Java
자바에서 함수 스택에는 원시타입과 참조타입이 저장되고, 참조타입의 실제 데이터는 모두 힙에 동적생성되어 저장됩니다.
자바 소스코드를 컴파일하면 실행파일(cpu 가 이해할 수 있는 기계어로 된 파일)이 아닌 바이트코드로 작성된 파일이 만들어집니다. (모두 .class 파일로 번역됩니다.)
JVM 은 바이트코드를 차례로 실제 기계코드로 번역하면서 실행합니다.
즉, 특정 바이트코드가 실행되면 메모리에 관련 .class 파일들을 적재하고, JVM 이 바이트코드를 검사하고, 실행합니다. 이때, 모든 바이트 코드를 한번에 메모리에 올리는것이 아닌, 필요한 순간에 메모리에 올립니다.
여러 패키지를 모아서 관리할 수 있습니다.
따로 모듈을 정의하지 않으면 모든 패키지는 unnamed module 에 묶이게 됩니다.
module A {
exports 패키지 이름;
requires 모듈 이름;
}
package 문이 없으면 같은 디렉토리에 포함된 클래스는 하나의 패키지에 포함되고 default package 가 됩니다.
같은 패키지에 있으면 자동으로 import 되므로 import 문 없이 사용할 수 있고, private 한 클래스도 사용할 수 있습니다.
다른 패키지에 있으면 import 문이 필요하고, public 클래스만 사용할 수 있습니다. (public 클래스는 파일명과 동일해야합니다)
java.lang 패키지에 있는 클래스들은 import 없이 사용할 수 있습니다.
byte, short, int, long 이 있습니다.
char, byte, short 를 이용한 계산은 자동으로 int 로 변환되어 계산됩니다.
int 는 cpu 레지스트리 크기와 동일하기 때문에 결국 cpu 로 가면 byte, short 도 int 크기의 공간으로 저장되어 처리됩니다. 따라서 그냥 int 를 사용하면 됩니다.
float, double
오버플로우를 방지하는 정확성을 얻고 성능은 상관없을때 사용할 수 있습니다.
char 로 유니코드를 사용합니다.
char 로 연산하면 자동으로 int 변환하여 처리합니다.
var x = 'a' + 2; // 'c' 의 코드가 찍힙니다.
char 로 변환하지 않으면 문자의 코드가 반환됩니다.
char nestChar(char c) { return (char)(c+1); }
아래에서는 char 두 개를 더하므로 int 로 처리되어 첫번째 함수가 호출됩니다.
void foo(int n) { sout("hello") }
void foo(char n) { sout("hello") }
foo('a' + 'b');
Byte, Integer, Short, Long, Double, Character, Float, Boolean 이 있습니다.
Byte, Integer, Short, Long, Double, Float 은 Number 의 자식클래스입니다.
내부적으로 최적화하기위해 생성자를 사용하지 않고 Integer.valueOf 를 이용합니다.
불변객체입니다.
문자열을 원시타입, 원시타입을 문자열로 변환할 때 많이 사용됩니다.
int n = 10;
String s = "21";
int x1 = Integer.valueOf(s).intValue();
int x2 = Integer.valueOf(s);
int x1 = Integer.parseInt(s);
String str1 = ""+n;
String str2 = Integer.toString(n);
String str3 = Integer.valueOf(n).toString();
한번 값이 할당되면 더 이상 변경할 수 없는 변수로, 상수변수의 선언은 final 을 이용합니다. (다른 언어는 const 를 사용합니다.)
public final double PI = 3.14;
public static final double PI = 3.14; // final: 상수, static: 공간낭비 제거, public: 외부접근허용
상수는 클래스의 객체마다 필요하지 않습니다. 즉, 모든 객체가 동일한 값을 지니는 공통 상수인 경우에는 static 으로 공간의 낭비를 줄이는 것이 좋습니다.
클래스를 final 로 생성하면 해당 클래스를 상속하는 어떠한 클래스도 만들 수 없습니다.
final class A {}
class B extends A {} // 에러가 발생합니다.
메서드를 final 로 생성하면 메서드를 오버라이딩할 수 없습니다. 즉, 재정의할 수 없습니다.
class A { final void do() {} }
class B extends A { final void do() {} } // 에러가 발생합니다.
java.lang 패키지에 포함되어있으며, 모든 클래스의 최상위 부모입니다.
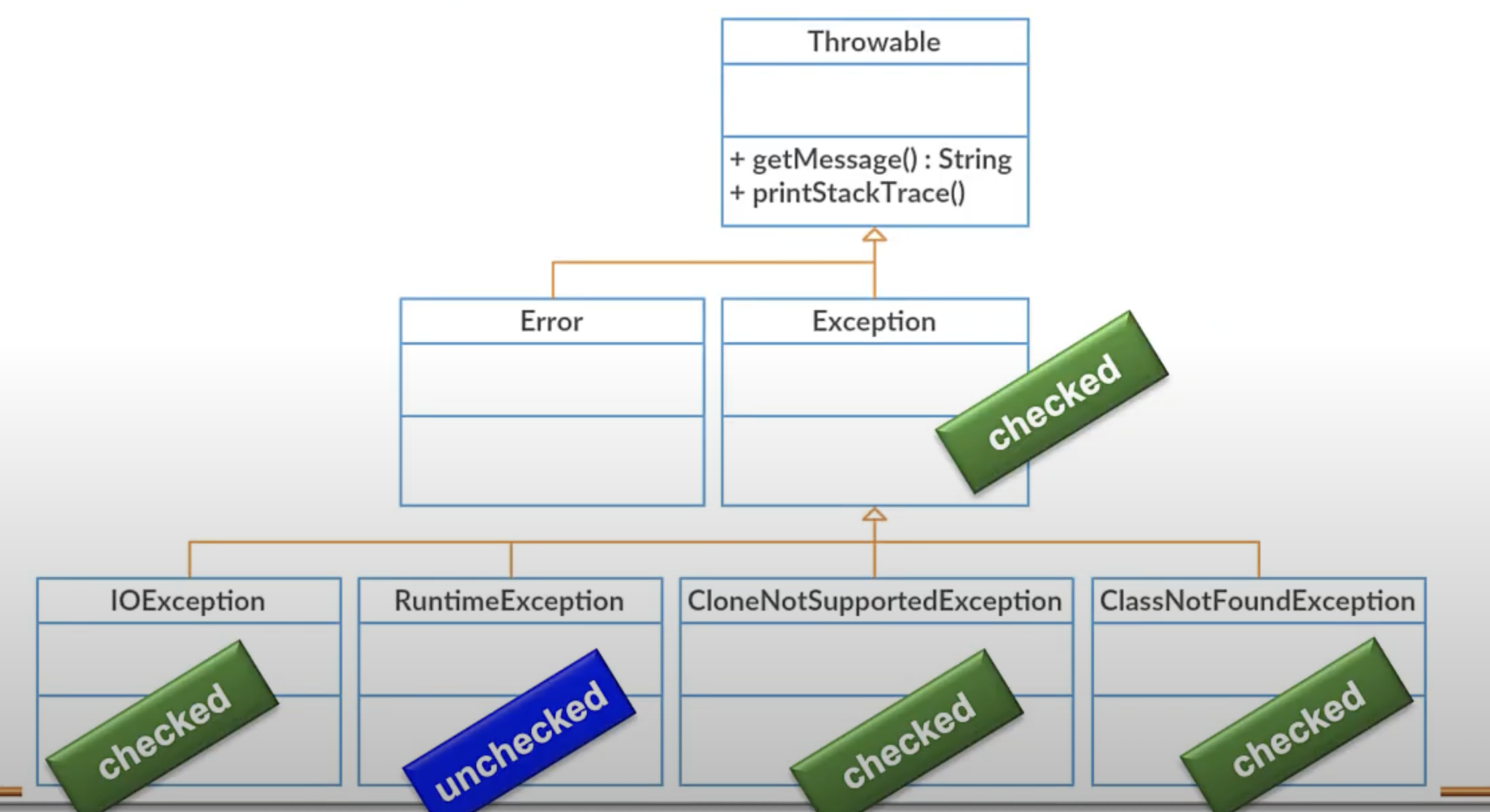
모든 예외는 Throwable 을 상속받습니다. Error 는 JVM 에러, 메모리 부족 등의 개발자가 수정할 수 없는 에러이므로 신경쓰지 않아도 됩니다.
