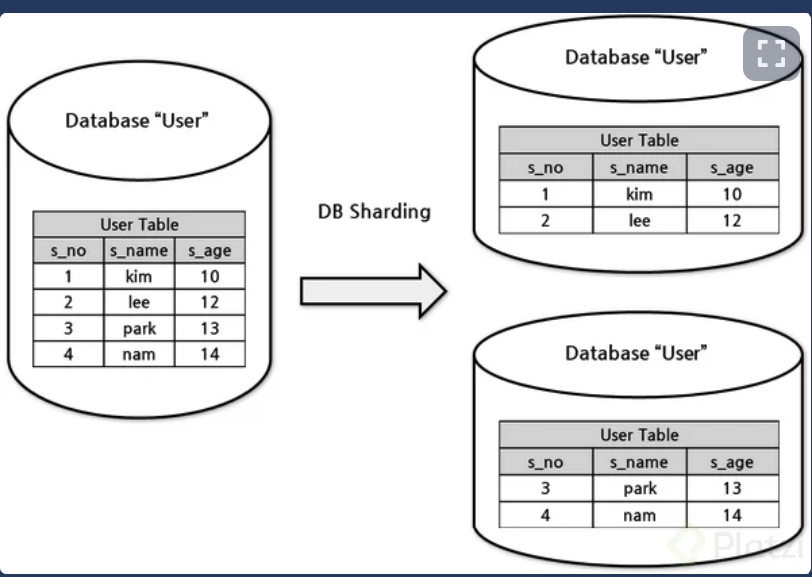
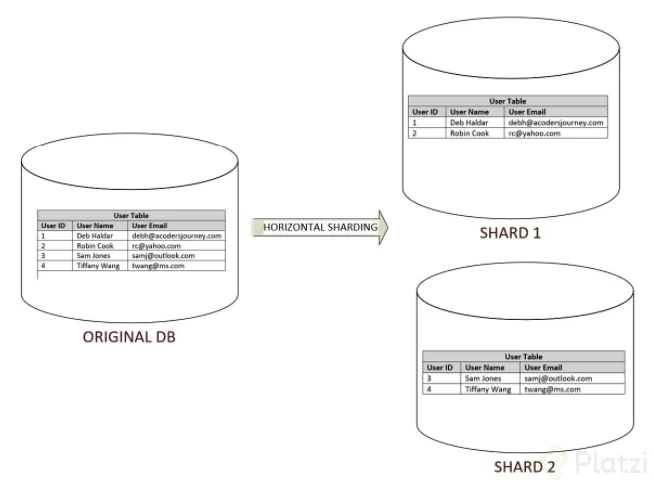
-Fragmentación: qué datos van en dónde.
fragmentación horizontal: (sharding) partir la tabla que estás utilizando en diferentes pedazos horizontales.
fragmentación vertical: cuando parto por columnas.
fragmentación mixta: cuando tienes algunas columnas y algunos datos en un lugar y algunas columnas y algunas tuplas en otro lugar.
-Replicación: tienes los mismos datos en todas ala BBDD no importa donde estén.
-replicación completa: cuando toda al BD está en varias versiones a lo largo del globo, toda la información está igualita en todas las instancias de BD. -replicación parcial: cuando algunos datos están replicados y compartidos en varias zonas geográficas -sin replicación: no estás replicando nada de los datos, cada uno está completamente separa y no tienen que estarse hablando para sincronizar datos entre ellas.
DISTRIBUCIÓN DE DATOS:
-Distribución: cómo va a pasar la data entre una BD y otra. Tiene que ver mucho con networking, tiempos, latencia, etc. Pueden ser:
Centralizada: cuando la distribuyes des un punto central a todas las demás Particionada: está partida en cada una de las diversas zonas geográficas y se comparten información entre ellas. Replicada: tener la misma información en todas y entre ellas se hablan para siempre tener la misma versión.
En el caso que la base de datos se encuentra distribuida en multiples regiones y la informacion se encuentra fragmentada la construccion de queries debe tener un debido nivel de analisis.
Debido a que en una sola base de datos responder una misma pregunta puede tener multiples soluciones con diferencias de ejecuccion en el rango de milisegundos. Pero en las bases de datos distribuidas dependiendo de en donde se encuentre la informacion fisicamente, que informacion hay en cada region y que pregunta se quiere contestar, las diferentes formas de resolver la pregunta mediante una consulta SQL puede tener vastas diferencias en el tiempo de ejecucion,como ejemplo algunas soluciones pudiesen llegar al rango de 5 horas para ejecutarse y otras solamente necesitando 0.10 segundos.
Existen cálculos que ayudan a preveer estos tiempos de respuesta, por ejemplo:
Retraso total de comunicación = (Retraso total de acceso) + (volumen total de datos / tasa de transferencia)
Analiza cual tabla tiene la menor cantidad de datos (columnas+tablas) Filtra esos registros donde sea menor cantidad Trae esos pocos registros a la misma región donde están la mayor cantidad de datos evitar realizar JOINs cuando se encuentran en zonas geográficamente diferentes.
