This is a kaggle competetion hosted by Jigsaw and google to identify toxic comments in online conversations. This is a addition to the previous Toxic Comment Classification Challenge which is to be more unbiased and diverse.
-
Data Cleaning:
-
For the training “comment_text” and “target” features were relevant. So, other columns are dropped.
-
For the training “comment_text” and “target” features were relevant. So, other columns are dropped.
-
-
Tokenizing and Embedding:
- The training and testing data is tokenized and padded to have same length.
- FastText and QuoraText embedding are combined, and fitted on tokenized dataset to create the embedding of the words.
-
Splitting the dataset:
- The tokenized input variable and target variable is splitted for training and testing.
-
Model Building:
- The model is built using Embedding layer, Bidirectional LSTM layer and Dense layer.
-
Model training:
- The model is trained for 20 epoch with batch size of 248.
- Early stopping and Reduce Learning rate is used to stop overfitting.
- Model Checkpoint is used to save the best model.
- The training accuracy is: 0.9638 and loss is 0.0955
- The validation accuracy is: 0.96380 and loss is 0.095541
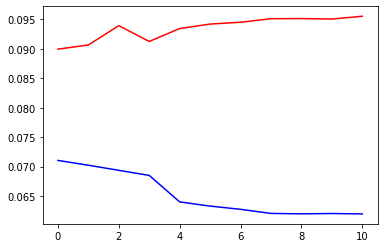
- The model seems converged well on the first epoch, the started overfitting. Reducing learning rate haven’t helped much.
Accuracy Plot:

Loss Plot:
- numpy
- pandas
- sklearn
- tensorflow
- matplotlib
- gensim
- tqdm
- operator
- gc