fix: uninstall-exo.sh removes both current and legacy bridge scripts#1998
Merged
Evanev7 merged 1 commit intoApr 28, 2026
Merged
Conversation
The standalone uninstaller only knew about the legacy filename (disable_bridge_enable_dhcp.sh), so on machines installed with newer versions it left the current /Library/Application Support/EXO/disable_bridge.sh in place and reported "EXO support directory not empty, leaving in place". Try both filenames, tolerate either/both/neither being present. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
36a3696 to
9c1d48f
Compare
team-wcv
added a commit
to team-wcv/exo
that referenced
this pull request
May 7, 2026
* fix: map presence_penalty and frequency_penalty from ChatCompletionRequest (exo-explore#1991) Upstream PR exo-explore#1947 added `presence_penalty` and `frequency_penalty` to `TextGenerationTaskParams` and the mlx-lm generator call sites, but missed wiring them up in the API adapter so they were silently dropped from incoming requests. This fixes the API mapping. Co-authored-by: Adam Durham <adam@example.com> * Add DeepSeek V4 Flash/Pro (exo-explore#1978) Wait for upstream merge. --------- Co-authored-by: Evan <evanev7@gmail.com> * Extend bench/eval tooling (exo-explore#1905) ## Motivation Extend bench/eval tooling with robustness features, streaming support, and align model configs with vllm eval for reproducible comparisons. ## Changes - **exo_eval**: Checkpoint/resume (JSONL), instance health monitoring + early abort, `top_k`/`min_p`/`enable_thinking` params, LCB `--release-version`/`--offset` - **exo_bench**: Streaming SSE (`--stream`), Kimi tokenizer fix for transformers 5.x - **Both tools**: Auto-detect running instances instead of requiring `--skip-instance-setup`; `--fresh-instance` to override - **harness**: SSE streaming client, `find_existing_instance()` shared helper, removed download timeout, settle-timeout default 0→7200s - **models.toml**: Added `enable_thinking`, aligned `max_tokens`/temps with vllm, added new models - **API**: Streaming SSE for `/bench/chat/completions` ## Why It Works - Checkpoint/resume uses append-only JSONL + skip-on-load so interrupted evals resume without re-running completed questions - Health monitoring races an `asyncio.Event` against API calls for fast abort when the instance dies - Auto-detection queries `/state` for existing instances matching the model ID before attempting placement - Streaming reuses the existing `generate_chat_stream` infrastructure from the regular chat endpoint * fix: route by in-flight tasks only — completed tasks were skewing load balance (exo-explore#1989) The load balancer counted ALL tasks (Complete, Cancelled, TimedOut, Failed) instead of only Pending/Running ones. With 138 accumulated tasks and only 7 active, routing decisions were based on historical distribution, causing one node to appear permanently 'busier' and starving the other of work. Co-authored-by: Adam Durham <adam@example.com> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com> * MLX P/D (exo-explore#1993) ## Motivation MLX only prefill server for Apple Silicon * fix: uninstall-exo.sh removes both current and legacy bridge scripts (exo-explore#1998) ## Summary The standalone `app/EXO/uninstall-exo.sh` only knew about the legacy filename `disable_bridge_enable_dhcp.sh`. On machines installed with newer EXO versions, the current `/Library/Application Support/EXO/disable_bridge.sh` was left behind, and the script then reported `EXO support directory not empty, leaving in place`. This PR makes the script try both filenames, removing whichever ones exist. Tolerates **either**, **both**, or **neither** being present without erroring. The Swift `NetworkSetupHelper.makeUninstallScript()` already handles both paths correctly, so the GUI uninstall flow is unaffected — this is a script-only fix. Caught while running an