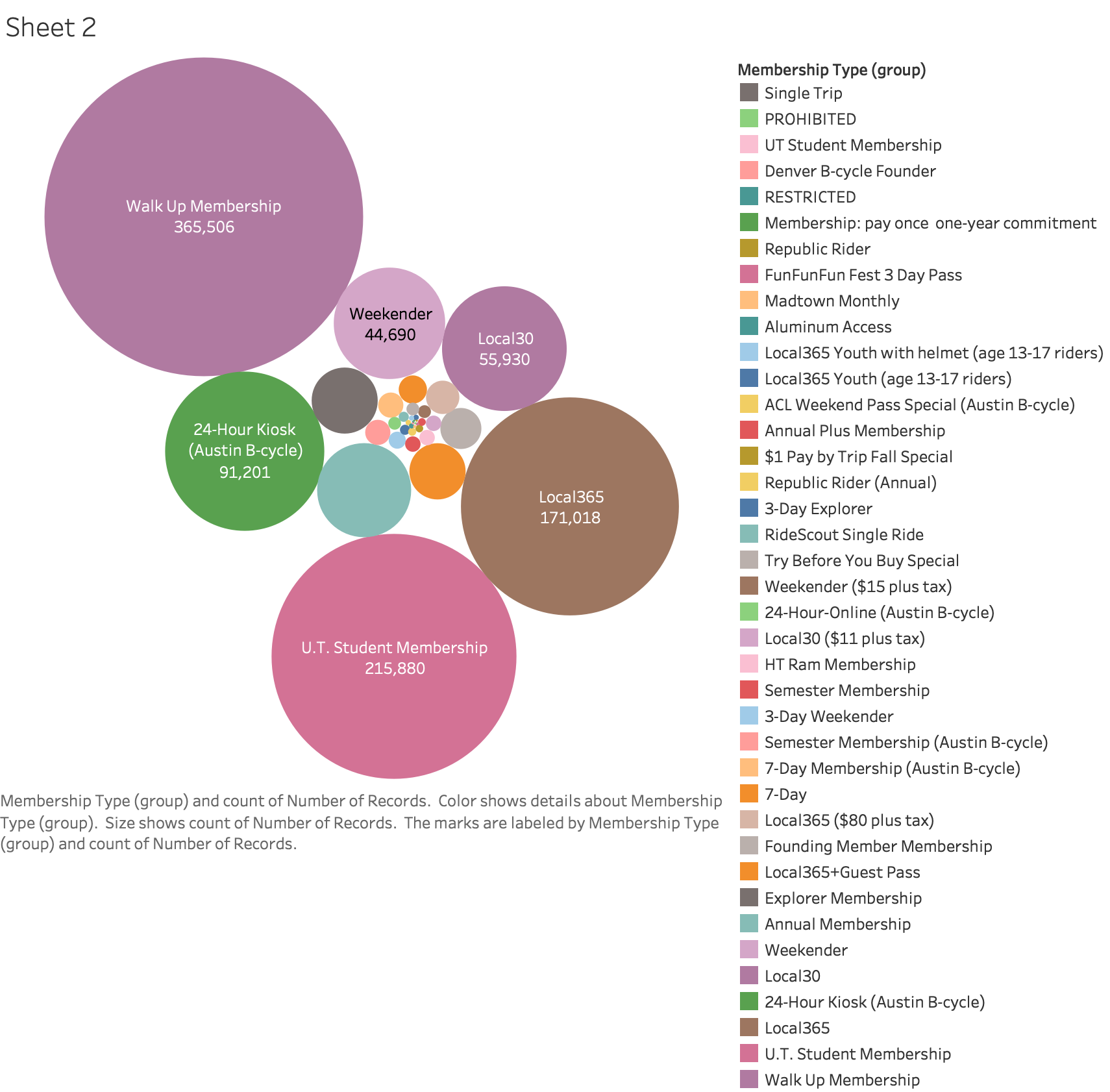
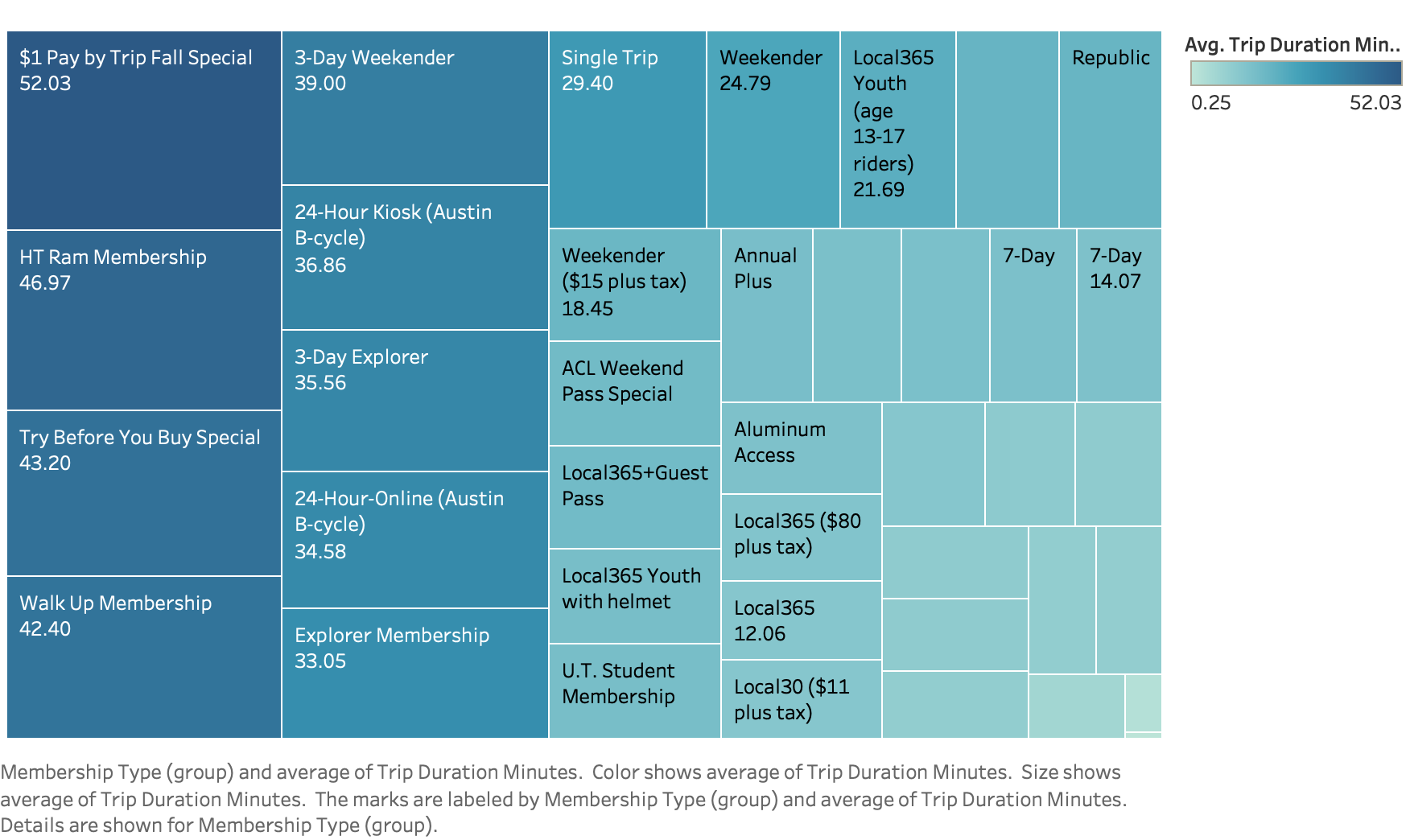
Data Hackthon - Dataset (BCycle.csv & Beijing Geolife.csv)
- Binglin(Mark) Zhang
- Zijian(Steven) Wang
- Fei He
Introducing BCycle into Beijing in 2008.