Dividir la data en varios servidores por algun criterio util para ti
Es un tipo de partición horizontal para nuestras bases de datos. Divide las tuplas de nuestras tablas en diferentes ubicaciones de acuerdo a ciertos criterios de modo que para hacer consultas, las tendremos que dirigir al shard o parte que corresponda.
Cuándo usar Cuando tenemos grandes volúmenes de información estática que representa un problema para obtener solo unas cuantas tuplas en consultas frecuentes.
Inconvenientes Cuando debamos hacer joins frecuentemente entre shards Baja elasticidad. Los shards crecen de forma irregular unos más que otros y vuelve a ser necesario usar sharding (subsharding) La llave primaria pierde utilidad
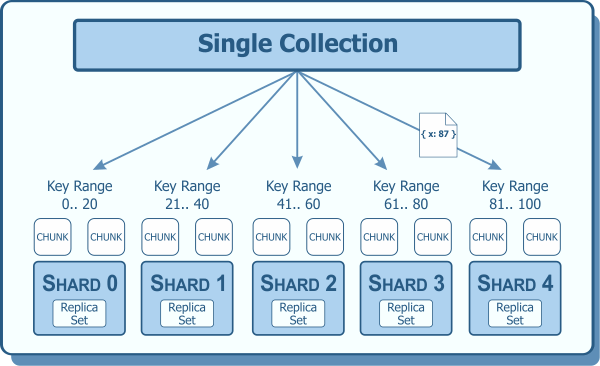
Window Functions Realizan cálculos que relacionan una tupla con el resto dentro de un mismo scope o partición.
Evita el uso del self joins Reduce la complejidad alrededor de la analítica, agregaciones y cálculos Luego de una agregación, la función OVER dicta el scope de la window function, al realizar un PARTITION BY campo Si no se especifica un PARTITION BY, la funcion OVER() por default tomará toda la tabla También se puede usar ORDER BY campo, esto agrega un campo de granularidad al cálculo, a la vez que agrupa todos los valores iguales dentro de la partición, que ahora se encuentran ordenados
SELECT *
SUM(colegiatura) OVER (PARTITION BY carrera_id ORDER BY colegiatura)
FROM platzi.alumnos;
Podemos usar funciones de RANK()
Las Window Function se procesan casi al final de todas las operaciones, por eso para usar estas WF como un campo en WHERE, debemos hacer un subquery
SELECT *
FROM (
SELECT *,
RANK() OVER (PARTITION BY carrera_id ORDER BY colegiatura DESC) AS brand_rank
FROM platzi.alumnos
) AS ranked_colegiaturas_por_carrera
WHERE brand_rank < 3
ORDER BY brand_rank;
select *,
aVG(colegiatura) over(partition by carrera_id)
from platzi.alumnos;
select *,
sum(colegiatura) over(partition by carrera_id order by carrera_id)
from platzi.alumnos;
select *,
rank() over(partition by carrera_id order by colegiatura desc)
from platzi.alumnos;
select *,
rank() over(partition by carrera_id order by colegiatura desc) as brand_rank
from platzi.alumnos
order by carrera_id, brand_rank;
select *
from(
select *,
rank() over(partition by carrera_id order by colegiatura desc) as brand_rank
from platzi.alumnos
) as ranked_colegiatura_carrera
where brand_rank <3
order by brand_rank;
- ROW_NUMBER(): nos da el numero de la tupla que estamos utilizando en ese momento.
- OVER([PARTITION BY column] [ORDER BY column DIR]): nos deja Particionar y Ordenar la window function.
- PARTITION BY(column/s): es un group by para la window function, se coloca dentro de OVER.
- FIRST_VALUE(column): devuelve el primer valor de una serie de datos.
- LAST_VALUE(column): Devuelve el ultimo valor de una serie de datos.
- NTH_VALUE(column, row_number): Recibe la columna y el numero de row que queremos devolver de una serie de datos
- RANK(): nos dice el lugar que ocupa de acuerdo a el orden de cada tupla, deja gaps entre los valores.
- DENSE_RANK(): Es un rango mas denso que trata de eliminar los gaps que nos deja RANK.
- PERCENT_RANK(): Categoriza de acuerdo a lugar que ocupa igual que los anteriores pero por porcentajes.
-- row number orden consecutivo por row
select row_number() over() as row_id,*
from platzi.alumnos
--ordenado por fecha de incorporacion
select row_number() over(order by fecha_incorporacion) as row_id,*
from platzi.alumnos
select first_value(colegiatura) over() as row_id,*
from platzi.alumnos
--va arrojar el primer valor de colegiatura por carrera id
select first_value(colegiatura) over(partition by carrera_id) as primera,*
from platzi.alumnos
select last_value(colegiatura) over(partition by carrera_id) as ultima,*
from platzi.alumnos
select nth_value(colegiatura,3) over(partition by carrera_id) as enesimo,*
from platzi.alumnos
--gank o saltos deja el rank
select *,
rank() over(partition by carrera_id order by colegiatura desc) as ranka
from platzi.alumnos
order by carrera_id, ranka;
select *,
dense_rank() over(partition by carrera_id order by colegiatura desc) as ranka
from platzi.alumnos
order by carrera_id, ranka;
select *,
percent_rank() over(partition by carrera_id order by colegiatura desc) as ranka
from platzi.alumnos
order by carrera_id, ranka;