end-to-end uninstall on a real machine for exo-explore#1997. ## Test plan Verified the new block in isolation against all four states: - [x] both `disable_bridge.sh` and `disable_bridge_enable_dhcp.sh` present → both removed - [x] only `disable_bridge.sh` present → removed cleanly - [x] only `disable_bridge_enable_dhcp.sh` present → removed cleanly (legacy install) - [x] neither present → prints the existing "already removed?" warning, exits 0 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * implement engine abstraction for mlx and mflux (exo-explore#2000) refactor for future versions. * feat: keep-models option when uninstalling EXO (exo-explore#1997) ## Summary - Adds a **Keep downloaded models (~/.exo/models)** checkbox to the macOS uninstall confirmation dialog (Settings → Advanced → Danger Zone). The full `~/.exo` directory is now removed on uninstall by default; if the checkbox is checked, `~/.exo/models` is preserved. - The standalone `app/EXO/uninstall-exo.sh` gains a matching `--keep-models` flag and the same `~/.exo` cleanup so GUI and CLI flows stay in sync. Resolves the user home via `$SUDO_USER` since the script runs under `sudo`. Previously, "Uninstall EXO" only cleaned up system-level components (LaunchDaemon, network location, logs, app bundle) and left the entire `~/.exo` directory behind. Now uninstalling actually removes EXO's user data, with a one-click opt-out for the (potentially many GB) of downloaded models. 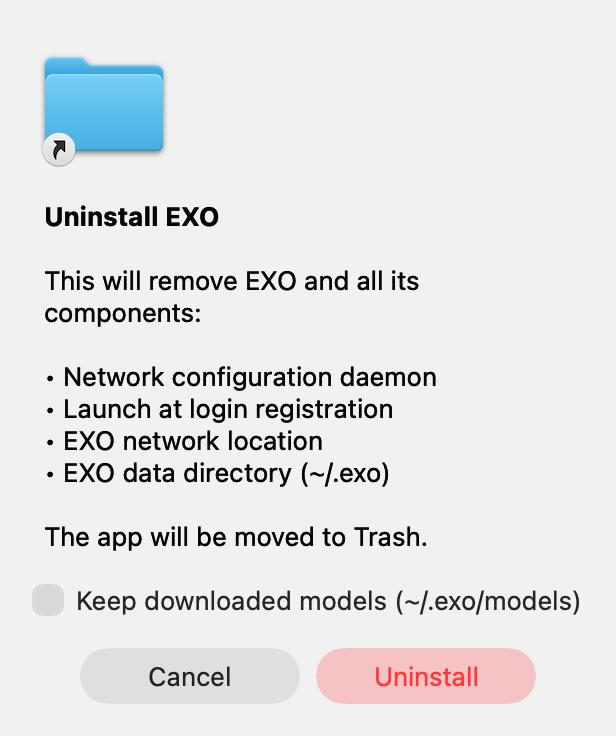 > Note: the rendered icon in the screenshot above is the generic system folder icon because it was captured from a small standalone Swift binary (no app bundle / icon resource). When triggered from the actual EXO.app, the EXO app icon is shown. ## Test plan - [ ] Build EXO.app locally; open Settings → Advanced → Danger Zone → Uninstall EXO; confirm the new "Keep downloaded models (~/.exo/models)" checkbox is present and unchecked by default. - [ ] Uninstall with the checkbox **checked** → `~/.exo/models/` survives, all other entries under `~/.exo` are gone, system components removed, app moved to Trash. - [ ] Uninstall with the checkbox **unchecked** → `~/.exo` is fully removed. - [ ] `sudo app/EXO/uninstall-exo.sh --keep-models` → `~/.exo/models/` is preserved, the rest of `~/.exo` is removed. - [ ] `sudo app/EXO/uninstall-exo.sh` (no flag) → `~/.exo` is fully removed. - [ ] `app/EXO/uninstall-exo.sh --help` prints usage and exits 0; unknown args exit 2 with a usage hint. 🤖 Generated with [Claude Code](https://claude.com/claude-code) --------- Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com> Co-authored-by: Evan <evanev7@gmail.com> * feat(app): open Share Bug Report in a dedicated window (exo-explore#2003) ## Summary - Adds a top-level **Share Bug Report…** menu item to the macOS popover (between *Check for Updates* and *Quit*) with SF Symbol `ladybug`. - Clicking it opens a dedicated resizable `NSWindow` ("Send a Bug Report") that hosts the prompting / sending / success / failure flow. - Removes the description-less duplicate from Settings → Debug Info, and the dead `debugSection` it nominally lived behind. ## Why PR exo-explore#1959 added a user-description prompt to the bug-report flow, but its trigger lived inside `ContentView.debugSection` — a view that's defined but never rendered in the body. The path users actually hit was `SettingsView.sendBugReportButton`, which called `BugReportService.sendReport(isManual: true)` without ever passing `userDescription`. So the description prompt was unreachable in the built app. ## Approach Per Apple HIG, an action that requires further input before completing should open a dialog, not transform the menu inline. So: - Add a top-level menu entry that ends in `…` (HIG: ellipsis indicates "further input required"). - Move the prompting/sending/success/failure state machine