Exception 은 개발자가 수정할 수 있는 에러로, checked, unchecked 로 나뉘게 됩니다.
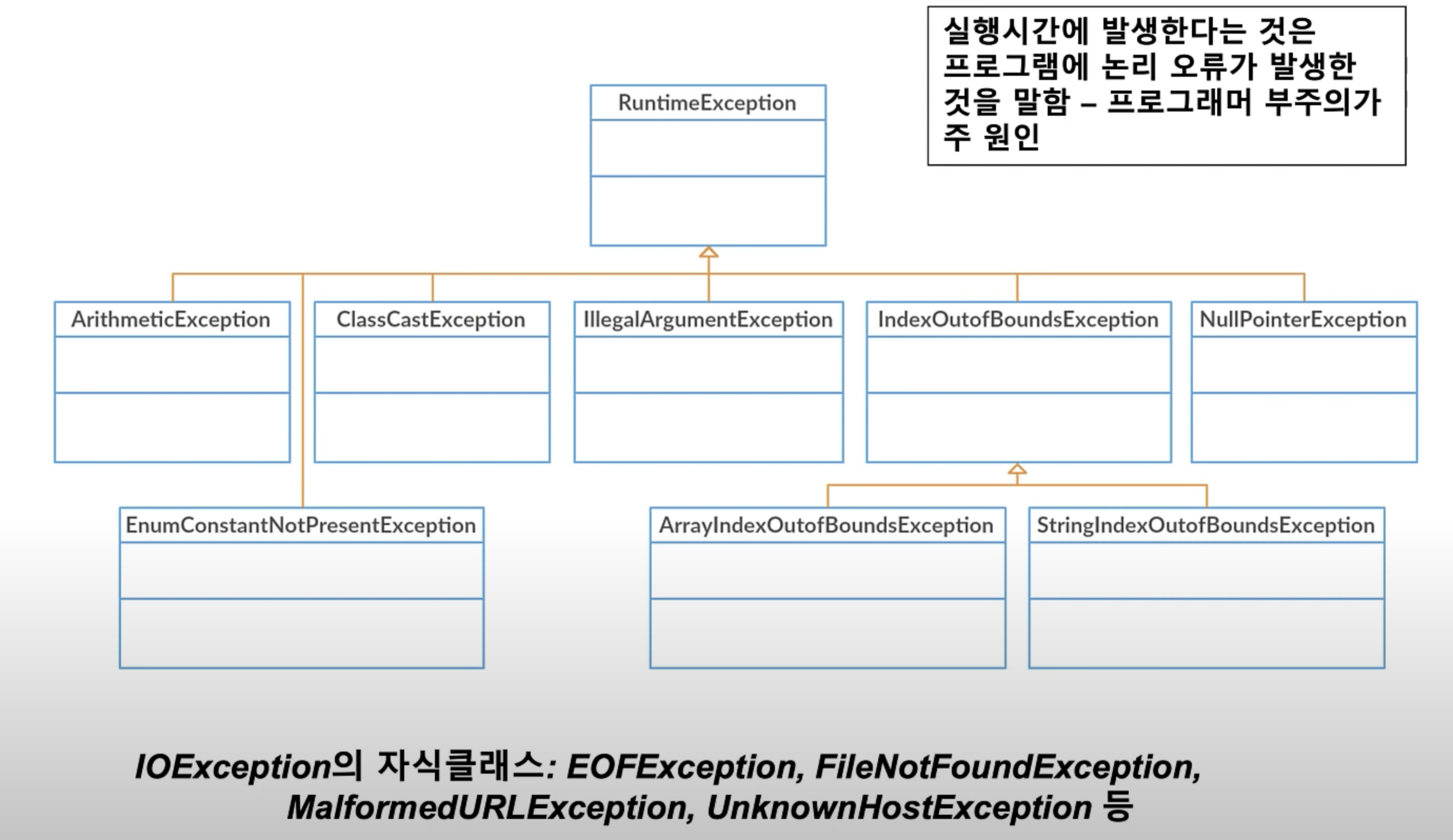
산술연산에러, 타입 캐스팅 에러, 배열 인덱스 에러 등이 있습니다.
처리할수 있는 예외인데, 코드 수정을 통해 발생하지 않도록 할 수 있는 예외입니다.
사용자 입력오류, 프린터 용지부족 등의 사용자 실수 등 프로그램 외적인 요인에 의해 주로 발생되며, 조치 후에 다시 실행하면 정상동작하는 경우입니다.
checked 예외는 반드시 직접처리하거나 공표해야 문법오류가 나지 않습니다.
IOException 등 RuntimeException 을 제외한 나머지는 checked 예외입니다. try-catch 또는 상위 함수가 공표 해주어야합니다.
아래와 같이 g 는 unchecked, f 는 checked 예외를 발생시킬 수 있습니다.
void func(A a) {
g(a); // NullPointerException
f(a); // AException (checked exception)
}
AException 을 try-catch 하던가 공표해주어야 문법오류가 발생하지 않습니다.
- try-catch
void func(A a) {
try {
g(a);
f(a);
} catch(AException e) {}
}
- 공표 func 함수에서 공표합니다.
void func(A a) throws AException {
g(a);
f(a);
}
처리할수 있는 예외인데, 코드 수정을 통해 발생하지 않도록 할 수 있는 예외입니다.
null 인 참조변수 사용, 배열에서 인덱스범위가 정상적이지 않은 경우 등 프로그램에 논리 오류가 포함되어 정상동작에 영향을 주는 경우입니다.
자바에서는 이를 RuntimeException 클래스로 정의하고, 반드시 개발과정에서 수정되어야합니다.