How would it leverage the efficieny?
Would it improve the air condition?
What kind of memeberships will people purchase?
Beijing Geolife.csv includes the trajectories of participants. Their locations in measure of Longitude and Latitude would be recorded every 3~5 seconds.
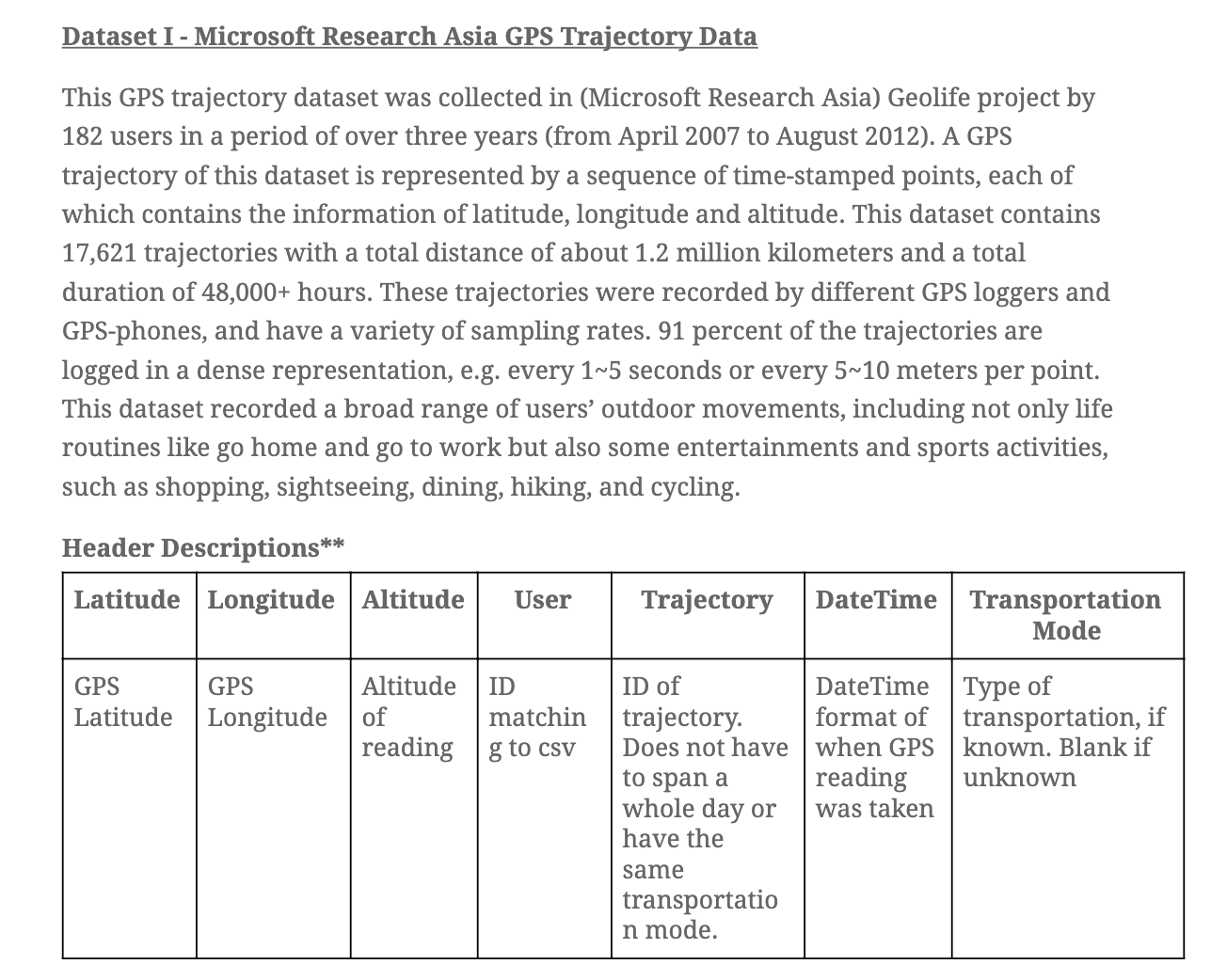
Five random samples from the Geolife dataset
