数组是一种常用的数据结构,JavaScript支持原生的数组操作,并支持一些数组操作。详见JavaScript中内置的数组方法.
JavaScript中修改数组自身的方法:
- array.pop - 移除最后一个元素.
- array.push - 追加一个或多个元素.
- array.reverse - 数组翻转.
- array.shift - 移除第一个元素.
- array.sort - 排序.
- array.splice - 添加或着移除.
- array.unshift - 在数组前添加一个或多个元素.
JavaScript中数组的存取方法:
- array.concat - 将数组与数组或值合并.
- array.join - 只用指定的字符串将数组转为一个字符串.
- array.slice - 提取切片.
- array.indexOf - 找出指定元素的索引.
- array.lastIndexOf - 找出指定元素的最后一个索引.
JavaScript中数组的迭代方法:
- array.filter - 过滤.
- array.forEach - 对每个元素执行某个方法.
- array.every - 是否每个元素都符合给定的条件.
- array.map - 根据指定的操作对每个元素执行后返回一个新的数组.
- array.some - 是否存在符合某个条件的元素.
- array.reduce - 从左到右执行reduce操作并返回一个值.
- array.reduceRight - 从右到左执行reduce操作并返回一个值.
<script src="https://d3js.org/d3-array.v1.min.js"></script>
<script>
var min = d3.min(array);
</script>Methods for computing basic summary statistics.
# d3.min(array[, accessor]) <>
返回给定的array中的最小值。如果数组为空,则返回undefined。如果指定了accessor则相当于在计算最小值之前调用了array.map(accessor)
与内置方法Math.min不同,d3.min忽略undefined, null and NaN 等值,在忽略缺失数据时有用. 此外,元素使用自然排序而不是数值排序,比如["20","3"]会返回"20",而[20,3]则返回3.
# d3.max(array[, accessor]) <>
返回给定的array中的最大值。如果数组为空,则返回undefined。如果指定了accessor则相当于在计算最小值之前调用了array.map(accessor)
与内置方法Math.max不同,d3.min忽略undefined, null and NaN 等值,在忽略缺失数据时有用. 此外,元素使用自然排序而不是数值排序,比如["20","3"]会返回"3",而[20,3]则返回20.
# d3.extent(array[, accessor]) <>
根据指定的数组返回最小值 and 最大值.如果数组为空则返回[undefined, undefined]. 如果指定了accessor,则相当于在计算极值之前调用了array.map(accessor).
# d3.sum(array[, accessor]) <>
根据指定的array计算和. 如果数组为空则返回0.如果指定了accessor则相当于在求和之前调用了array.map(accessor). 这个方法会忽略undefined 和 NaN.
# d3.mean(array[, accessor]) <>
根据指定的数组返回数组的均值。如果数组为空则返回undefined.如果指定了accessor则相当于在计算之前调用了array.map(accessor). 这个方法会忽略undefined 和 NaN.
# d3.median(array[, accessor]) <>
根据指定的数组使用R-7 方法返回数组的中位数。如果数组为空则返回undefined.如果指定了accessor则相当于在计算之前调用了array.map(accessor). 这个方法会忽略undefined 和 NaN.
# d3.quantile(array, p[, accessor]) <>
根据指定的数组返回p-分位数, p 是 [0, 1]之间的小数. 例如中位数相当于 p = 0.5, 使用p = 0.25计算第一个四分位数, p = 0.75表示第三个四分位数. 这个方法也使用R-7 方法. 例如:
var a = [0, 10, 30];
d3.quantile(a, 0); // 0
d3.quantile(a, 0.5); // 10
d3.quantile(a, 1); // 30
d3.quantile(a, 0.25); // 5
d3.quantile(a, 0.75); // 20
d3.quantile(a, 0.1); // 2如果指定了accessor则相当于在计算之前调用了array.map(accessor)。
# d3.variance(array[, accessor]) <>
返回指定数组的无偏估计总方差 . 如果数组中包含的元素个数小于2则返回undefined.如果指定了accessor则相当于在计算之前调用了array.map(accessor). 这个方法忽略了undefined 和 NaN .