RuntimeException 을 포함하여 자식들은 모두 unchecked 예외입니다. try-catch 를 하지 않아도됩니다.
checked 예외는 Exception 상속, unchecked 는 RuntimeException 을 상속받아 만들 수 있습니다.

보통 기본생성자와 message 를 받는 생성자 두개를 만듭니다.
자식에서는 부모에서 공표되어있는 예외 이외에는 발생시킬 수 없습니다. (당연)
자바는 원시타입이 아니면 객체이고, 모든 객체는 참조타입이고 참조타입은 null 일 수 있습니다.
객체와 관련된 유용한 메서드를 정의하고 있습니다.
newA = Objects.requireNonNull(a);
a 가 null 이면 NullPointerException 이 발생합니다.
newA = Objects.requireNonNullElseGet(a, "무명");
newA = Objects.requireNonNullElseGet(a, () -> new A());
int[] numbers; // 배열이 만들어지지는 않는다.
int[] numbers = new int[8]; // 길이가 8인 배열을 만든다.
new 를 이용해서 배열을 항상 동적으로 생성하고, 원시타입은 0, 참조타입은 null 로(기본값) 초기화됩니다.
아래에서 values 에 numbers 의 값이 복사되는것이 아닌 values 가 numbers 와 동일한 배열객체를 가리키도록 됩니다.
int[] numbers = {1,2,3,4};
int[] values = numbers;
자바는 문자열을 처리하기위해 String 클래스가 있는 라이브러리를 제공합니다. 원래 class 에는 + 와 같은 연산을 할 수 없지만 자바는 언어차원에서 이를 지원해줍니다. 다만, + 연산자는 새로운 공간을 확보하고 합친 문자열을 넣기 때문에 비용이 소요됩니다.
"a" + "b" = "ab"
배열은 length 라는 멤버변수를 갖지만 String 은 length 메소드를 갖습니다.
String 은 보통 new 로 생성하지 않습니다.
프로그램이 실행되면 JVM 에서 객체 풀을 힙에 생성하는데, new 를 이용하지 않고 생성된 문자열은 풀에 저장됩니다.
String f1 = "a";
String f2 = "a";
Sout(f1 == f2); // 참조변수의 비교, 즉 주소의 비교이므로 true 출력
new 를 이용하지 않고 생성하면 풀에 해당 문자열이 있는지 검사하고, 있으면 해당 변수는 풀에 있는 문자열을 가리키게 됩니다. 해당 풀은 검색을 효율적으로 해야되기 때문에 HashMap 으로 생성됩니다.
new 를 이용할 경우, + 연산자를 이용하여 문자열을 결합하는 경우, 각종 String 메소드에서 반환되는 문자열은 풀을 사용하지 않습니다.
이렇게 객체 풀로 처리할 수 있는 이유는 String 이 불변객체여서 같은 한 문자열을 여러 변수에서 참조하고 있더라도 문제가 없고, 한 응용에서 같은 문자열을 자주 사용하기 때문입니다.
String 은 불변객체로, 현재 위치에서 개별문자를 변경할 수 없습니다.
개별문자의 변경이 필요하면 StringBuffer 나 StringBuilder 를 사용하며, 항상 new 를 이용하여 생성해야합니다.
StringBuffer 는 멀티쓰레드 환경에서도 문제없이 돌아가도록하는 여러 기능을 제공합니다.
멀티쓰레드 환경이 아니면 StringBuffer 를 사용하는 것이 비효율적이라서 StringBuilder 가 생겼습니다.
문자열에서 특정 위치에 있는 문자를 얻습니다.
문자열을 문자배열로 바꾸고 싶으면 toCharArray 로 할 수 있습니다.
동일 문자열을 여러번 반복한 문자열을 생성합니다.
String s = "123".repeat(3);
열거형은 클래스를 정의하는 특수한 방법이며, 기존클래스처럼 생성자, 메서드, 멤버변수 등을 추가할 수 있습니다. 단, 생성자는 항상 private 입니다.
자바2 에서는 열거형을 제공하지 않아서 아래와 같이 상수를 이용하여 표현했습니다.
public class Alignment {
public static final int Left = 0;
public static final int Center = 1;
public static final int Right = 2;
// 0, 1, 2 외의 다른 수가 들어올 수 있어 타입 안정성을 보장받을 수 없습니다.
void setAlignment(int align) {
if(align == Alignment.Center) {
}
}
}
생성자를 private 로 만들어서 클래스 밖에서는 인스턴스를 생성하지 못하도록하면, Alignment 클래스는 아래 세 개의 객체만을 유지하게 되므로 그 외의 객체는 전달될 수 없게됩니다. 이를 통해 타입 안정성을 해결할 수 있습니다.
public class Alignment {
public static final Alignment Left = new Alignment();
public static final Alignment Center = new Alignment();
public static final Alignment Right = new Alignment();
private Alignment() {}
void setAlignment(Alignment align) {
// final 로 선언하여 주소를 비교합니다.
if(align == Alignment.Center) {
}
}
}
자바에서는 시도2의 방법을 적용하여 구현하였습니다.
enum 타입은 모두 Enum 클래스의 자식클래스이고 Enum 클래스는 Object 클래스의 자식입니다. Enum 에는 모든 열거형에서 사용할 수 있는 유용한 메서드들을 제공합니다.
Comparable 인터페이스를 구현하여 compareTo 메서드를 갖고있고, ordinal 값을 이용합니다. 또한 compareTo 는 final 메서드라서 재정의할 수 없습니다.
values, valueOf 는 Enum 클래스에 정의된 메서드가 아닌, enum 이 정의되면 자바에서 자동으로 넣어주는 메서드입니다.
열거형 상수에 해당하는 정수값을 반환합니다.
Comparable interface 는 java.lang 패키지에 포함된 interface 로, 객체를 비교할때 구현하여 사용합니다.
public interface Comparable<T> {
public int compareTo(T o);
}
자바에서 두 객체의 내부 상태가 같은지 비교는 Object 클래스에 정의되어있는 equals 메서드를 이용하고, 멤버변수가 5개라면 5개 모두 비교하는것이 일반적입니다.
두 객체의 비교는 compareTo 메서드를 이용하고, 비교해야하는 멤버변수를 통해서만 비교합니다.
한번 구현하게되면 비교 방식이 고정됩니다.
public class Student implements Comparable<Student> {
private String name;
private int age;
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
}
Array.sort(students)
위 처럼 compareTo 가 구현되어있으면 Array.sort(students) 했을때는 age 로 고정됩니다.
이 때, 뒤에 함수를 넣어서 비교방식을 변경할 수 있습니다. name 으로 비교하려면 아래처럼 Comparator 를 구현하는 클래스를 만들어 매개변수로 전달해줄 수 있습니다.
public class StudentNameComparator implements Comparator<Student> {
public int compare(Student s1, Student s2) {
return s1.name - s2.name;
}
Array.sort(students, new StudentNameComparator());
sort 할 때, compareTo 를 쓰지않고 StudentNameComparator 를 이용하게됩니다.