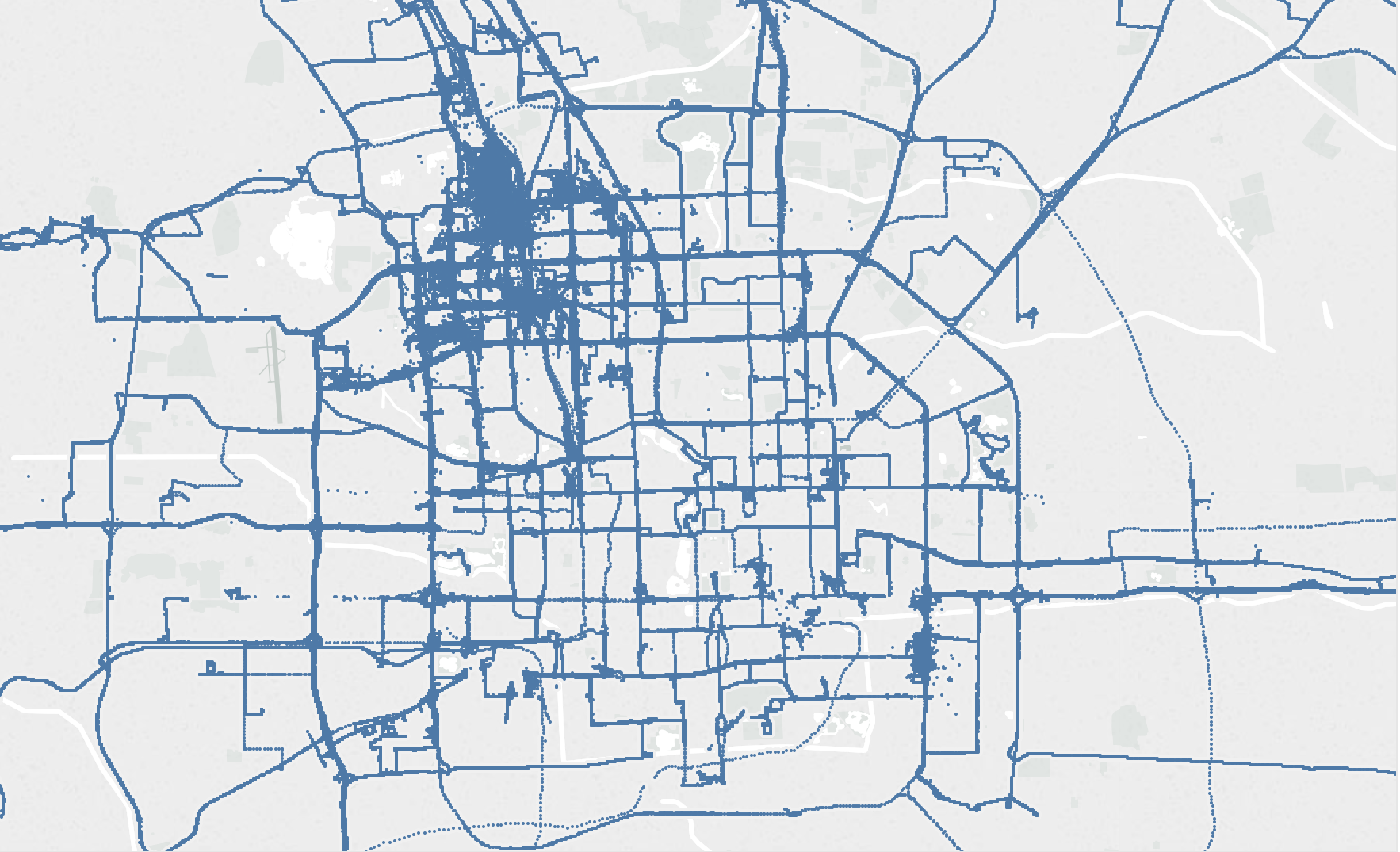 Participants from Beijing were travelling along the roads and might cluster in certain area.
Participants from Beijing were travelling along the roads and might cluster in certain area.
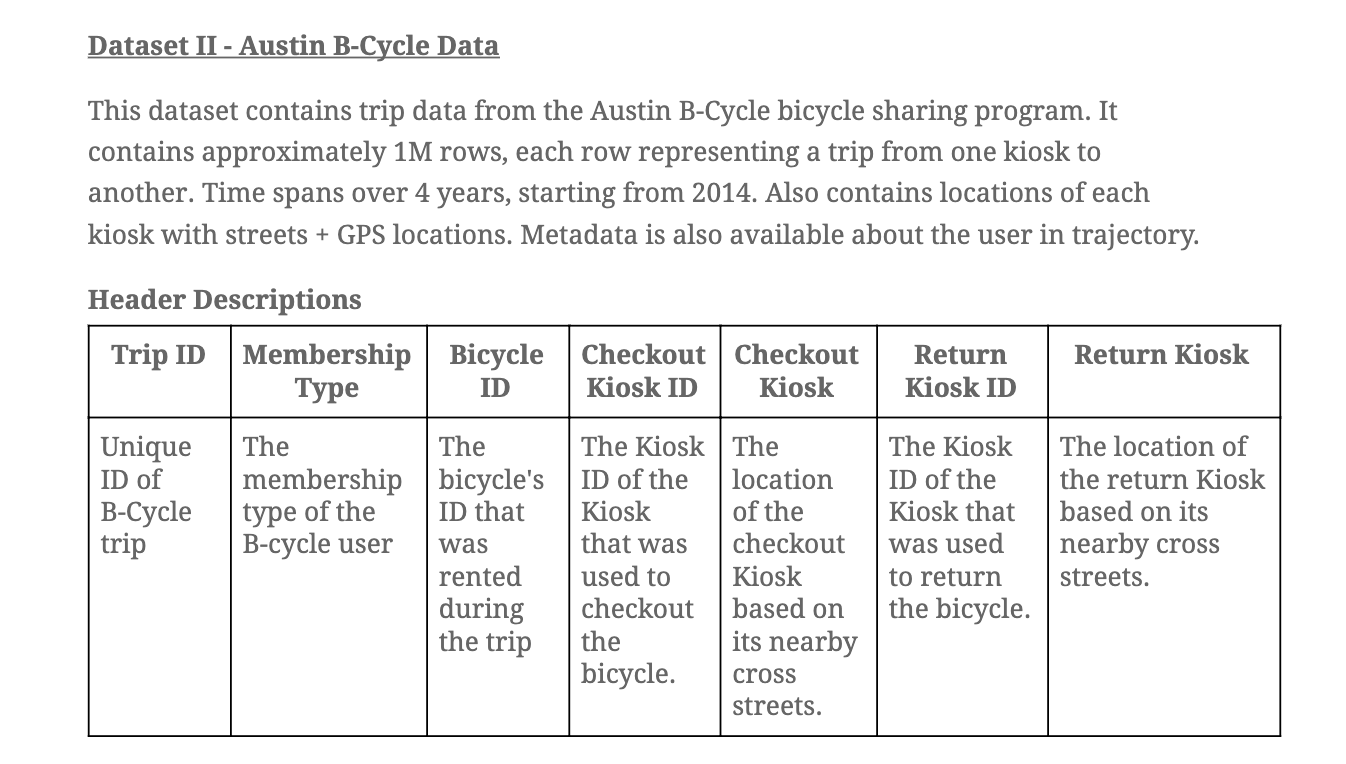
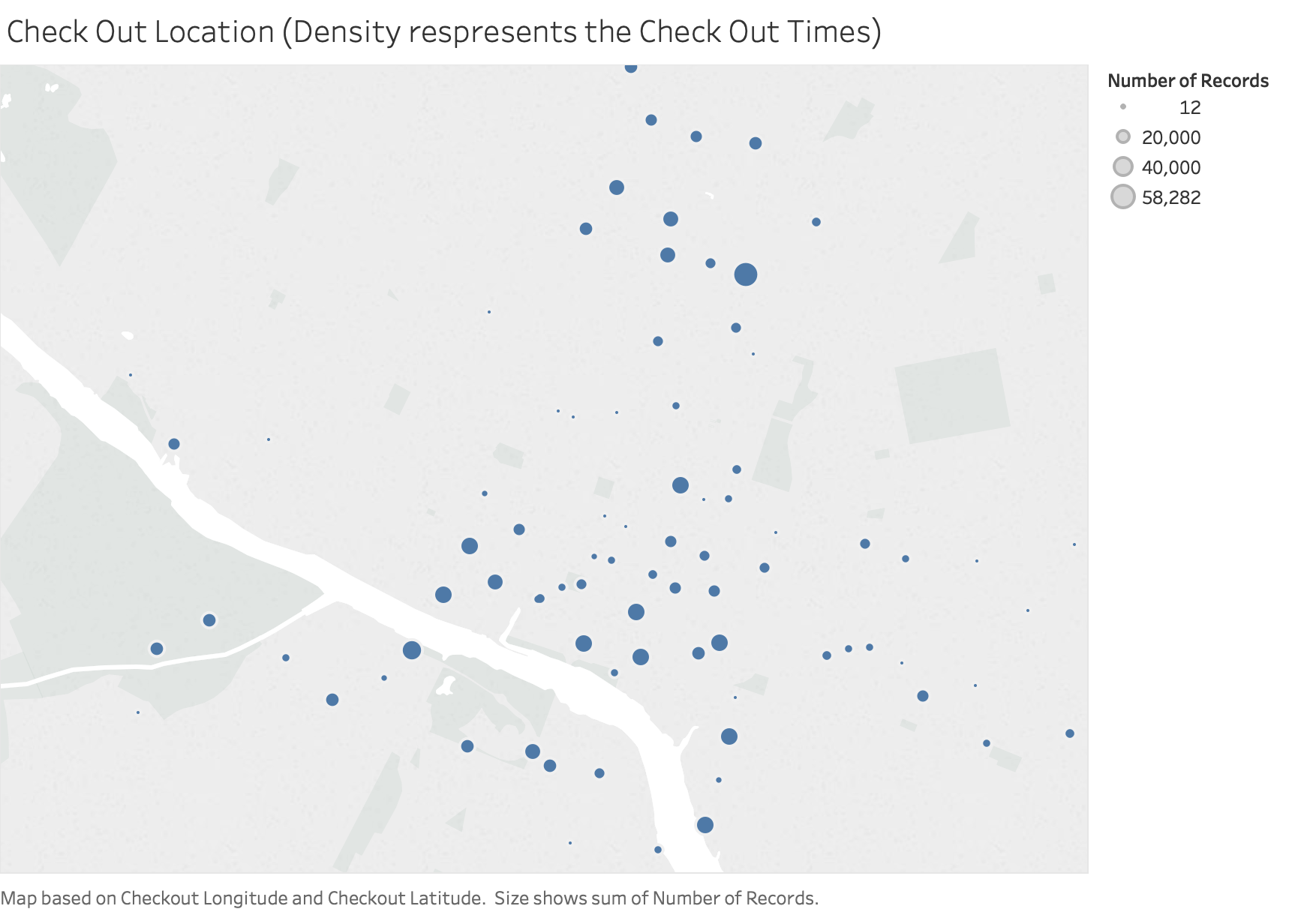
