An 8-stage vulnerability-discovery agent, driven by your Claude Pro / Max subscription through the official Claude Code Agent SDK. Many narrow agents, deliberate disagreement, and an explicit reachability gate.
MIT-licensed. No API key needed if you already use claude login.
This project is a from-scratch reimplementation of the pipeline described in Cloudflare's Project Glasswing post, which tested Anthropic's Mythos preview LLM against Cloudflare's own codebase. The blog argues that real-world vulnerability discovery does not come from asking one big model "find bugs here" — it comes from:
- Many narrow agents working in parallel on tightly-scoped questions ("Look for command injection in this specific function, with this trust boundary above it") rather than one exhaustive agent.
- Deliberate disagreement — a second agent, on a different model, that tries to disprove the first agent's findings.
- A reachability trace as the gating step — most "is this code buggy?" findings are noise unless an attacker-controlled input can actually reach the sink from outside the system.
- A feedback loop so reachable bugs in one place automatically seed hunts for the same pattern elsewhere.
This repo packages that pipeline into a runnable agent. The Cloudflare post showed the architecture; this codebase ships the prompts, schemas, state store, and orchestrator.
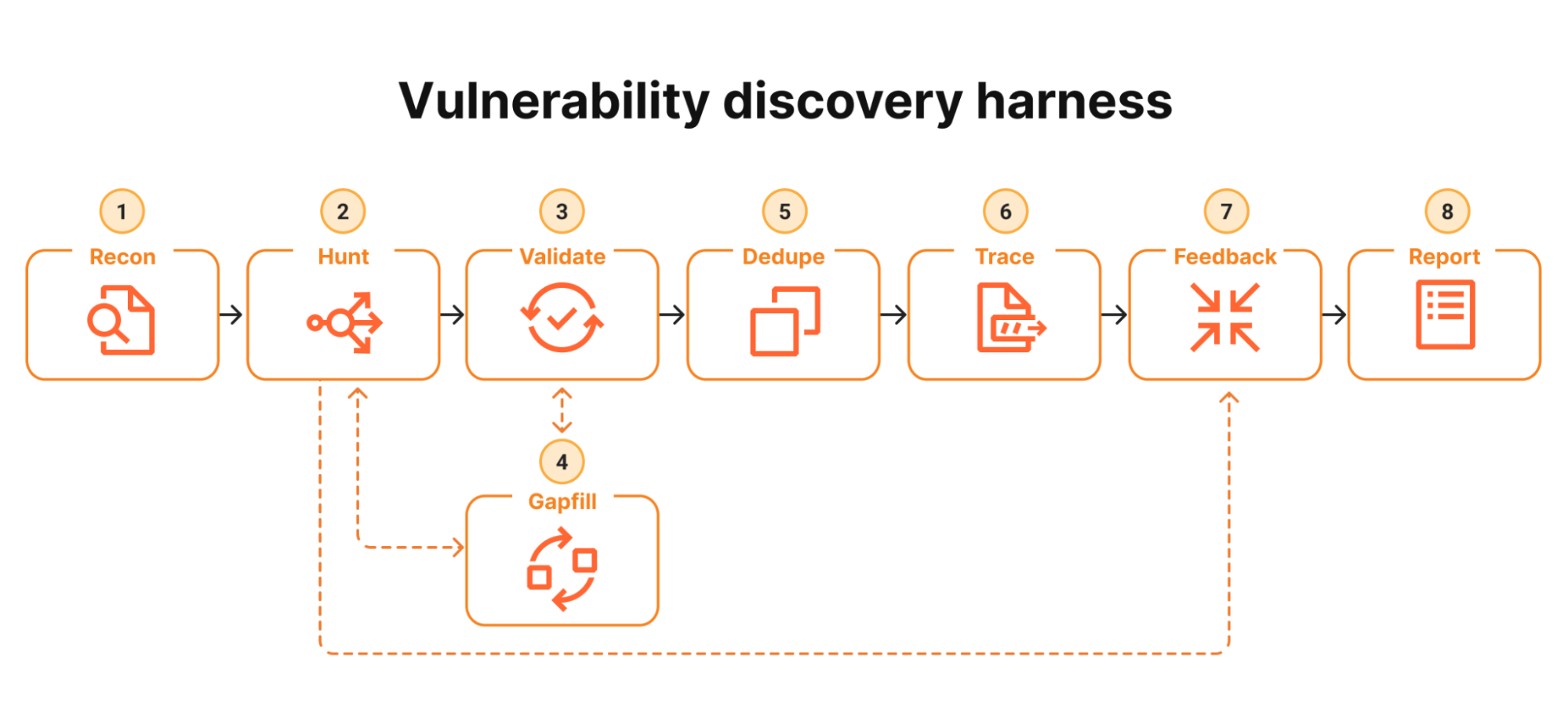
Diagram from Cloudflare's Project Glasswing post, reproduced here for reference.