부모가 특정 인터페이스를 구현하면 자식은 자동으로 해당 인터페이스를 구현하게 됩니다.
Comparable 를 구현하는 클래스를 상속받을 경우에는 자식클래스에서 implements Comparable 을 작성할 수 없고, 재정의해서 사용해야합니다.
public class Person implements Comparable<Person> {
@Override
public int compareTo(Person o) {
return 0;
}
}
public class Student extends Person {
// 재정의할때 매개변수의 타입을 변경할 수 없으므로 Student 로 받을 수 없습니다.
@Override
public int compareTo(Person o) {
// (Student)o.name
}
}
위 처럼 재정의 하더라도 매개변수의 타입으로 Student 를 받을 수 없으므로, 메서드를 구현할 때 Student 로 타입을 변환해야할 필요가 있습니다.
아래와 같은 정렬 메서드를 범용으로 사용할 수 있게 하려고합니다. 현재 아래는 Array 만을 받을 수 있습니다.
public class GenericSorter {
public static void sort(int[] array) {}
}
Object 클래스를 이용하면 원시타입 외의 모든 객체를 받을 수 있게 됩니다.
public class GenericSorter {
public static void sort(Object[] array) {}
}
이때, class 는 연산자를 적용할 수 없으므로 sort 할때는 두 값을 비교할 수 있는 함수가 필요하게됩니다. 하지만 클래스에 이를 구현한다고 해서 Object 로는 해당 메서드를 사용할 수 없게되고, 결국 Object 클래스에 비교할 수 있는 메서드를 정의해놓아야하는 문제가 발생합니다.
이를 interface 를 통해 해결할 수 있습니다.
Comparable 인터페이스는 compareTo 메서드를 갖고있고, Comparable 를 구현하고 있는 모든 클래스는 compareTo 메서드가 있다는 것을 알 수 있으므로 문제가 해결됩니다.
public class GenericSorter {
public static void sort(Comparable[] array) {}
}
즉, 모든 클래스를 처리할 수 있는 범용함수를 만드는 것이 아닌, 처리할 수 있는 클래스를 처리하게합니다 .
위의 경우 배열을 받기 때문에 모든 원소가 같지만, 아래의 경우 a 와 b 의 실제 타입은 다를 수 있고, 두 타입이 같다고 하더라도 결과 타입을 원래 타입으로 변환해야하는 번거로움이 발생합니다.
public class GenericMax {
public static Comparable max(Comparable a, Comparable b) {
return a.compareTo(b) > 0 ? a: b;
}
}
이들은 template 을 이용하여 해결할 수 있습니다.
public class GenericMax {
public static <T> T max(T a, T b) {
return a.compareTo(b) > 0 ? a: b;
}
}
하지만 위 코드도 T 가 Comparable 을 구체화한 타입인지 보장할 수 없습니다.
template 과 interface 를 합쳐서 아래와 같이 코딩하여 해결할 수 있습니다.
public class GenericSorter {
public static <T extends Comparable<T>> void sort(T[] array) {
}
}
public class GenericMax {
public static <T extends Comparable<T>> T max(T a, T b) {
return a.compareTo(b) > 0 ? a: b;
}
}
T 타입은 Comparable 를 extends 했으므로 Comparable 을 구현하고 있다고 보장받을 수 있습니다.
빈 인터페이스로, 어떤 특정 메서드를 제공한다는 것을 나타내기 위해 사용하지 않고 클래스가 어떤 특성을 갖고 있다는 것을 나타내기 위해 사용됩니다.
Marker Interface 를 구현한다고 해서 어떠한 메서드를 구현할 필요는 없습니다.
Serializable 은 객체를 자바에서 제공하는 객체저장방식으로 저장해도 되는지 여부를 판단하여 구현여부를 결정해야합니다.
Serializable 을 구현하지 않으면 자바 라이브러리에서는 해당 객체의 저장을 거부합니다.
객체를 파일시스템에 저장할 때는 shallow copy/deep copy 의 반대현상이 나타납니다.
Cloneable 은 clone 메서드가 Object 클래스에 정의되어 있어서 빈 인터페이스가 됩니다.
단순히 clone 메서드를 제공하고 있다는것을 알려주기위해 사용됩니다.
(interface 에는 Object 클래스에 정의되어있는 clone, toString, equals 등의 메서드가 기본적으로 포함되어 있습니다. 즉, interface 리모컨을 사용하더라도 Object 에 정의된 메소드를 호출할 수 있습니다.)
외부 클래스에서만 사용하고 간단한 경우에는 내부 클래스를 만들 수 있습니다.
스레드를 생성할때 해당 스레드가 해야하는 작업을 주어야하며, Runnable 인터페이스를 구현하여 정의하고 run 메서드를 재정의해야합니다.
java.util.Timer 는 쓰레드 개념을 직접적으로 사용하는 타이머로, 정해진 시간간격마다 사건을 발생시킵니다.
자바 16, 데이터클래스를 간단히 정의하여 사용할 수 있도록 해줍니다.
자동으로 생성자, getter, toString, equals, hashCode 를 추가해주고, record 객체는 불변객체입니다.
public record Location(int row, int col) {}
다른 클래스를 명백히 상속받지 않는 경우에는 Object 클래스를 상속받습니다.
이를 통해, 원시타입을 제외하고는 모든 종류의 객체를 유지할 수 있게되고, 범용 프로그래밍에 많이 사용됩니다.
주로 디버깅목적으로 sout 으로 출력할 때 많이 사용합니다.
String.format 을 이용할 수 있습니다.
public String toString() {
return String.format("잔액=%d", balance);
}
두 객체의 내부상태가 같은지 비교할 때 사용됩니다.
equals 는 기본적으로 해당 클래스에 있는 모든 멤버변수를 이용하여 비교해줘야하며, 상속받는 클래스가 있을때와 없을때의 구현방식에 차이가 있습니다.
// 부모가 Object 인 클래스
// Object 클래스에 정의되어 매개변수는 반드시 Object 타입이어야 합니다.
// 따라서 자바에 존재하는 모든 종류의 객체를 받을 수 있고, 예외처리를 해주어야합니다.
public boolean equals(Object o) {
// null 혹은 Class 가 다른 경우에는 false 입니다.
if(o == null || this.getClass() != o.getClass()) {
return false;
}
if(this == o) {
return true;
}
// 매개변수가 Object 타입이므로 타입변환이 필요합니다.
Person d = (Person)o;
// 모든 멤버변수를 비교해야합니다.
return this.age == d.age;
}
// 어떤 클래스의 자식클래스인 경우
public boolean equals(Object o) {
//
if(!super.equals(o)) {
return false;
}
Student s = (Student)o;
return this.supervisor.equals(s.supervisor) && this.year == s.year;
}
getClass 는 정확히 타입이 같아야 true 이고, instanceof 는 부모의 타입일때도 true 를 반환합니다. 따라서 getClass 를 사용해야합니다.
(getClass 는 runtime, 클래스이름.class 는 컴파일시간에 결정됩니다.)