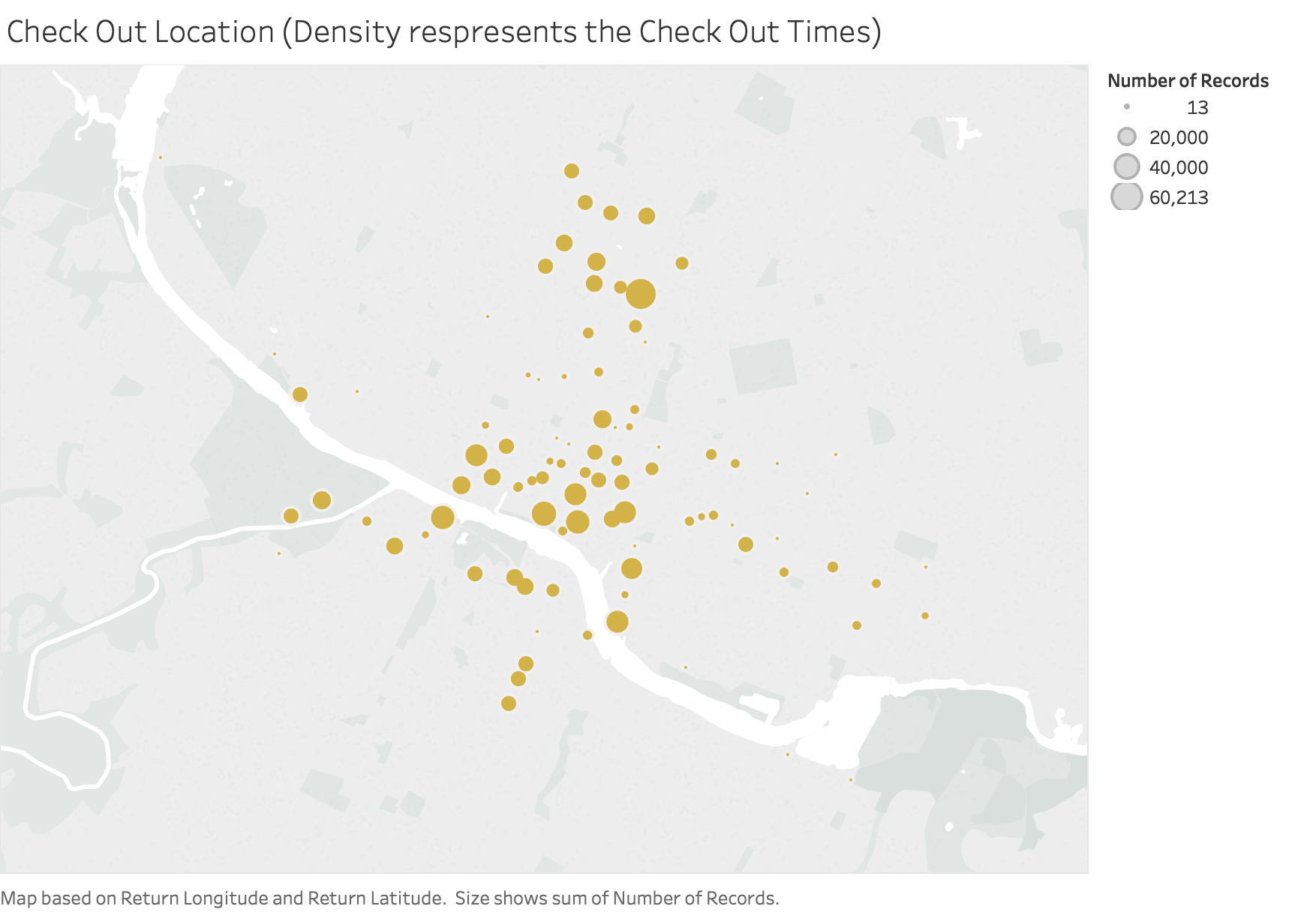
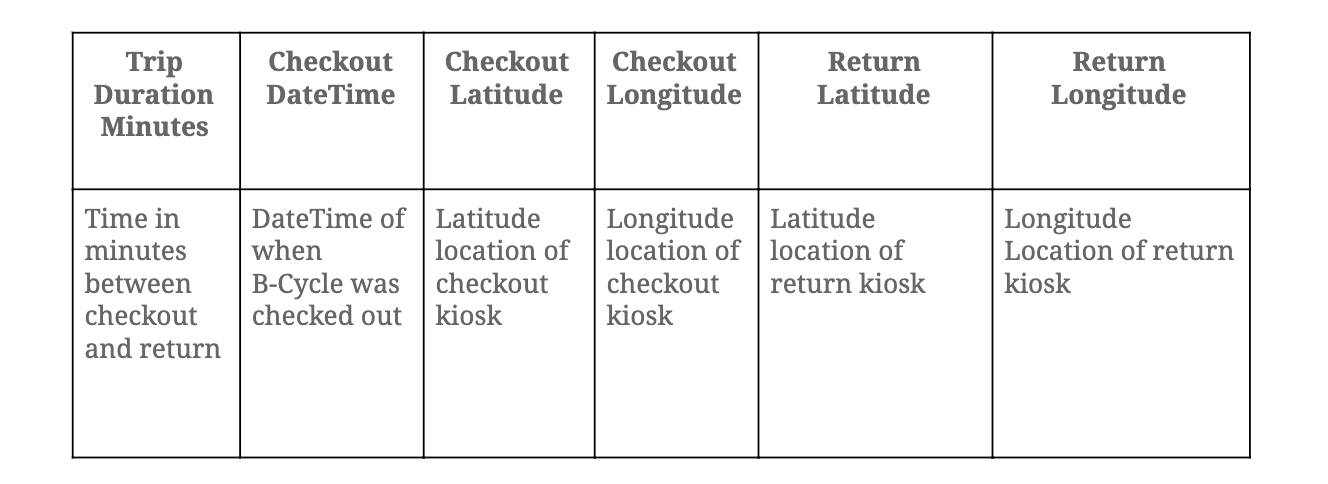 Check out / Return counts density in each Austin Kiosk
Check out / Return counts density in each Austin Kiosk
Beijing might has similar population who need BCycle as Austin BCyclers have.
Why not introduce BCycle into Beijing.
