{kind=link}
{kind=link}
![]()
Policy-driven, SQL-standard-aligned query orchestration for LLMs.
The Building Blocks of Safe SQL.
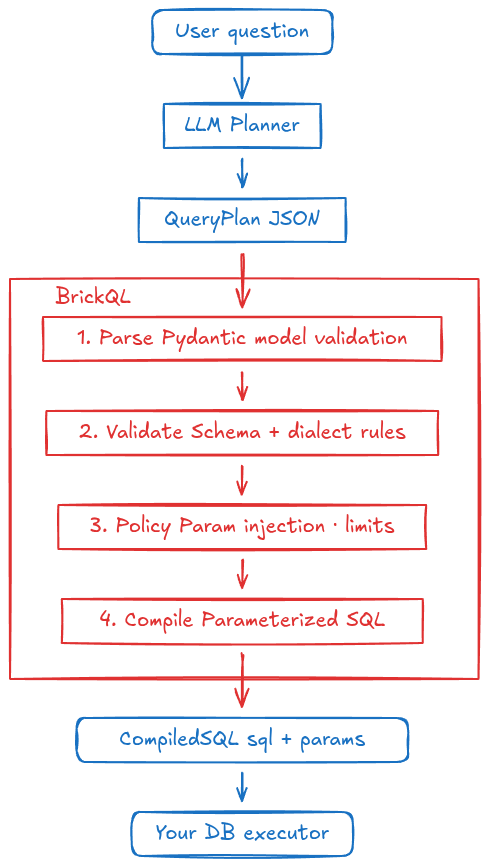
brickQL separates concerns cleanly: the LLM outputs a structured QueryPlan (JSON); brickQL validates it against your schema, enforces policy rules, and compiles it to safe, parameterized SQL. Raw SQL never generated by the LLM.
Scope: brickQL is a read-only query layer. It supports
SELECTqueries only.INSERT,UPDATE,DELETE,CREATE, and all other write or DDL statements are outside its scope by design.
Text-to-SQL is a well-established approach: feed the LLM a natural-language question and a schema, and let it write the SQL directly. It works well for simple queries and controlled environments, but breaks down as soon as real-world constraints appear:
| Challenge | Why it hurts | How brickQL fixes it |
|---|---|---|
| Hallucinated syntax | LLMs invent column names, functions, or dialect-specific constructs that don't exist in your database, causing runtime errors that are hard to debug at scale. | The LLM outputs a typed, structured QueryPlan JSON. Free-form SQL is structurally impossible. brickQL compiles it to parameterized SQL with no string interpolation. |
| No policy enforcement | There is no layer between the generated SQL and the database. Row-level filters, param-bound column constraints, and column allowlists must be bolted on externally, and can silently fail. | Per-table param-bound column enforcement, column allowlists (RBAC), and denied columns. Any column can be bound to a runtime parameter; the LLM cannot bypass the predicate. |
| Prompt-injection surface | The LLM sees and reasons over raw SQL strings. Malicious content in user input or database values can redirect the query, exfiltrate data, or trigger destructive operations. | Implements Plan-Then-Execute: the LLM commits to a structured QueryPlan before any data is returned. Database contents can never inject new instructions. |
| Non-deterministic repairs | When a query fails, the LLM must re-generate free-form SQL, each attempt is a new coin flip with the same attack surface. | All errors are machine-readable: a typed exception hierarchy with code and details fields. to_error_response() feeds structured error context back to the LLM for targeted repair. |
| Dialect fragility | SQL is not a single language. A query that works on PostgreSQL may silently mis-behave on SQLite or MySQL; the LLM has no mechanism to stay within a safe dialect subset. | Opt in to only the SQL features you need via DialectProfile. A fluent builder with dependency enforcement at build() time. |
| Target DB awareness | The LLM must know which database it's targeting and produce the correct syntax — date functions, quoting, pagination, and type casting all differ across engines. | Built-in compilers for SQLite, PostgreSQL, and MySQL. Add any other target by registering a SQLCompiler subclass with one decorator, no core changes. |
brickQL implements the design patterns recommended for SQL agents in Design Patterns for Securing LLM Agents against Prompt Injections (Beurer-Kellner et al., 2025).