into a standalone `BugReportWindowController` modeled after the existing `SettingsWindowController`. - Single-instance window with frame-autosave name, sensible `contentMinSize`, resizable, native button layout (`.cancelAction` / `.defaultAction` keyboard shortcuts), light/dark-mode-correct `.textBackgroundColor` and `.separatorColor`. - Auto-focus the description field on open. `Try Again` from failure, `Open GitHub Issue` + `Done` from success. ## Files - `app/EXO/EXO/Views/BugReportWindowController.swift` (new) — controller + view. - `app/EXO/EXO/EXOApp.swift` — wire `BugReportWindowController` as a `@StateObject` and inject as environment object. - `app/EXO/EXO/ContentView.swift` — replace inline state machine with menu item that calls `bugReportWindowController.open()`. Remove now-unused state, helpers, and dead `debugSection`. - `app/EXO/EXO/Views/SettingsView.swift` — remove duplicate `sendBugReportButton`, `sendBugReport()`, and related `@State`. Section "Debug Info" keeps Thunderbolt / interface / RDMA info. `BugReportService` is unchanged. ## Test plan - [ ] Open the menu-bar popover → confirm **Share Bug Report…** appears between *Check for Updates* and *Quit*, with a ladybug icon. - [ ] Click it → a window titled "Send a Bug Report" appears, centered, with the description editor focused. - [ ] Resize the window → size persists across re-opens (frame autosave). - [ ] Type a description, press Return → upload succeeds, success card with **Open GitHub Issue** + **Done** appears. - [ ] Click **Open GitHub Issue** → browser opens with the description pre-filled into the issue template. - [ ] Send with empty description → upload still succeeds. - [ ] Press Esc from the prompting state → window closes. - [ ] On failure (e.g., offline) → error card with **Try Again** + **Close** appears; Try Again returns to the editor with the description preserved. - [ ] Open the Settings window → Debug Info section is unchanged except the Send Bug Report button is gone. 🤖 Generated with [Claude Code](https://claude.com/claude-code) --------- Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * fix(app): tighten Share Bug Report prompt layout (exo-explore#2008) ## Summary Follow-ups to exo-explore#2003 based on feedback that the Share Bug Report window felt visually weighty: too much padding above and below, and a description editor that invited an essay rather than a one-liner. ## Changes (one file) `app/EXO/EXO/Views/BugReportWindowController.swift`: - **Auto-size the window to its content.** Switched from `NSHostingView` + fixed `contentRect: 480x380` + SwiftUI `frame(minHeight: 320)` to `NSHostingController` with `sizingOptions = [.preferredContentSize, .minSize]`. The fixed-min combo was centering the form in dead vertical space. - **Smaller, lower-pressure editor.** Field is now labeled `Description (optional)` with a placeholder hint (`What were you doing when it broke?`) inside the editor. Editor height fixed at 72pt (was 120pt min). Replaced the long lead-in paragraph and headline with a single one-line caption between field and buttons: `Diagnostic logs will be uploaded with your report.` - **Tighter spacing.** Outer padding 20 -> 16, root spacing 16 -> 12, prompting-section spacing 12 -> 8. - **Remove em dash from copy.** `BugReportService` and the menu wiring are unchanged. ## Test plan - [ ] Click `Share Bug Report...` from the menu bar. - [ ] The window opens centered and sized to its content (no big empty bands top/bottom). - [ ] Description editor is visibly compact, with the placeholder hint showing when empty. - [ ] The optional-ness is conveyed by the field label (no separate help paragraph). - [ ] Caption `Diagnostic logs will be uploaded with your report.` appears in `.caption` style under the editor, above the buttons. - [ ] Resize the window: persists across re-opens (frame autosave still works). - [ ] Send/Cancel/Try Again/Done flows behave the same as before. 