만약 멤버변수로 배열을 갖고있을 경우에는 서로 상호참조할 경우가 발생할 수 있으므로 잘 구현해야합니다. (??)
해싱기술을 이용하는 자료구조에서 활용됩니다. (HashSet, HashMap)
객체에 대해서 유일한 정수값을 제공해주므로, 상태가 다르면 서로다른 정수값을 갖게됩니다.
equals 와 같이 모든 변수를 활용할 수도 있고 일부만 활용할 수도 있습니다.
일반적으로 hashCode 는 equals 와 동일한 값을 반환해주어야합니다. (꼭 이런건 아닙니다.)
일반적으로 Wrapper 클래스, 멤버변수, Arrays, Objects 의 hash 를 이용하여 구현합니다.
public int hashCode() {
// a, b, c 에는 원시, 객체, 배열 모두 가능합니다.
return Objects.hash(a, b, c)
}
Object 에 정의된 clone 은 바로 사용할 수 없습니다. 일단 얕은복사를 하여 객체를 복제해줍니다. 따라서 자바는 얘를 protected 로 만들어서 반드시 재정의하여 사용하도록 강제했습니다.
또한 Object clone 은 복제하는 객체의 클래스가 Cloneable 을 구체화하고있지 않으면 checked 예외인 CloneNotSupportedException 을 발생시킵니다.
따라서 사용하려는 클래스에서는 반드시 cloneable 을 구현하고 clone 을 재정의 해주어야합니다.
자바는 객체를 항상 참조변수로 처리하며 동적으로 생성합니다.
그럼에도 상태가 같은 또다른 객체를 생성해야하는 경우가 종종 있고, 이럴때 clone 을 사용하여 효율적으로 복사합니다. (생성자 호출없이 새 객체를 생성할 수 있습니다.)
clone 메서드에서 반환된 객체는 기존 객체와는 다른 주소값을 갖고, 동일한 클래스의 인스턴스를 생성하고, equals 값이 같아야합니다.
x.clone() != x;
x.clone().getClass() == x.getClass();
x.clone().equals(x) == true;
clone 을 아래와같이 생성자로 구현하면 멤버변수 수만큼 정의해야되어 불편합니다.
public Task clone() {
Task cloned = new Task();
cloned.balance = balance;
// 멤버변수 수만큼 필요
return cloned;
}
멤버변수로 원시타입 혹은 불변객체만 있는 경우 즉, 깊은복사가 필요하지 않은 경우에는 Object 의 clone 을 사용합니다.
public Task clone() throws CloneNotSupportedException {
Task cloned = (Task)super.clone();
return cloned;
}
멤버변수로 객체타입이 있는 경우 즉, 깊은복사가 필요한 경우에는 Object 의 clone 이후에 각 객체타입의 멤버변수를 clone() 합니다.
만약 해당 클래스가 상속받는 부모클래스가 없는 경우에는 try/catch 문으로 작성합니다. catch 하면 상속받는 클래스가 clone 을 지원하지 않도록 만들 수 없습니다.
public Task clone() {
try {
Task cloned = (Task)super.clone();
cloned.A = (A)this.a.clone();
return cloned;
} catch(CloneNotSupportedException e) {
// Cloneable을 구현했기 때문에 이 블록이 실행되는 일은 없다.
return null;
}
}
만약 해당 클래스가 상속받는 부모클래스가 있는 경우에는 CloneNotSupportedException 를 공표합니다.
public Task clone() throws CloneNotSupportedException {
Task cloned = (Task)super.clone();
cloned.A = (A)this.a.clone();
return cloned;
}
정리

공표와 try/catch 의 차이를 잘 모르겠습니다. 직접 해봅시다...
=> final 클래스 즉, 단말 클래스면 공표하지않고 try/catch 를 사용하는것같습니다.
(얕은 복사는 기존 객체의 메모리를 그대로 복사하여 새 메모리 주소로 옮겨줍니다. 이때 기존객체의 메모리에서 다른 객체를 참조하는 애가 있을때 복사한 애도 얘를 보는 문제점이 발생합니다.)
객체의 클래스에 대한 정보를 가진 Class 객체를 반환합니다.
두 객체가 동일 타입인지 확인할 때, reflection 라이브러리를 활용할 때 사용됩니다.
예전에는 Object 를 이용하여 제네릭 플밍을 했지만 타입변환이 불편하여 템플릿 방식이 도입되었습니다.
// ArrayList<T>
ArrayList<String> files = new ArrayList<String>();
String fileName = files.get(0);
내부적으로 Object 를 사용하고 있기때문에 T 에 원시타입을 넣을 수 없고, Integer 같은 wrapper 클래스를 사용해야합니다.
스택은 내부적으로 배열을 기반으로 합니다. 배열 기반이면 동적 배열을 사용하고, 공간이 부족하면 두배씩 확장하여 서비스해주기 때문에 초기 capacity 를 잘 설정하는 것이 성능에 도움이 됩니다.
Stack<Integer> s = new Stack<>(100);
s.push(5);
sout(s.peek());
sout(s.pop());
연결구조 기반의 스택을 사용하려면 아래처럼 선언해야합니다. 연결구조는 데이터를 추가할 때마다 공간을 확보하므로 초기 데이터는 신경쓰지 않아도 됩니다.
Deque<Integer> s = new LinkedList<>();
ArrayDeque 는 내부적으로 배열을 사용하기때문에 초기용량설정이 중요합니다. LinkedList 는 연결구조로 생성합니다.
Queue<Integer> q = new ArrayDeque<>(10);
Queue<Integer> q = new LinkedList<>();
PriorityQueue 는 heap 으로 구현되어있고, heap 은 배열기반입니다.
함수를 넘겨주지 않으면 T 타입의 compareTo 를 이용하여 우선순위를 판단합니다.
Queue<Integer> q = new PriorityQueue<Integer>(10); // minHeap
Queue<Integer> q = new PriorityQueue<Integer>(10, (a, b) -> b.compareTo(a)); // maxHeap
HashSet 은 hashing, TreeSet 은 red-black tree (균형이진검색트리) 로 구현되어 있습니다.
Set<Integer> s = new HashSet<Integer>();
HashSet 은 초기용량이 매우 중요한데, 에 n 개를 저장한다면 n*1.3 의 초기용량을 정해주는게 효율적입니다.
또한, 해싱을 하기위해 hashcode, 충돌을 확인하기위해 equals 의 재정의가 필요하고 매우 중요합니다. add, contains, remove 연산이 O(1) + 해싱비용 + 충돌확인비용 입니다. 동적배열기법입니다.
TreeSet 은 기본적으로 compareTo 를 이용합니다. add, contains, remove 연산이 O(log N) 입니다. 연결구조기반입니다. 순서에 대한 정보를 제공합니다. 캐싱에 불리합니다. 초기용량에 대해 알지 못하면 TreeSet 이 유리할 수 있습니다.
HashMap 은 용량 중료, hashcode, equals 가 중요합니다. O(1) 입니다.
TreeMap 은 compareTo 혹은 비교함수를 정의해줘야합니다. O(logN) 입니다.