Among its ten case studies, §4.2 examines SQL agents under a threat model where the attacker can control the input query or the database content, with goals ranging from unauthorized data extraction to remote code execution. That case study concludes that the Plan-Then-Execute pattern is the correct baseline, and Appendix A identifies strict output formatting and least-privilege access control as mandatory best practices across all agent types. brickQL maps each of these directly to code:
| Paper recommendation | brickQL implementation |
|---|---|
| Plan-Then-Execute - LLM commits to a query plan before any database data is returned to it, so database contents can never inject new instructions | The LLM outputs a QueryPlan JSON; brickQL validates and compiles it to SQL without ever feeding query results back to the LLM |
| Strict output formatting - constrain the LLM to a well-specified format rather than free-form SQL | QueryPlan is a typed Pydantic model; free-form SQL is structurally impossible |
| Least-privilege access control - restrict tables, columns, and operations to exactly what the role needs | DialectProfile allowlists tables and SQL features; PolicyConfig / TablePolicy enforce per-table column allowlists, deny lists, and param-bound columns |
| Parameterized execution - prevent SQL injection from literal values in the plan | All {"value": …} operands are compiled to named placeholders; no string interpolation occurs anywhere in the compilation path |
The OR-bypass hardening in PolicyEngine._where_satisfies_param (which ensures a param-bound column cannot be satisfied by placing the required predicate inside an OR branch) and to_error_response() (which serializes error context to a self-contained JSON string before it is embedded in an LLM repair prompt, preventing plan content from injecting new instructions) are direct responses to security risks identified through the paper's threat model.
# Core library (SQLite only)
pip install brickql
# With PostgreSQL driver (psycopg v3)
pip install "brickql[postgres]"
# With MySQL driver (PyMySQL)
pip install "brickql[mysql]"
# With SQLAlchemy schema reflector
pip install "brickql[sqlalchemy]"Requires Python ≥ 3.10.
import brickql
from brickql import SchemaSnapshot, DialectProfile, PolicyConfig, TablePolicy
# 1. Load your schema snapshot (describes tables, columns, relationships)
import json
snapshot = SchemaSnapshot.model_validate(json.loads(open("schema.json").read()))
# 2. Choose a dialect profile (compose exactly the features you need)
dialect = (
DialectProfile.builder(["employees", "departments"], target="postgres")
.joins()
.aggregations()
.build()
)
# 3. Configure policy (tenant isolation, row limits)
policy = PolicyConfig(
inject_missing_params=True, # auto-inject tenant_id predicates
default_limit=100,
tables={
"employees": TablePolicy(param_bound_columns={"tenant_id": "TENANT"}),
"departments": TablePolicy(param_bound_columns={"tenant_id": "TENANT"}),
},
)
# 4. Compile the LLM's QueryPlan JSON
plan_json = llm_response # {"SELECT": [...], "FROM": {...}, "JOIN": [...], ...}
compiled = brickql.validate_and_compile(plan_json, snapshot, dialect, policy)
# 5. Execute with your own connection - brickQL does not execute queries
cursor.execute(compiled.sql, compiled.merge_runtime_params({"TENANT": tenant_id}))The only output the LLM must produce. A structured, SQL-grammar-aligned JSON object - never raw SQL.
{
"SELECT": [
{"expr": {"col": "employees.first_name"}},
{"expr": {"col": "departments.name"}, "alias": "dept"}
],
"FROM": {"table": "employees"},
"JOIN": [{"rel": "departments__employees", "type": "LEFT"}],
"WHERE": {"EQ": [{"col": "employees.active"}, {"value": true}]},
"LIMIT": {"value": 50}
}Each expression field (expr, GROUP_BY items, ORDER_BY items, window partition_by) is parsed into a typed operand automatically by Pydantic:
| JSON shape | Python type |
|---|---|
{"col": "t.col"} |
ColumnOperand(col="t.col") |
{"value": 42} |
ValueOperand(value=42) |
{"param": "TENANT"} |
ParamOperand(param="TENANT") |
{"func": "COUNT", "args": [...]} |
FuncOperand(func="COUNT", args=[...]) |
{"case": {"when": [...], "else": ...}} |
CaseOperand(case=CaseBody(...)) |
These types are importable if you need to inspect or construct plans programmatically:
from brickql import ColumnOperand, ValueOperand, ParamOperand, FuncOperand, CaseOperand, OperandDescribes your database structure: tables, columns (name, type, nullability), and named relationships. It is purely structural - no policy or access-control concerns. Loaded once at startup and shared across requests.