🤖 Generated with [Claude Code](https://claude.com/claude-code) --------- Co-authored-by: Claude Opus 4.7 (1M context) <noreply@anthropic.com> * A few targeted tweaks to address HF rate limits (exo-explore#2009) ## Motivation - exo bursts ~200 HF Hub-API requests on every cold start, blowing past the anonymous 500-req/5-min budget. - The existing retry loop catches 429 generically and gives up in ~3s — well before HF's reset window. - `file_meta` and `_download_file` had no 429 handling at all (became `AssertionError`). - Disk file-list cache was bypassed on every process restart. ## Changes All in `src/exo/download/download_utils.py` + tests. - Parse `t=` from HF's `RateLimit` header on 429; sleep `min(t, 300s) + jitter`. - Handle 429 at all three call sites (`_fetch_file_list`, `file_meta`, `_download_file`). - `n_attempts`: 3 → 5. - Disk cache now primary across restarts (24h mtime TTL). - `?recursive=true` instead of N+1 subdir walks. ## Why It Works `t=<seconds>` is HF's "wait this long and you'll be unblocked" — sleeping that long lets the window reset. Disk-cache-as-primary plus recursive listing cuts cold-start Hub-API traffic by ~10×. ## Test Plan ### Manual Testing MacBook Pro M1 Max. Tripped the real HF 429. Pre-fix: failed in 3.4s. Post-fix: slept (HF returned `t=158`) and recovered. ### Automated Testing - New `test_rate_limit_handling.py` (19 tests) — header parsing, retry-loop behaviour, plus HTTP-level coverage that mocks aiohttp to return a 429 and asserts each call site raises `HuggingFaceRateLimitError(retry_after=52.0)`. - New `TestFileListCacheTTL` in `test_offline_mode.py` — fresh cache hits, stale cache refetches. - 421 tests pass; basedpyright / ruff / nix fmt clean. * fix(macos-app): disable URL response caching for cluster-state polling (exo-explore#2005) Fixes exo-explore#2004. `ClusterStateService` polls `/state` at 2 Hz via `URLSession.shared`, which keeps an on-disk `URLCache` attached by default. Every polled response body gets persisted under `~/Library/Caches/exolabs.EXO/`, sustaining ~500–620 KB/sec of file-backed memory dirtied — far above macOS's ~25 KB/sec per-process daily-average baseline. Six microstackshot reports observed on a single Mac Studio M3 Ultra over eight days, with one 15-hour run accumulating 34.36 GB of cache writes. Heaviest stack on every diagnostic report (96–98% of samples): ``` _dispatch_workloop_worker_thread → _dispatch_block_async_invoke2 → __CFURLCache::CreateAndStoreCacheNode → write ``` Full diagnostic data and analysis in exo-explore#2004. ## What changed `ClusterStateService` now defaults to an ephemeral, non-caching `URLSession` instead of `URLSession.shared`. Cluster-state responses are time-sensitive and small; nothing benefits from being cached on disk. ```swift private static func makeNonCachingSession() -> URLSession { let config = URLSessionConfiguration.ephemeral config.urlCache = nil config.requestCachePolicy = .reloadIgnoringLocalCacheData return URLSession(configuration: config) } ``` The existing per-request `request.cachePolicy = .reloadIgnoringLocalCacheData` calls are kept as defense in depth — they only affect read behavior, but harmless to leave alongside the session-level config. ## Scope - **Behavioral**: none. Polled requests still go out at the same cadence; responses still parse the same; no semantic change to any API surface. - **Test injection**: the `session:` parameter remains in `init`, so tests can still inject a custom mock session unchanged. - **`BugReportService` and other `URLSession.shared` callers**: untouched. If maintainers prefer an app-wide URLCache disable instead, happy to switch the approach (issue body has the alternative spelled out). ## Verification Verified locally that compiling EXO with this change produces a