Map<String, Integer> animals = new HashMap<>(100);
위의 자료구조에 공통적으로 적용할 수 있는 유틸리티입니다.
max, min, reverse, rotate, shuffle, sort 등의 메서드를 제공합니다.
String[] slist = {"app", "gra", "bna", "str" };
List<string> list = Arrays.asList(slist);
sout(Collections.min(list));
sout(Collections.max(list));
Collections.sort(list);
Collections.reverse(list);
T, U 타입은 new 를 통해서 객체를 생성할 수 없습니다.
public class Pair<T, U> {}
아래 min 에서는 비교할 수 있는 타입이 와야되는데, 아래처럼하면 모든 타입이 오게됩니다.
public class ArrayAlg {
public static <T> T min(T[] a) {
}
}
따라서 Comparable 인터페이스를 구현한 타입만 올수있도록 제한합니다.
public class ArrayAlg {
public static <T extends Comparable<T>> T min(T[] a, int size) {
}
}
만약 다중으로 제한하고 싶으면 & 를 사용할 수 있습니다.
T extends Comparable<T> & Cloneable
제한에 사용되는 타입은 class, interface 모두 가능하지만 클래스는 오직 한 개만 가능하고, 반드시 처음에 위치해야합니다.
T extends A & B & C // 이중에 클래스가 있다고하면 반드시 A 만 클래스여야합니다.
class Pair<T, U> {
T first;
U second;
Pair(T a, U b) {
this.first = a;
this.second = b;
}
}
class ArrayAlg {
public static <T extends Comparable<T>> Pair<T, T> minmax(T[] a) {
if(a == null || a.length == 0) return null;
T min = a[0];
T max = a[0];
for(int i=1; i<a.length; i++) {
if(min.compareTo(a[i]) > 0) min = a[i];
if(min.compareTo(a[i]) < 0) min = a[i];
}
return new Pair<T, T>(min, max);
}
}
Person 클래스가 Student 클래스의 부모 클래스일때 Pair 은 Pair 의 부모 클래스는 아니게됩니다.
즉, 아래의 경우 Pair 에 Pair 를 받지 못하게되는 불편함이 생기게 됩니다.
public static void printFriend(Pair<Person> p) {
Person p1 = p.getFirst();
Person p2 = p.getSecond();
System.out.println("hello", p1.getName(), p2.getName());
}
이때 와일드카드 타입을 사용할 수 있습니다. 아래처럼하면 Person 을 포함한 후손 클래스들을 받을 수 있게 됩니다.
public static void printFriend(Pair<? extends Person> p) {
Person p1 = p.getFirst();
Person p2 = p.getSecond();
System.out.println("hello", p1.getName(), p2.getName());
}
아래처럼하면 Student 의 부모 클래스들을 받을 수 있게 됩니다.
public static void printFriend(Pair<? super Student> p) {
Person p1 = p.getFirst();
Person p2 = p.getSecond();
System.out.println("hello", p1.getName(), p2.getName());
}
? 는 ? extends Object 의 축약으로 동일한 의미를 가집니다.
Pair<?> 처럼 제한이 없는 와일드카드를 사용할 수 있고, Pair 와 같이 모든 타입을 받을 순 있습니다.
만약 T, ? 둘 다 가능하다면 ? 로 만드는 것을 더 선호합니다.
public static boolean hasNull(Pair<?> p) {
return (p.getFirst() == null || p.getSecond() == null);
}
public static <T>boolean hasNull(Pair<T> p) {
return (p.getFirst() == null || p.getSecond() == null);
}
하지만 제네릭과는 달리 ? A = a.get() 와 같이 코드를 작성할 수는 없습니다.
public static void swap(Pair<?> p) {
? t = p.getFirst(); // 에러
p.setFirst(p.getSecond());
p.setSecond(t);
}
아래처럼 헬퍼 메서드를 이용하여 구현할 수 있지만 그냥 제네릭만 이용한거와 차이가 없으므로 굳이 이렇게하지는 않습니다.
public static void swap(Pair<?> p) {
swapHelper(p);
}
public static <T>void swapHelper(Pair<T> p) {
T t = p.getFirst();
p.setFirst(p.getSecond());
p.setSecond(t);
}
Producer Extends, Consumer Super 로, T 타입의 값을 제공하는 형태이면 extends, T 타입의 값을 사용하는 형태이면 super 를 사용하는게 많은 타입을 사용할 수 있도록 유도합니다.
void addAll(List<Pet> list, List<? extends Pet> inList);
void getAllDogs(List<Pet> list, List<? super Dog> outList);
addAll 은 inList 의 모든 요소를 list 에 추가하므로 inList 는 Producer 입니다. Pet 에는 Pet, Dog, Cat 등의 타입이 올 수 있으므로 List<? extends Pet> 으로 합니다.
getAllDogs 는 list 의 요소 중 Dog 만 outList 에 저장하므로 outList 는 Consumer 입니다. List 으로만 해도되지만 Dog 은 Pet, Object 등의 타입에도 저장될 수 있으므로 <? super Dog> 으로 하는것이 좋습니다.
이렇게 안정성에 문제없는 다양한 타입을 사용하기 위해 타입 매개변수를 이용합니다.
addAll 은 모든 c 값을 arrayList 로 넣는 작업이므로 c 는 Producer 입니다. E 의 후손들 모두 arrayList 에 넣습니다.
boolean addAll(Collection<? extends E> c)
void forEach(Consumer<? super E> action)
boolean containsAll(Collection<?> c)
binarySearch 는 비교할 수 있어야하므로 Comparable 로 제한하고 있습니다.
또한, T 가 Dog 이면 Pet, Object 를 받을 수 있도록 <? super T> 로 구현되어 있습니다.
public static <T> int binarySearch(List<? extends Comparable<? super T>> list, T key)
c 는 sort 할 함수이고, list 로부터 받아서 사용하므로 Comsumer 입니다. Dog, Pet, Object 로도 처리할 수 있도록 해줍니다.
public static <T> void sort(List<T> list, Comparator<? super T> c)
비교가 필요하므로 Comparable<? super T> 가 있습니다. 그냥 <T extends Comparable<? super T>> 로 되어있으면 T 를 Comparable 타입으로 변환해서 사용하는데, 앞에 Object 가 있어서 T 를 Object 로 변환해서 사용합니다. 이는 이전 코드와 호환될 수 있도록 하기 위해서입니다.
public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll)
shuffle 은 단순히 위치만 바꾸는것이므로 어떠한 타입이 와도 상관없어서 제한이 없는 와일드카드만 사용합니다.
void shuffle(List<?> list)
자바의 Generic 은 사용된 타입 인자의 종류와 상관없이 하나의 코드만 생성합니다.
제한되지 않은 타입이면 타입 매개변수를 Object 로, 제한된 타입이면 제한된 타입으로 T 를 변경합니다. 내부적으로는 타입변환을 알아서 해줍니다.