| # | Stage | Default model | Purpose |
|---|---|---|---|
| 1 | Recon | Opus 4.7 | Map the repo, emit narrowly-scoped Hunt tasks |
| 2 | Hunt | Sonnet 4.6 | One attack class per agent; compile/run PoCs |
| 3 | Validate | Opus 4.7 | Adversarial re-read; tries to disprove (different model from Hunt) |
| 4 | Gapfill | Sonnet 4.6 | Re-queue under-covered areas |
| 5 | Dedupe | Sonnet 4.6 | Cluster findings by root cause |
| 6 | Trace | Opus 4.7 | Prove attacker-controlled input reaches the sink |
| 7 | Feedback | Sonnet 4.6 | Turn reachable traces into new Hunt tasks |
| 8 | Report | Sonnet 4.6 | Schema-validated structured report |
Each stage is one markdown prompt in prompts/ + one JSON Schema in
schemas/. The orchestrator passes the schema into the system prompt so
every output is shape-stable on the first try.
# 1. Install
python -m venv .venv && source .venv/bin/activate
pip install -e .
# 2. Auth (pick one)
# (a) Already logged in via claude login? You're done.
# (b) Or generate a 1-year OAuth token for CI / non-interactive use:
claude setup-token
echo "CLAUDE_CODE_OAUTH_TOKEN=<paste>" > .env
# 3. Verify
audit auth-check
# 4. Run
audit run --repo /path/to/target --run-id my-run
audit status --run-id my-run
audit report --run-id my-run --format md > report.mdThe agent uses subscription billing via your Claude.ai login — it does
not call the metered API. The on-disk auth module scrubs
ANTHROPIC_API_KEY from the environment so it can't silently route around
the OAuth flow.
A real production codebase can produce 15-50 Hunt tasks and 25+ findings to validate. At default concurrency this gets expensive. Flags to keep it sane:
audit run --repo /path/to/target \
--max-concurrency 1 \ # one claude subprocess at a time
--max-recon-tasks 15 \ # cap initial Hunt fanout
--max-cost-usd 30 # abort cleanly if exceededThe budget guard fires between and within stages — a per-task check in Hunt cooperatively aborts rather than running 30 more tasks past the cap.
prompts/ 8 stage prompts (markdown, loaded as system prompts)
schemas/ 9 JSON schemas — every agent output is validated
config/ stages.yaml — model + concurrency + tool allowlist per stage
audit/ Python package
auth.py OAuth check + ANTHROPIC_API_KEY scrubbing
state.py SQLite DAO (runs, tasks, findings, traces, dedupe, costs)
runner.py claude-agent-sdk wrapper with schema validation + repair turn
orchestrator.py pipeline driver
stages/ one module per stage
work/ per-Hunt-task scratch dirs (sandbox for PoC compile/run)
results/ JSONL artifacts per stage + final report.json
state.db SQLite (gitignored)
Hunt agents have Bash and run inside per-task scratch dirs. They are not sandboxed at the OS level. Run the audit inside a disposable VM or container when you don't trust the target source — a target with malicious build scripts could otherwise execute on your host during PoC compilation.
The agent reads everything you --add-dir, including any .env or
secrets/ directories in the target. Outputs land in results/<run-id>/
which is .gitignored but not scrubbed of those reads.
MIT. Reuse freely. No warranty.
- The pipeline design is from Cloudflare's Project Glasswing blog post. The credit for the architecture goes there.
- Built on the official Claude Code Agent SDK.