By using K Means on the data of Beijing Geolife, we cluster the footprints into 100 groups. And each group has a center which represents the potential kiosk station.
100 stations

Closer Look
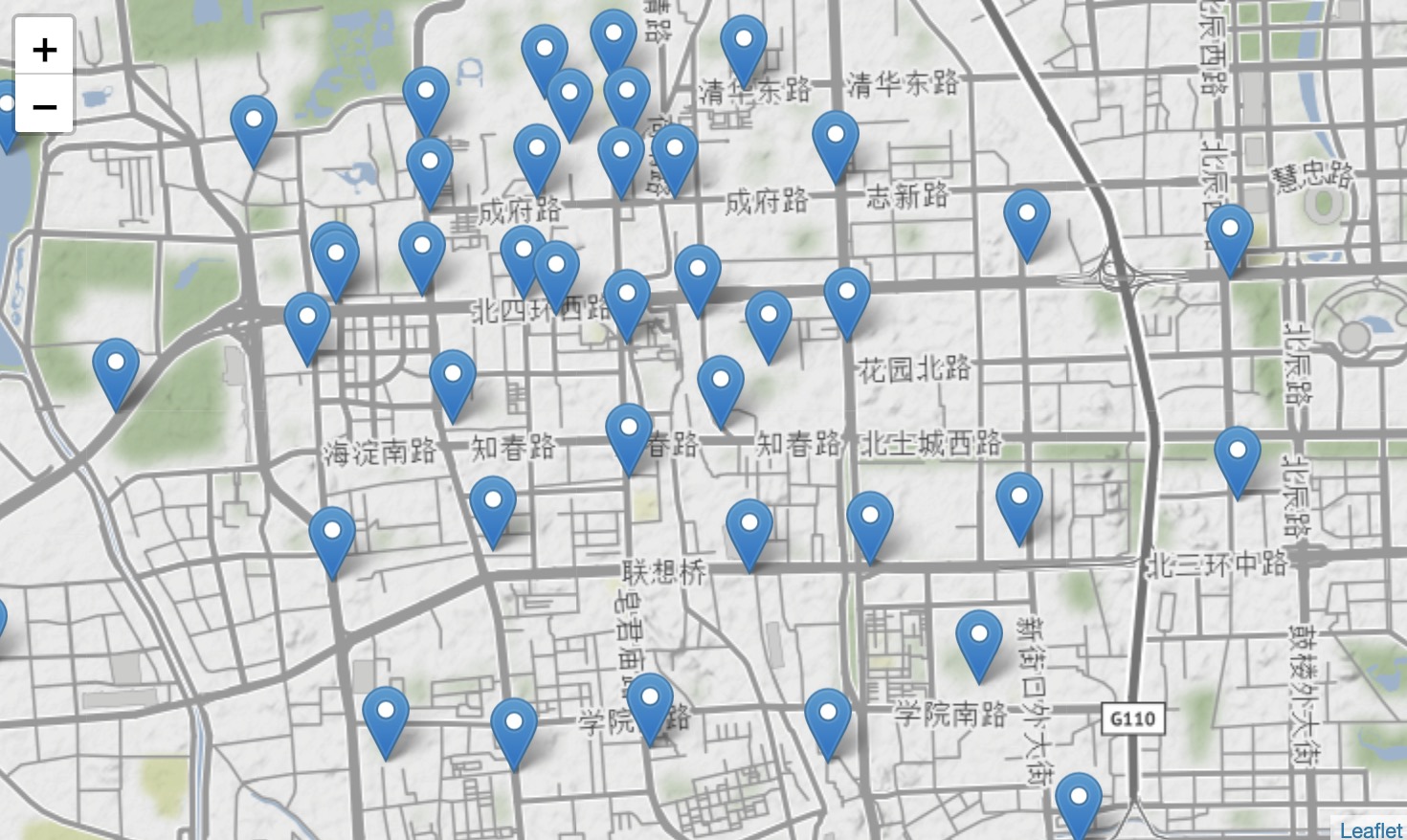
Some kiosks are only 10 meters from each other, which indicates these locations need more bikes and a potential higher frequency of CheckOut/Return.