이 때문에 실행시간에 타입 인자에 대한 정보가 없고, 타입인자타입의 객체나 배열을 생성할 수 없고, instanceof 를 사용할 수 없고, static 멤버에 타입 매개변수를 적용할 수 없고, 원시타입을 타입인자로 사용할 수 없습니다.
Pair<String> a;
Pair<Integer> b;
a.getClass() == b.getClass(); // true
a instanceof Pair<String> // 문법오류
a instanceof Pair<?> // true
Pair<String>[] table = new Pair<String>[10]; // error
Pair<?>[] table = new Pair<?>[10] // true
Pair 타입인지만 확인할 수 있고 Pair 인지는 확인할 수 없습니다.
범용 클래스의 객체 배열은 선언할 수 없고, 원한다면 Object 혹은 라이브러리에서 제공되는 범용 클래스를 이용해야합니다.
ArrayList<Student> students = new ArrayList();
students.stream().filter(s -> s.getYear() == 2).forEach(System.out::println); // System.out 의 println 함수를 이용합니다.
람다 이전에 함수를 다른 함수로 전달하기 위해서는 아래와 같이 interface 를 이용했습니다.
sort 에 compareTo 이외의 다른 방법을 사용하고 싶으면 아래처럼 Comparator interface 를 구현하는 class 를 만들어서 객체를 생성한 후 인자로 전달해주어야 했습니다.
즉, 다른 함수에서 필요한 함수를 interface 로 정의해야 했습니다.
interface Comparator<T> {
int compare(T a, T b);
}
class StringLengthComparator implements Comparator<String> {
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length();
}
}
Arrays.sort(list, new StringLengthComparator());
만약 한번만 쓰는 경우에는 아래처럼 익명 클래스로 만들어서 사용했습니다.
Arrays.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length();
}
});
클래스를 만들거나 객체를 생성할 필요없이 아래처럼 사용할 수 있게 됩니다.
Comparator 의 compare 함수에 맞는 표현을 넘겨줘야 합니다.
Arrays.sort(list, (s1, s2) -> s1.length() - s2.length);
정수 2개를 받아 정수를 반환해주는 함수를 받는 함수를 정의해보자
인터페이스를 이용하여 받고자하는 함수의 타입을 정의합니다. 함수가 여러개면 어느 함수를 이용할지 모호해지므로 반드시 하나만 작성해야합니다.
@FunctionalInterface
public interface IntegerBinaryOperation {
int doOP(int a, int b);
}
int func(int a, int b, IntegerBinaryOperation biFunc) {
return biFunc.doOP(a, b)
}
짝수 람다식을 정의합니다.
@FunctionalInterface
public interface IntPredicate {
boolean test(int n);
}
IntPredicate isEven = n -> (n % 2 == 0);
System.out.println(isEven.test(100));
컴파일러가 추상 메소드의 개수를 검사하고, 하나를 초과하면 문법오류를 발생시킵니다.

예로, BiFunction 은 2개의 인자를 받고 1개의 객체를 리턴하는 인터페이스입니다.
위처럼 직접 정의하지말고 이렇게 내부에 정의되어있는 함수형 인터페이스를 찾아서 사용하면됩니다.
public interface BiFunction<T, U, R> {
R apply(T t, U u);
}
기존에 정의되어있는 static method 혹은 method 를 호출하는 것이 전부일때는 아래처럼 축약할 수 있습니다.
Consumer<String> println = x -> System.out.println(x);
Consumer<String> println = x -> System.out::println;
DoubleBinaryOperator pow = (x, y) -> Math.pow(x, y);
DoubleBinaryOperator pow = Math::pow;
스트림은 함수형 프로그래밍과 결합하여 복합타입의 자료구조에 대해 집단연산을 내부 반복으로 계산할 수 있게 해줍니다.
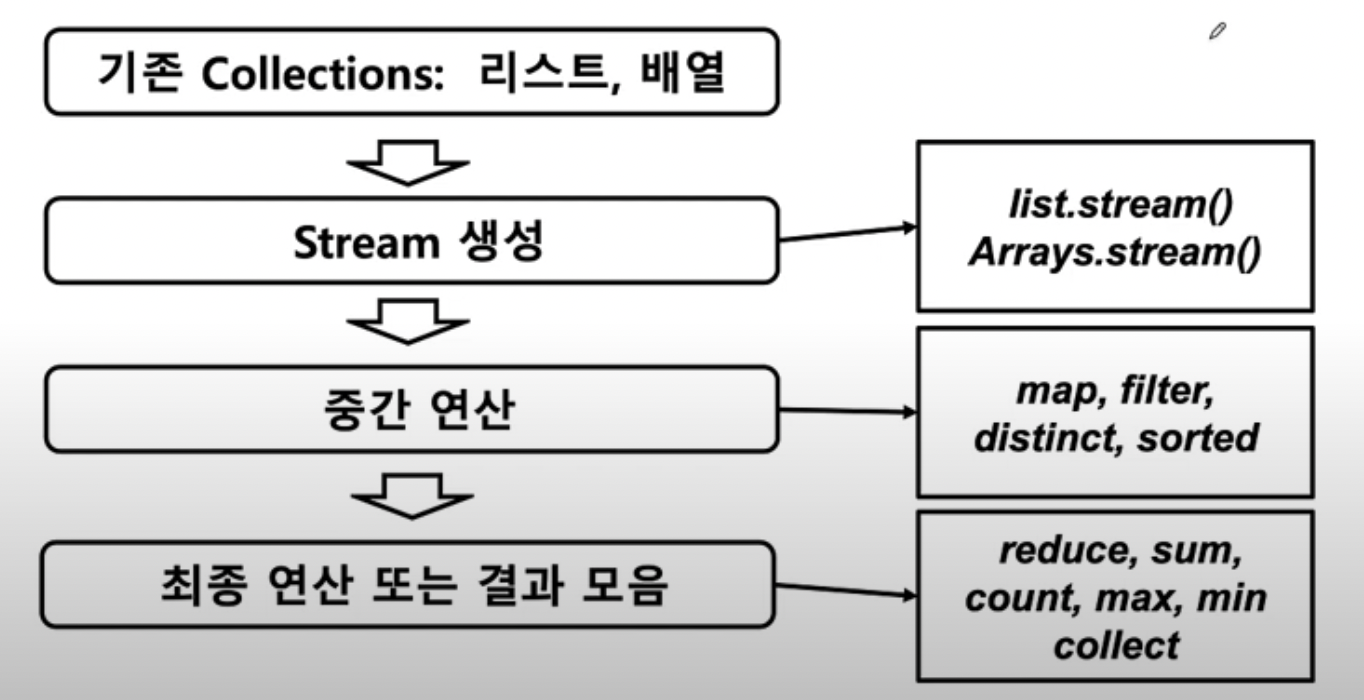
복합타입을 stream 으로 변환하여 여러가지 연산을 적용합니다.
원본데이터 변경안함, iteration 이용, 병행처리 지원, 지연연산 지원, 순서유지가능, 재사용 불가능.