Both TableInfo and ColumnInfo accept an optional description field. When present, descriptions are included in the LLM system prompt so the model can make better join and filter decisions without guessing from column names alone.
snapshot = SchemaSnapshot.model_validate({
"tables": [
{
"name": "employees",
"description": "One row per employee. Joined to departments via department_id.",
"columns": [
{"name": "employee_id", "type": "INTEGER", "nullable": False},
{"name": "tenant_id", "type": "TEXT", "nullable": False},
{"name": "status", "type": "TEXT", "nullable": True,
"description": "Employment status. Values: ACTIVE, TERMINATED, ON_LEAVE."},
],
"relationships": ["departments__employees"]
}
],
"relationships": [
{"key": "departments__employees", "from_table": "employees",
"from_col": "department_id", "to_table": "departments", "to_col": "department_id"}
]
})Note -
tenant_idis just a regular column in the snapshot. Which columns require runtime parameters and what those params are named is configured inPolicyConfigviaTablePolicy, not in the schema.
Use schema_from_sqlalchemy to populate a SchemaSnapshot directly from an existing database instead of writing the JSON by hand:
from sqlalchemy import create_engine
from brickql import schema_from_sqlalchemy
engine = create_engine("postgresql+psycopg://user:pass@localhost:5432/mydb")
snapshot = schema_from_sqlalchemy(engine)schema_from_sqlalchemy requires the sqlalchemy optional dependency:
pip install "brickql[sqlalchemy]"The reflected snapshot is a starting point - add description fields and manually define any relationships that naming heuristics cannot detect, then save it to a JSON file for inspection and version control.
Compose exactly the SQL features you need. Each method is independent - no hidden stacking, no implicit dependencies:
| Builder method | SQL capabilities unlocked | Requires |
|---|---|---|
| (base) | Single-table SELECT / WHERE / LIMIT |
- |
.joins(max_join_depth=2) |
JOIN (inner, left, self-referential, many-to-many), ORDER BY, OFFSET, ILIKE |
- |
.aggregations() |
GROUP BY / HAVING / COUNT SUM AVG MIN MAX / CASE |
- |
.scalar_functions(*funcs) |
Additional scalar functions by name (e.g. DATE_PART, COALESCE) |
- |
.subqueries() |
EXISTS, correlated and derived-table subqueries |
- |
.ctes() |
WITH / WITH RECURSIVE - CTEs (Common Table Expressions: named temporary result sets scoped to the query) |
.subqueries() |
.set_operations() |
UNION / UNION ALL / INTERSECT / EXCEPT |
- |
.window_functions() |
ROW_NUMBER, RANK, LAG, LEAD, OVER, PARTITION BY + aggregate window functions |
.aggregations() |
.scalar_functions() is additive and can be chained with any other method:
profile = (
DialectProfile.builder(tables, target="postgres")
.aggregations()
.scalar_functions("DATE_PART", "COALESCE")
.ctes()
.subqueries()
.build()
)Dependencies are enforced at build() time with a ProfileConfigError and a clear message.
# Joins + aggregations only
profile = (
DialectProfile.builder(tables, target="postgres")
.joins(max_join_depth=2)
.aggregations()
.build()
)
# Window functions without join support
profile = (
DialectProfile.builder(tables, target="sqlite")
.aggregations()
.window_functions()
.build()
)
# Everything
profile = (
DialectProfile.builder(tables)
.joins()
.aggregations()
.subqueries()
.ctes()
.set_operations()
.window_functions()
.build()
)PolicyConfig controls the overall request policy. TablePolicy configures
per-table rules - each table can have its own param-bound columns, a positive
column allowlist, and/or a denied column list.
from brickql import PolicyConfig, TablePolicy
policy = PolicyConfig(
inject_missing_params=True,
default_limit=200,
tables={
"companies": TablePolicy(param_bound_columns={"tenant_id": "TENANT"}),
"departments": TablePolicy(param_bound_columns={"tenant_id": "TENANT"}),
"employees": TablePolicy(
param_bound_columns={"tenant_id": "TENANT"},
denied_columns=["salary"],
),
"projects": TablePolicy(param_bound_columns={"tenant_id": "TENANT"}),
},
)allowed_columns is a positive allowlist: when non-empty, only the listed
columns may appear in any plan referencing that table. This maps directly to
RBAC grant patterns where a role should see only a specific subset of columns,
without having to enumerate every other column in a blocklist.
analyst_policy = PolicyConfig(
inject_missing_params=True,
tables={
"employees": TablePolicy(
param_bound_columns={"tenant_id": "TENANT"},
allowed_columns=[
"employee_id", "first_name", "last_name",
"department_id", "hire_date", "active",
],
),
},
)denied_columns (per-table or global) is subtracted from allowed_columns
when both are set, so you can always enforce a hard blocklist on top. An empty
allowed_columns (the default) means all snapshot columns are permitted,
subject only to denied_columns.