working menubar app and `ClusterStateService` continues to fetch state correctly. After ~30 min of idle polling, no new entries in `/Library/Logs/DiagnosticReports/EXO_*.diag` and no growth in `~/Library/Caches/exolabs.EXO/`. ## Test plan - [ ] Build EXO from this branch on macOS 26.4 - [ ] Launch, let cluster state polling run for 30+ min - [ ] Confirm no new microstackshot diagnostic reports - [ ] Confirm `~/Library/Caches/exolabs.EXO/Cache.db*` does not grow 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-authored-by: Jordan Miller <jordan.d.miller@gmail.com> * feat: update rdma_ctl instructions (exo-explore#1977) ## Motivation The RDMA setup instructions were missing a step: after booting to Recovery mode, users need to open Terminal from the Utilities menu before they can run the `rdma_ctl` command. Without this step, users following the instructions wouldn't know how to access a terminal in Recovery mode. This step was already in the README just not in the UI notifications. ## Changes Added a missing instruction step — "Open Terminal from the Utilities menu" — to three instances of the RDMA setup flow in `dashboard/src/routes/+page.svelte`. ## Why It Works N/A copy change only. ## Test Plan ### Manual Testing Hardware: MacBook Pro M4 Max 48GB ### Automated Testing No automated tests affected; this is a UI copy change only. Co-authored-by: Sam Bradbury <sam@consultbradbury.com> * Initialise _cancelled_tasks in ImageEngine (exo-explore#2051) we yielded nonsense chunks from engines; we didn't initialize the image engine correctly. mostly rewrite of exo-explore#2049 --------- Co-authored-by: ciaranbor <ciaranborourke-dev@proton.me> * fix(inference): prevent TP collective deadlock via agree_on_tasks order (exo-explore#2048) If you have two machines and make two requests at the same time, it can crash. This is because the tasks can sometimes end up in different orders on different machines. We need to sort the tasks and mx_all_gather_tasks already sorts the tasks but the code ignores that ordering. The fix is to make sure the sort order is preserved. The rest is written by Sonnet (reviewed by me): Tensor-parallel inference requires that every rank enqueues tasks in the same order before running agree_on_tasks collectives. The old implementation filtered from _maybe_queue: self._queue.extend(task for task in self._maybe_queue if task in agreed) self._maybe_queue = [task for task in self._maybe_queue if task in different] Because _maybe_queue is independently ordered per-rank (tasks arrive via gRPC in whatever order the API server sends them), two concurrent requests could produce different _maybe_queue orderings on rank 0 vs rank 1. The filter then preserved those different orders into _queue, so each rank started processing tasks in a different sequence. The next mlx collective (all_reduce, all_gather, etc.) on rank 0 corresponded to a different task than on rank 1 → permanent deadlock. Fix: extend from agreed directly. mx_all_gather_tasks returns agreed as a list sorted by task_id on all ranks, so every rank appends the same sequence regardless of local arrival order. Applies to both SequentialGenerator and BatchGenerator. ## Motivation `agree_on_tasks` is called on every rank after accumulating new requests in `_maybe_queue`. Its job is to run an `all_gather` collective so all ranks agree on which tasks to promote to `_queue` before the next inference step. The old implementation re-imposed **local arrival order** when extending `_queue`: ```python self._queue.extend(task for task in self._maybe_queue if task in agreed) ``` `mx_all_gather_tasks` already returns `agreed` sorted by `task_id` — the same deterministic order on every rank. But iterating `self._maybe_queue` instead of `agreed` discarded that sort and substituted the local gRPC arrival order, which differs per rank under concurrent