Will BCycle in Beijing benefit people?
Two Distribution Graph
.png)
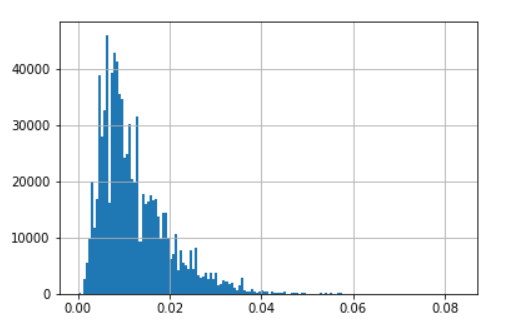
We were thinking if there is a correlation between Distance vs. Duration?
We tried to predict duration by distance, but find big discrepancy.
Then we attempted to visualize this:
The number of times bikes were used (vs. weekday & hour in a day)
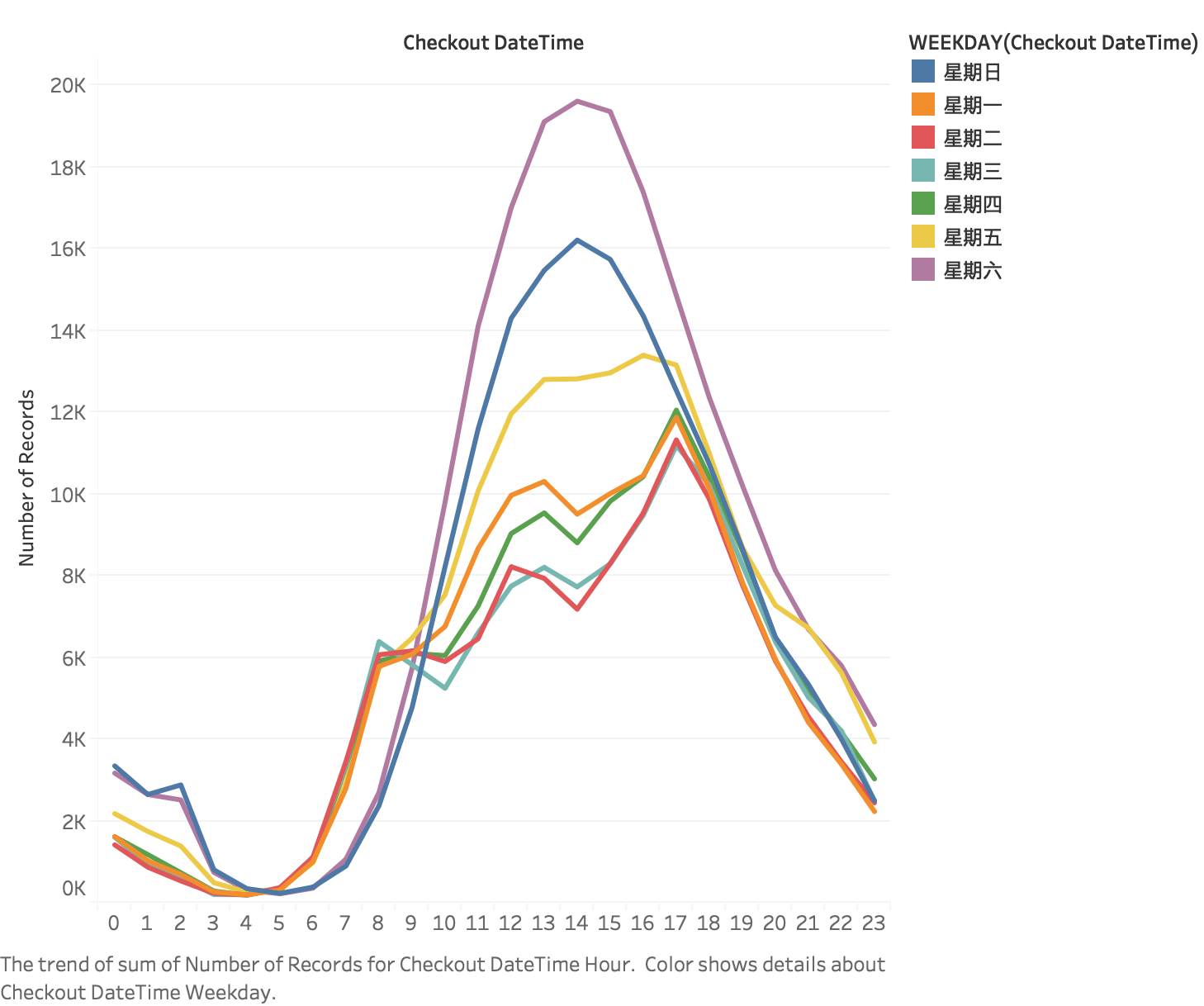 People tended to borrow a bike on weekend and at 11:00 - 20:00.
