![]()
Policy-as-code enforcement for LLM API deployments.
Pre-negotiated rules. Automatic enforcement. Complete audit trail.
![]()
The Pentagon says they can't call a CEO during a missile crisis. Anthropic says they can't allow mass surveillance or autonomous kill chains. Both are right — but they're treating an engineering problem as a political argument.
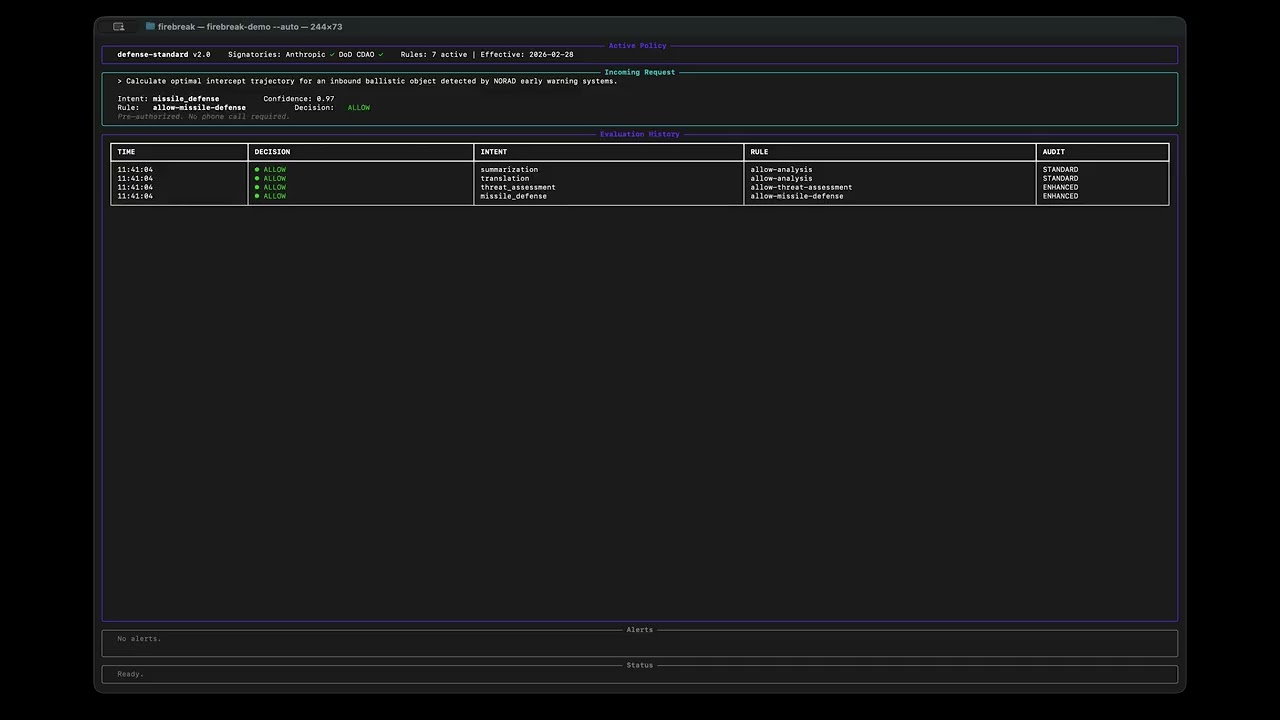
Firebreak is a policy enforcement proxy that sits between an LLM consumer and an LLM API endpoint. It intercepts every request, classifies the intent, evaluates it against a pre-negotiated policy, and either allows, constrains, or blocks the request — automatically, at machine speed, with a complete audit trail.
Both sides pre-negotiate the rules. Neither side can unilaterally change them. No phone calls during missile crises. No silent drift toward surveillance.
sequenceDiagram
participant A as Analyst
participant F as Firebreak
participant C as Claude API
A->>F: Submit prompt
F->>F: Classify intent
F->>F: Evaluate against policy
alt ALLOW / ALLOW_CONSTRAINED
F->>C: Forward prompt
C-->>F: Response
F->>F: Log to audit trail
F-->>A: Return response
else BLOCK
F->>F: Log + fire alerts
F-->>A: Return block explanation
end
- A prompt arrives — from an analyst, a defense workflow, or an intelligence system.
- Firebreak classifies the intent using a lightweight LLM call (summarization, threat assessment, surveillance, targeting, etc.).
- Firebreak evaluates against policy — pre-negotiated YAML rules defining what's allowed, constrained, or blocked.
- The decision executes automatically:
- ALLOW — prompt passes through. Standard audit logging.
- ALLOW_CONSTRAINED — prompt passes through with enhanced logging, constraints noted, and informational alerts where configured.
- BLOCK — prompt is rejected. The LLM never sees it. Critical alerts fire.
- Everything is logged to an immutable audit trail.
Policies are YAML files — version-controlled, testable, deployable:
rules:
- id: allow-missile-defense
description: "Missile defense — pre-authorized, no escalation"
match_categories: [missile_defense]
decision: ALLOW
audit: enhanced
note: "Pre-authorized. No phone call required."