load. Two concurrent requests arriving in `[A, B]` order on rank 0 and `[B, A]` on rank 1 caused the first MLX collective in the next step to hang permanently: each rank was executing a different task's collective and would never match. ## Changes `SequentialGenerator.agree_on_tasks` and `BatchGenerator.agree_on_tasks`: ```python # Before self._queue.extend(task for task in self._maybe_queue if task in agreed) self._maybe_queue = [task for task in self._maybe_queue if task in different] # After self._queue.extend(agreed) # preserves mx_all_gather_tasks sort order self._maybe_queue = list(different) # already in local order; filter was redundant ``` ## Why It Works `mx_all_gather_tasks` (in `utils_mlx.py`) computes the agreed set then sorts by `task_id`: ```python agreed = [local_tasks[tid] for tid in sorted(agreed_ids)] ``` Because `task_id` is a UUID and the sort is lexicographic, every rank produces the same `agreed` list regardless of local arrival order. Using `agreed` directly preserves this guarantee. The `different` list (tasks not yet seen on all ranks) is built by iterating `tasks` in local order, which is already correct. ## Test Plan ### Manual Testing **Hardware:** 2× Mac Studio M3 Ultra 512 GB, Thunderbolt 5 direct bridge, `MlxJaccl` RDMA tensor-parallel (`moonshotai/Kimi-K2.6`, 595 GB INT4, 61 layers). - Sent concurrent streaming requests; confirmed all complete without deadlock. - This hardware configuration (sub-millisecond inter-node latency) is the most likely to trigger the race, as requests from separate HTTP connections can reach rank 0 and rank 1 in opposite order before `agree_on_tasks` runs. ### Automated Testing All existing tests pass: `pytest src -m "not slow" --import-mode=importlib` — 422/422 passed. The existing `test_event_ordering.py` covers the `agree_on_tasks` call path with a mock that returns tasks in consistent order; the race requires real distributed hardware to reproduce deterministically. --------- Co-authored-by: Adam Durham <amdnative@gmail.com> Co-authored-by: Adam Durham <adam@example.com> Co-authored-by: rltakashige <rl.takashige@gmail.com> Co-authored-by: Evan <evanev7@gmail.com> Co-authored-by: ciaranbor <81697641+ciaranbor@users.noreply.github.com> Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com> Co-authored-by: Alex Cheema <41707476+AlexCheema@users.noreply.github.com> Co-authored-by: ecohash-co <team@ecohash.co> Co-authored-by: Jordan Miller <jordan.d.miller@gmail.com> Co-authored-by: Sam Bradbury <31943456+sambradbury@users.noreply.github.com> Co-authored-by: Sam Bradbury <sam@consultbradbury.com> Co-authored-by: ciaranbor <ciaranborourke-dev@proton.me> Co-authored-by: Drifter4242 <davehind@yahoo.co.uk> Co-authored-by: jw-wcv <101585096+jw-wcv@users.noreply.github.com>
{kind=link}
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
2 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Summary
The standalone
app/EXO/uninstall-exo.shonly knew about the legacy filenamedisable_bridge_enable_dhcp.sh. On machines installed with newer EXO versions, the current/Library/Application Support/EXO/disable_bridge.shwas left behind, and the script then reportedEXO support directory not empty, leaving in place.This PR makes the script try both filenames, removing whichever ones exist. Tolerates either, both, or neither being present without erroring.
The Swift
NetworkSetupHelper.makeUninstallScript()already handles both paths correctly, so the GUI uninstall flow is unaffected — this is a script-only fix.Caught while running an end-to-end uninstall on a real machine for #1997.
Test plan
Verified the new block in isolation against all four states:
disable_bridge.shanddisable_bridge_enable_dhcp.shpresent → both removeddisable_bridge.shpresent → removed cleanlydisable_bridge_enable_dhcp.shpresent → removed cleanly (legacy install)🤖 Generated with Claude Code