People tended to borrow a bike on weekend and at 11:00 - 20:00.
So we also visualized this:
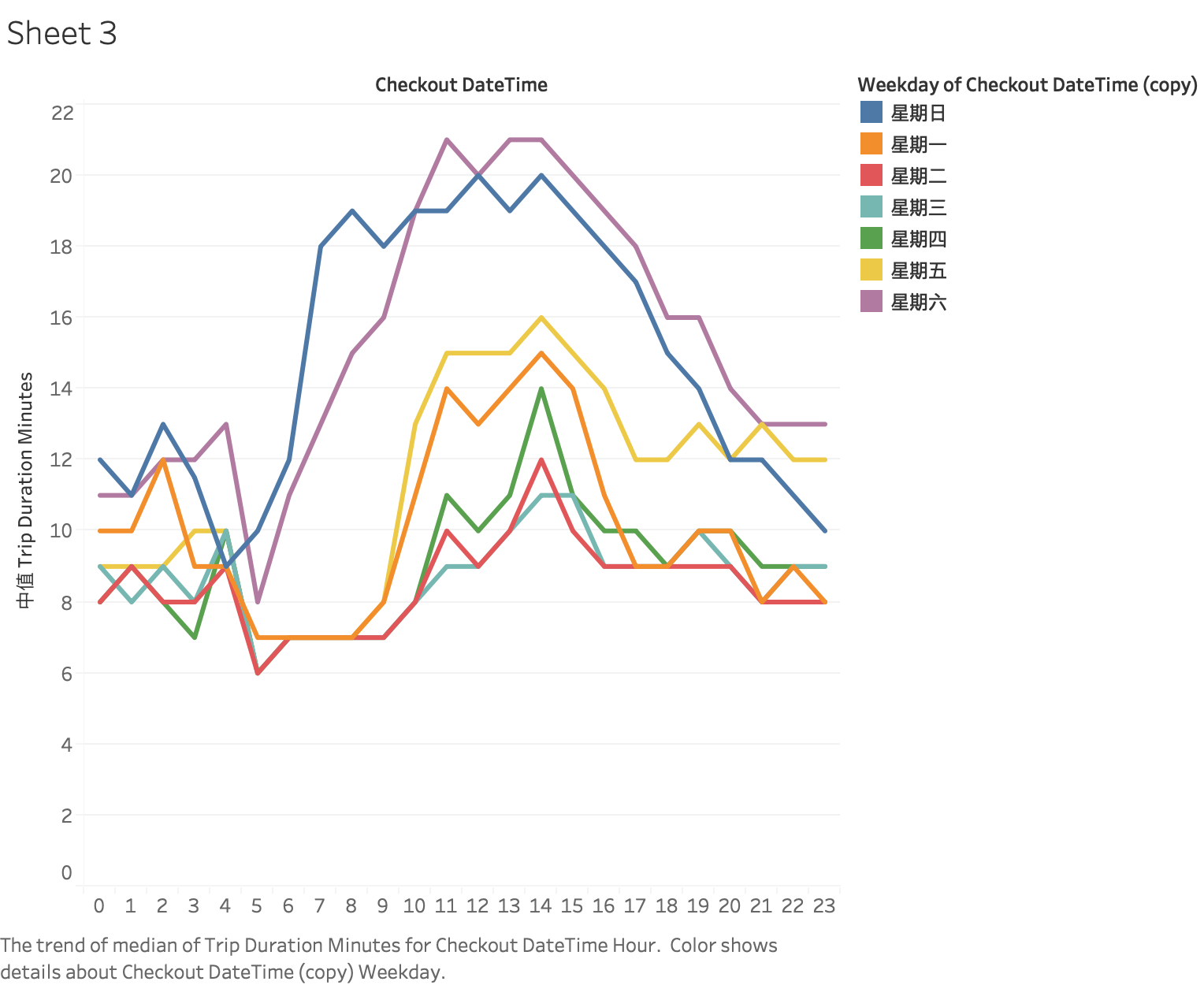
Duration (vs. Weekday & Check Out time) [average]
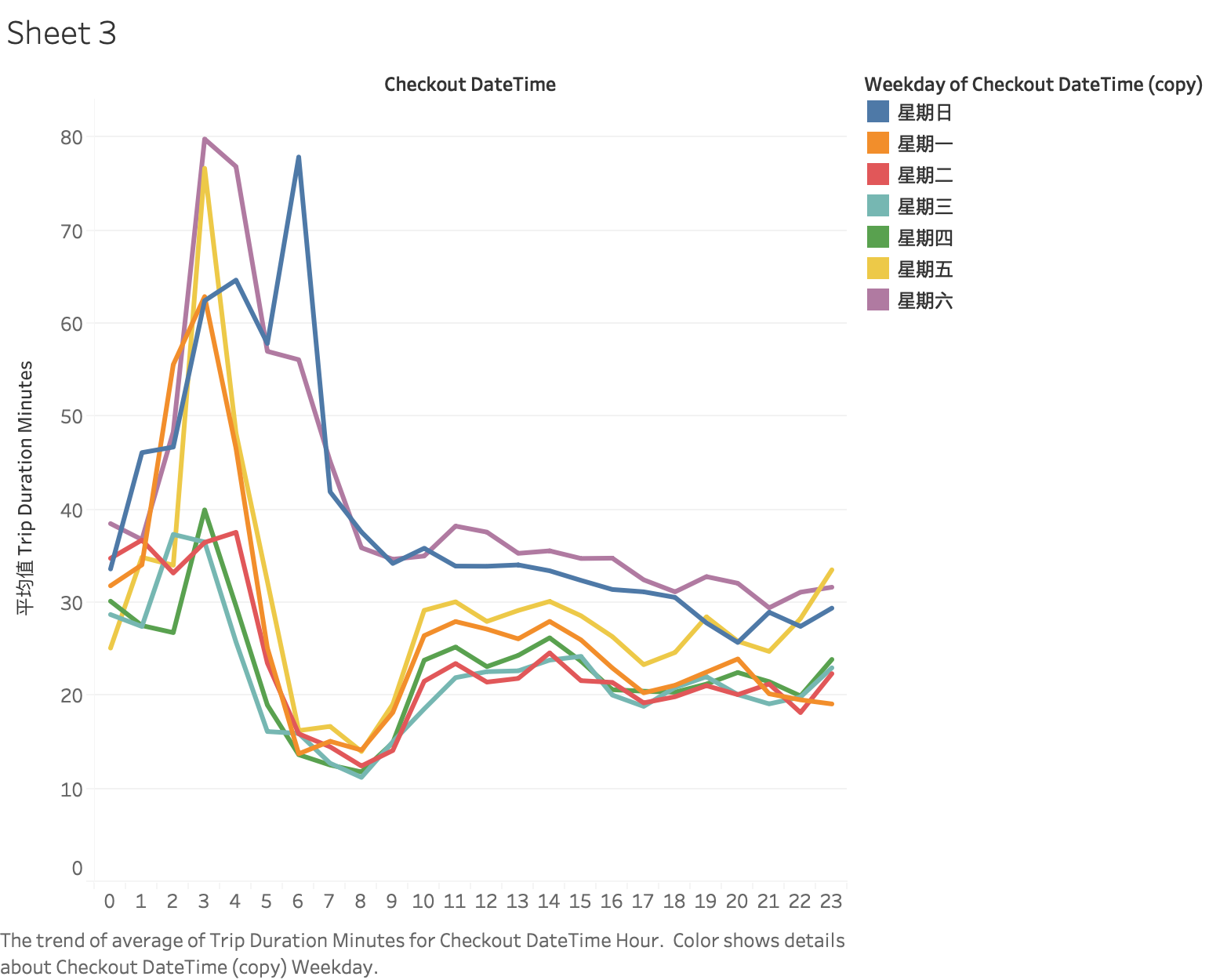
But the average was problematic because of the outliers like 1000 hour duration (probably a missing bike or ruined bike)
So we visualized it again with the median:
Duration (vs. Weekday & Check Out time) [median]
We build a model (M2.1) to predict the duration of a bike ride (by distance, weekday, check out time), by using xgboost.
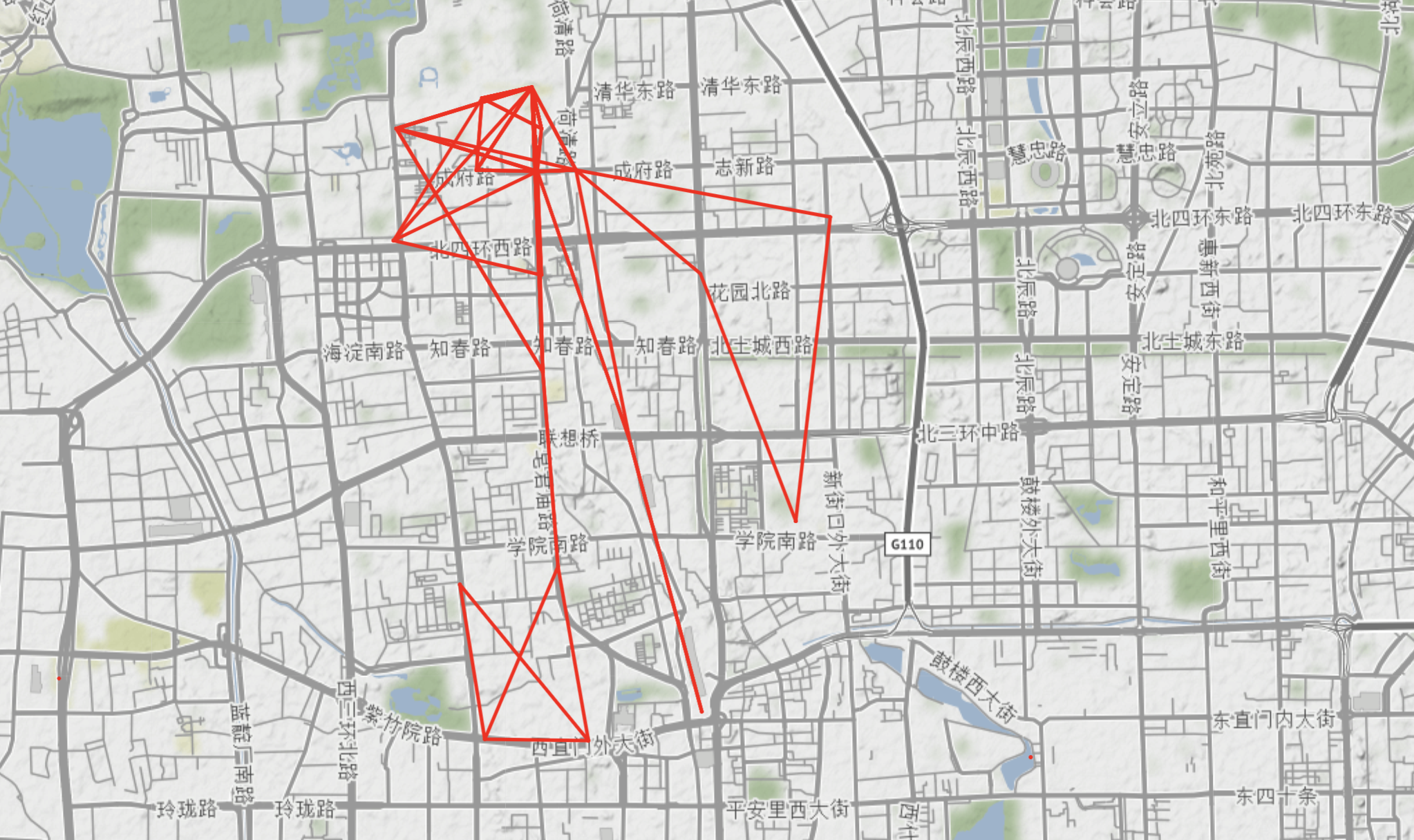
User000 in Beijing
If this person is using BCycle, his/her route will looks like this (generating by his original on-foot data):
The we use the model M2.1 to predict the duration by using BCycle, which is 19.93 minutes.
Comparing to the original time duration, which is 49.24 minutes, the BCycle highly elevate the efficiency.
- The current Geolife data is confusing because of the unclear specification of the transportation type. We can in the future to calculate if the BCycle is time-saving for bus-commuter or private car driver, since the public transportation in Beijing takes extra time to wait and busy car traffic always causes traffic jam.
- By visulizing the membership and counts and duration, we are thinking if we can predict the membership type that Beijing people might want to purchase.