List<Integer> numbers = Arrays.asList(1,2,3,4,5);
int sum = numbers.stream().filter(n -> n % 2 != 0).map(n -> n * n).reduce(0, (x, y) -> x + y);
int sum = numbers.stream().filter(n -> n % 2 != 0).map(n -> n * n).reduce(0, (x, y) -> Integer.sum(x, y));
int sum = numbers.stream().filter(n -> n % 2 != 0).map(n -> n * n).reduce(0, Integer::sum);
모음 갯수를 구합니다. chars 는 문자열을 정수스트림으로 변환해줍니다.
String str = "abcdefg";
str.chars().filter(c -> "aeiou".indexOf(c) != -1).count();
IntStream.of 로 스트림을 만들 수 있습니다.
int[] list = { 4, 7, 3, 4 };
long count = IntStream.of(list).distinct().count();
원시타입은 IntStream, LongStream, DoubleStream 같은 전용 클래스 혹은 Arrays.stream 메서드를 이용하고, 나머지는 Stream.of 를 이용하여 Stream 으로 변환할 수 있습니다.
Stream.iterate() 로 무한수열을 만들 수 있습니다.
Stream<Integer> integers = Stream.iterate(0, n -> n+2).limit
여러개의 스트림을 단일 스트림으로 변환합니다.
아래는 n 과 n*n 으로 구성된 스트림을 만들고 flatMap 으로 하나의 스트림으로 결합합니다.
Stream.of(1, 2, 3).flatMap(n -> Stream.of(n, n*n)).forEach(System.out::println);
병행 스트림은 전체 스트림의 여러 파티션으로 나누어 다중 쓰레드로 처리합니다.
자바에서 입출력의 기본은 stream 으로, 정보의 생성 또는 소비를 추상화해줍니다.
입출력 stream 은 항상 물리적 장치와 연결되어있고, 프로그램과 장치간의 데이터 흐름을 처리해주는 객체입니다. (입력 스트림은 파일, 키보드, 소켓 등과 연결됩니다)
입출력 스트림은 크게 바이트 스트림, 문자 스트림으로 나뉩니다.

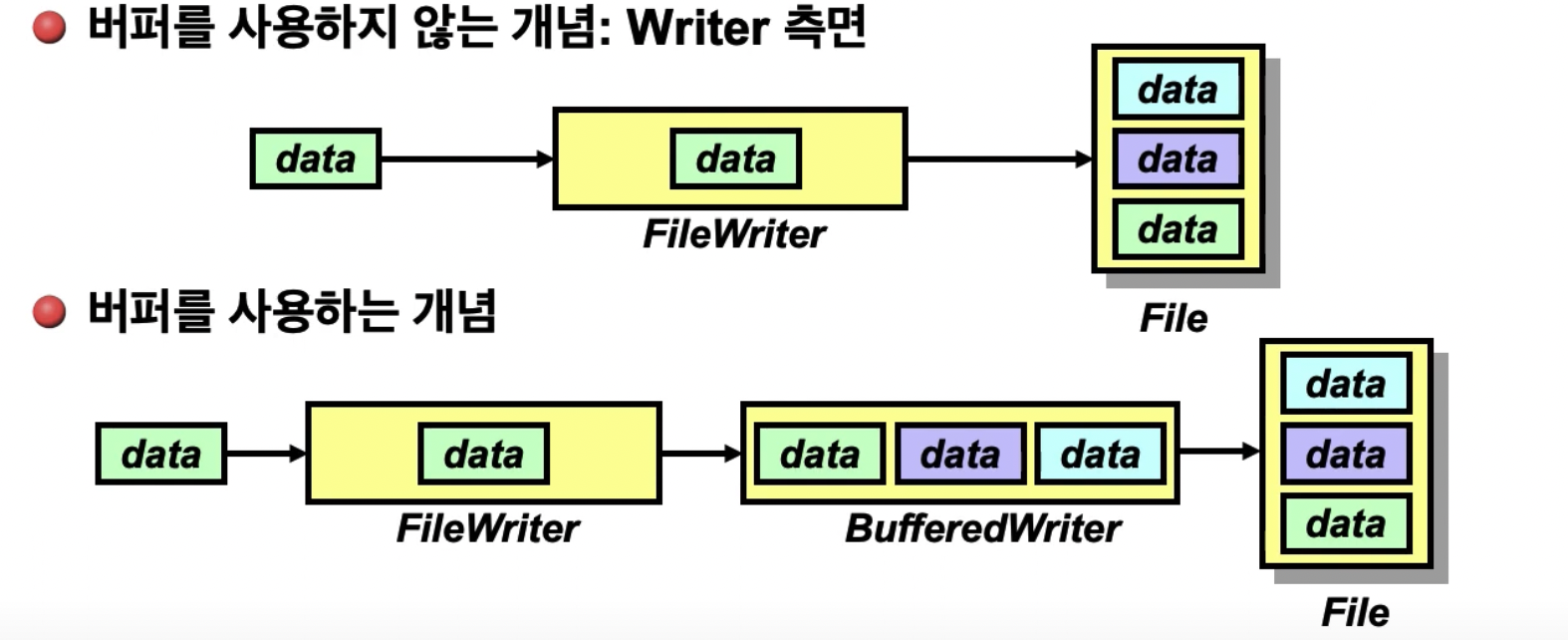
속도 향상을 위해 버퍼를 사용합니다.
meta-annotation 은 다른 annation 에서도 사용되는 annotation 의 경우를 말하며 custom-annotation 을 생성할 때 주로 사용됩니다.
@Target 은 Java compiler 가 annotation 이 어디에 적용될지 결정하기 위해 사용합니다.
@Target(ElementType.TYPE) 이 붙은 어노테이션은 타입 선언 시에 사용된다는 의미입니다.
ElementType.PACKAGE : 패키지 선언
ElementType.TYPE : 타입 선언
ElementType.ANNOTATION_TYPE : 어노테이션 타입 선언
ElementType.CONSTRUCTOR : 생성자 선언
ElementType.FIELD : 멤버 변수 선언
ElementType.LOCAL_VARIABLE : 지역 변수 선언
ElementType.METHOD : 메서드 선언
ElementType.PARAMETER : 전달인자 선언
ElementType.TYPE_PARAMETER : 전달인자 타입 선언
ElementType.TYPE_USE : 타입 선언
@Retetion 은 Annotation 이 실제로 적용되고 유지되는 범위를 의미합니다.
커스텀 애노테이션의 생성에서 해당 애노테이션이 선언된 대상(@Target의 속성값)의 메모리를 언제까지 유지 할 것인지 결정하는 애노테이션입니다.
RetentionPolicy.RUNTIME
RetentionPolicy.CLASS
RetentionPolicy.SOURCE
RetentionPolicy.RUNTIME 은 컴파일 이후에도 JVM 에 의해서 계속 참조가 가능합니다. 주로 리플렉션이나 로깅에 많이 사용됩니다.
RetentionPolicy.CLASS 은 컴파일러가 클래스를 참조할 때가지 유효합니다.
RetentionPolicy.SOURCE 은 컴파일 전까지만 유효합니다. 즉, 컴파일 이후에는 사라지게 됩니다.