Different tables can use different param names:
policy = PolicyConfig(
tables={
"employees": TablePolicy(param_bound_columns={"tenant_id": "TENANT"}),
"audit_log": TablePolicy(param_bound_columns={"org_id": "ORG"}),
}
)
params = compiled.merge_runtime_params({"TENANT": "acme", "ORG": "acme-org-42"})The output of validate_and_compile. Contains the parameterized SQL string and a params dict. Runtime parameters (e.g. TENANT) are merged in before execution:
sql_params = compiled.merge_runtime_params({"TENANT": "acme"})
cursor.execute(compiled.sql, sql_params)components = brickql.get_prompt_components(
snapshot=snapshot,
dialect=dialect,
question="List the top 5 highest-paid employees in Engineering",
policy_summary='Always filter by tenant_id using {"param": "TENANT"}.',
)
# Send to your LLM
response = llm.chat(system=components.system_prompt, user=components.user_prompt)All errors are subclasses of brickQLError. ParseError and PolicyViolationError both expose to_error_response() which returns a ready-to-embed JSON string for LLM repair loops.
from brickql import ParseError, PolicyViolationError, ValidationError, CompilationError
try:
compiled = brickql.validate_and_compile(plan_json, snapshot, dialect, policy)
except ParseError as e:
# Malformed JSON - e.to_error_response() returns a JSON string for LLM repair
pass
except PolicyViolationError as e:
# Policy rule violated (denied column, missing param, disallowed table)
# e.to_error_response() returns a JSON string with code + details for LLM repair
pass
except ValidationError as e:
# Schema or dialect rule violated
pass
except CompilationError as e:
raiseRegister a custom SQLCompiler subclass once; validate_and_compile picks it up automatically for any DialectProfile with that target:
from brickql.compile.base import SQLCompiler
from brickql.compile.registry import CompilerFactory
@CompilerFactory.register("mysql")
class MySQLCompiler(SQLCompiler):
@property
def dialect_name(self) -> str:
return "mysql"
def param_placeholder(self, name: str) -> str:
return f"%({name})s"
def like_operator(self, op: str) -> str:
return op
def quote_identifier(self, name: str) -> str:
return f"`{name}`"
# Now you can use target="mysql" in DialectProfile.builder(...)Override build_func_call to control how specific functions are rendered for your dialect - inline literal args, add type casts, rename functions, etc. The default renders FUNC(arg1, arg2, …):
from typing import Any, Callable
@CompilerFactory.register("mysql")
class MySQLCompiler(SQLCompiler):
# ... required abstract methods ...
def build_func_call(
self,
func_name: str,
args: list[Any],
build_arg: Callable[[Any], str],
) -> str:
if func_name.upper() == "DATE_PART":
# MySQL uses YEAR(col) instead of DATE_PART('year', col)
return f"YEAR({build_arg(args[1])})"
return super().build_func_call(func_name, args, build_arg)build_arg is a callback that compiles a single typed Operand to SQL, so the full operand chain (column quoting, param binding, nested functions) works correctly for any arg you forward.
Register a rendering handler; OperatorRegistry wires it in without touching the built-in PredicateBuilder:
from brickql.compile.registry import OperatorRegistry
@OperatorRegistry.register("REGEXP")
def _regexp_handler(op, args, build_operand):
left = build_operand(args[0])
right = build_operand(args[1])
return f"{left} REGEXP {right}"| Limitation | Workaround |
|---|---|
Scalar subqueries in comparison operators - salary > (SELECT AVG(salary) …) is not a supported operand type. |
Use a window-function CTE: compute AVG(salary) OVER () inside the CTE so every row carries the aggregate, then filter on that result column in the outer query. See the example below. |
| JOIN alias column references - column references in SELECT / WHERE must use the original table name, not a JOIN alias. The exception is CTE names, which can be used as table qualifiers. | Use the real table name in all column references; aliases are only for output renaming. |
Scalar subquery workaround - window-function CTE
Goal: list employees whose salary is above the overall average.