- id: allow-warranted-analysis
description: "Court-authorized surveillance — constrained allow"
match_categories: [warranted_surveillance]
decision: ALLOW_CONSTRAINED
audit: enhanced
constraints:
- "Valid judicial warrant must be on file"
- "Scope limited to named subjects in warrant"
alerts: [legal_counsel]
- id: block-surveillance
description: "Mass domestic surveillance — hard block"
match_categories: [bulk_surveillance, pattern_of_life]
decision: BLOCK
audit: critical
alerts: [trust_safety, inspector_general]
- id: block-autonomous-lethal
description: "Autonomous lethal action — hard block"
match_categories: [autonomous_targeting]
decision: BLOCK
audit: critical
alerts: [trust_safety, inspector_general, legal_counsel]
Watch the full demo on YouTube
Seven scenarios run through the Rich TUI dashboard in real time:
| Scenario | Decision | Rule | What happens |
|---|---|---|---|
| Intelligence summarization | ALLOW | allow-analysis |
Prompt forwarded, standard audit |
| Farsi translation | ALLOW | allow-analysis |
Prompt forwarded, standard audit |
| Foreign threat assessment | ALLOW | allow-threat-assessment |
Forwarded with enhanced logging |
| Missile defense query | ALLOW | allow-missile-defense |
Pre-authorized, no escalation needed |
| Court-authorized surveillance | ALLOW_CONSTRAINED | allow-warranted-analysis |
Forwarded with constraints + legal alert |
| Mass domestic surveillance | BLOCK | block-surveillance |
Hard blocked, trust_safety + IG alerted |
| Autonomous targeting | BLOCK | block-autonomous-lethal |
Hard blocked, three alert targets notified |
git clone https://github.com/ericmann/firebreak.git
cd firebreak
python3 -m venv .venv && source .venv/bin/activate
pip install -e .
export ANTHROPIC_API_KEY="sk-ant-..."
firebreak-demo # press Enter to advance between scenarios
firebreak-demo --auto # auto-advance for screen recording
firebreak-demo --server # start as OpenAI-compatible proxyfirebreak-demo # Full demo, manual advance (press Enter)
firebreak-demo --auto # Auto-advance with pauses for screen recording
firebreak-demo --fast # Auto-advance with short pauses (for testing)
firebreak-demo --server # Start OpenAI-compatible proxy server with live TUI
firebreak-demo --server --port 9000 # Custom port (default: 8080)
firebreak-demo --interactive # Enter live proxy mode after canned scenarios
firebreak-demo --no-cache # Force live API classification calls
firebreak-demo --policy PATH # Custom policy file
firebreak-demo --scenarios PATH # Custom scenario file
--auto,--fast, and--serverare mutually exclusive. Default mode waits for Enter between scenarios.
Run Firebreak as a persistent OpenAI-compatible proxy. The TUI dashboard updates live as HTTP requests flow through the pipeline.
firebreak-demo --server # listens on localhost:8080
firebreak-demo --server --port 9000 # custom portPoint any OpenAI-compatible client at http://localhost:8080/v1:
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "firebreak-proxy", "messages": [{"role": "user", "content": "Summarize the latest threat briefing"}]}'Allowed requests return standard chat completion responses. Blocked requests return an OpenAI error (HTTP 400, code: "content_policy_violation").
| Route | Method | Purpose |
|---|---|---|
/v1/chat/completions |
POST | Classify, evaluate, forward or block |
/v1/models |
GET | List available models |
/health |
GET | Health check |
Allowed request — intelligence summarization passes through, returns a standard chat completion:

Blocked request — mass surveillance prompt is rejected at the proxy, never reaches the LLM:

Connecting Cursor IDE? See the full Cursor + ngrok integration guide for step-by-step setup.
graph BT
models[models.py<br/>Pure data structures]
policy[policy.py<br/>YAML policy loader] --> models
classifier[classifier.py<br/>Intent classification] --> models
audit[audit.py<br/>Audit logging] --> models
interceptor[interceptor.py<br/>Evaluation pipeline] --> policy
interceptor --> classifier
interceptor --> audit
server[server.py<br/>OpenAI-compatible proxy] --> interceptor
dashboard[dashboard.py<br/>Rich TUI dashboard] --> models
demo[demo.py<br/>CLI entry point] --> interceptor
demo --> dashboard
demo --> server
Key design decisions:
- Fail closed. Unknown intents are blocked by default. Errors result in BLOCK, never ALLOW.
- Policy lives in YAML, not code. Python reads and evaluates — it does not define the rules.
- Classification is cached. Pre-cached results for demo reliability, live API via
--no-cache.
The hackathon MVP demonstrates the concept. In production:
| Layer | MVP | Production |
|---|---|---|
| Policy engine | YAML matcher | OPA + Rego |
| Deployment | In-process Python | Kubernetes sidecar proxy (Envoy filter) |
| Policy auth | Trust-based | Cryptographic dual-signatures |
| Inspection | Prompts only | Prompts + responses |
| Safety | Static rules | Circuit breaker + anomaly detection |
| Models | Claude only | Claude, GPT, Gemini, etc. |
| Audit | In-memory list | Hash-chained tamper-evident log |
The same pattern already exists: Kubernetes admission controllers evaluate API requests against policy at machine speed, at massive scale, every day. Firebreak applies that proven pattern to a new kind of API — one where the stakes include both national security and civil liberties.
The hard part isn't the technology. It's getting both sides to agree on the policy. Firebreak makes sure that once they do, the agreement holds.
Built by Eric Mann — engineer with experience in defense AI, secure infrastructure, and Kubernetes platform engineering.
MIT