{
"CTE": [{
"name": "emp_with_avg",
"query": {
"SELECT": [
{"expr": {"col": "employees.first_name"}},
{"expr": {"col": "employees.last_name"}},
{"expr": {"col": "employees.salary"}},
{
"expr": {"func": "AVG", "args": [{"col": "employees.salary"}]},
"alias": "avg_sal",
"over": {"partition_by": []}
}
],
"FROM": {"table": "employees"},
"WHERE": {"EQ": [{"col": "employees.tenant_id"}, {"param": "TENANT"}]}
}
}],
"SELECT": [
{"expr": {"col": "emp_with_avg.first_name"}},
{"expr": {"col": "emp_with_avg.last_name"}},
{"expr": {"col": "emp_with_avg.salary"}}
],
"FROM": {"table": "emp_with_avg"},
"WHERE": {"GT": [{"col": "emp_with_avg.salary"}, {"col": "emp_with_avg.avg_sal"}]},
"LIMIT": {"value": 50}
}Dialect requirements: .aggregations(), .subqueries(), .ctes(), .window_functions().
# Set up virtual environment and install all dev dependencies
make install
# Lint
make lint
# Auto-format
make fmt
# Type check
make typecheck
# Unit tests only (no database required)
make test-unit
# SQLite integration tests only (in-memory, no Docker)
make test-integration-sqlite
# PostgreSQL integration tests only (starts and stops Docker automatically)
make test-integration-postgres
# All tests - unit + SQLite + PostgreSQL + MySQL (requires Docker)
make testbrickql/
schema/
expressions.py # Operator/operand enums and frozenset constants
operands.py # Typed operand models (ColumnOperand, ValueOperand, …) + Operand union
query_plan.py # QueryPlan Pydantic model + domain methods (collect_col_refs, …)
snapshot.py # SchemaSnapshot, TableInfo, ColumnInfo, RelationshipInfo
dialect.py # DialectProfile + DialectProfileBuilder (fluent API)
column_reference.py # ColumnReference - parse + validate table.column strings
context.py # ValidationContext value object (snapshot + dialect)
converters.py # schema_from_sqlalchemy() - reflect a live DB into SchemaSnapshot
validate/
validator.py # PlanValidator - orchestrates all sub-validators
dialect_validator.py # Feature-flag checks (CTE, subquery, join depth, window)
schema_validator.py # Table / column existence, JOIN relationship keys
semantic_validator.py # HAVING/GROUP_BY pairing, LIMIT range
operand_validator.py # OperandValidator + PredicateValidator (mutually recursive)
policy/
engine.py # PolicyEngine, PolicyConfig, TablePolicy
compile/
base.py # SQLCompiler ABC + CompiledSQL dataclass
registry.py # CompilerFactory + OperatorRegistry (OCP extension points)
context.py # CompilationContext value object (compiler + snapshot)
expression_builder.py # RuntimeContext + OperandBuilder + PredicateBuilder
clause_builders.py # SelectClause / From / Join / Window / CTE / SetOp builders
builder.py # QueryBuilder - orchestrates all sub-builders
postgres.py # PostgresCompiler (%(name)s placeholders, ILIKE, DATE_PART specialisation)
sqlite.py # SQLiteCompiler (:name placeholders, LIKE fallback)
mysql.py # MySQLCompiler (%(name)s placeholders, backtick identifiers, EXTRACT)
prompt/
builder.py # PromptBuilder + PromptComponents
errors.py # Exception hierarchy (brickQLError and subclasses)
docs/
how-it-works.mmd # Simple end-to-end flow (Mermaid)
how-it-works.excalidraw # Visual flow diagram (Excalidraw)
tests/
fixtures/ # schema.json, ddl_sqlite.sql, ddl_postgres.sql, ddl_mysql.sql
integration/ # SQLite (in-memory), PostgreSQL, and MySQL (Docker) integration tests
docker-compose.yml # PostgreSQL and MySQL services for integration tests
pyproject.toml # Package metadata, dependencies, ruff, mypy config
Makefile # Development task runner
MIT - see LICENSE.