# d3.deviation(array[, accessor]) <>
返回数组的标准差,如果数组中包含的元素个数小于2则返回undefined.如果指定了accessor则相当于在计算之前调用了array.map(accessor). 这个方法忽略了undefined 和 NaN .
查找类方法.
# d3.scan(array[, comparator]) <>
对指定的数组进行线性扫描,根据指定的比较操作返回最终元素的索引。如果给定的数组不包含可比较的元素(比如比较操作返回NaN)则返回undefined,如果没有指定比较操作,则默认ascending. 例如:
var array = [{foo: 42}, {foo: 91}];
d3.scan(array, function(a, b) { return a.foo - b.foo; }); // 0
d3.scan(array, function(a, b) { return b.foo - a.foo; }); // 1这个方法与min类似,但是这个方法是使用比较操作而不是访问器,并且这个方法返回的是索引而不是具体的值。
# d3.bisectLeft(array, x[, lo[, hi]]) <>
返回x在数组中应该被插入的位置并保证数组的有序性。参数lo和hi被用来指定一个子集来限制插入的位置。默认情况下可能插入到数组中的任何位置. 如果数组中已经存在x,则插入点的位置位于这个已经存在的元素之前(要考虑从左到右还是从右到左)。
# d3.bisect(array, x[, lo[, hi]]) <>
# d3.bisectRight(array, x[, lo[, hi]]) <>
与bisectLeft类似, 但是插入点的位置是从右向左计算的.
# d3.bisector(accessor) <>
# d3.bisector(comparator) <>
使用指定的访问器或比较操作返回一个而等分线对象。例如有如下对象数组:
var data = [
{date: new Date(2011, 1, 1), value: 0.5},
{date: new Date(2011, 2, 1), value: 0.6},
{date: new Date(2011, 3, 1), value: 0.7},
{date: new Date(2011, 4, 1), value: 0.8}
];使用访问器造二等分线对象:
var bisectDate = d3.bisector(function(d) { return d.date; }).right;等价于使用比较操作器造二等分线对象:
var bisectDate = d3.bisector(function(d, x) { return d.date - x; }).right;要注意的是,使用比较操作时,要将第二个参数设置为x.
然后使用类似于bisectDate(data, new Date(2011, 1, 2))的方法返回索引。
# bisector.left(array, x[, lo[, hi]]) <>
等价于bisectLeft,但是使用的是二等分线定义时的访问操作.
# bisector.right(array, x[, lo[, hi]]) <>
等价于bisectRight, 但是使用的是二等分线定义时的访问操作.
如果a 小于 b则返回 -1 ,如果a 大于 b则返回1, 否则返回 0. 这是自然数的一个比较操作,可以用于array.sort来进行升序排序,定义如下:
function ascending(a, b) {
return a < b ? -1 : a > b ? 1 : a >= b ? 0 : NaN;
}如果a 小于 b则返回 1 ,如果a 大于 b则返回-1, 否则返回 0. 这是自然数的一个比较操作,可以用于array.sort来进行降序排序,定义如下:
function descending(a, b) {
return b < a ? -1 : b > a ? 1 : b >= a ? 0 : NaN;
}数组变换方法,返回新数组.
将指定的数组们合并为一个数组。这个方法与内置的concat方法有些像,但是当数组中嵌套另一个数组时会更方便:
d3.merge([[1], [2, 3]]); // returns [1, 2, 3]
[].concat([[1],[2,3]]); // [1,[2,3]]将给定的数组的每个元素与它之前的一个元素结合为一对,例如:
d3.pairs([1, 2, 3, 4]); // returns [[1, 2], [2, 3], [3, 4]]如果给定的数组中元素个数小于1,则返回空数组.
# d3.permute(array, indexes) <>
根据指定的索引次序对数组进行排列,返回排列后的新数组。比如d3.permute(["a", "b", "c"], [1, 2, 0]) 返回["b", "c", "a"]. 如果数组长度和索引长度不同,则会重复或忽略某些元素.
这个方法也可以对对象进行操作,第一个参数为对象,第二个参数为属性列表,则会根据属性列表返回对应的值数组,例如:
var object = {yield: 27, variety: "Manchuria", year: 1931, site: "University Farm"},
fields = ["site", "variety", "yield"];
d3.permute(object, fields); // returns ["University Farm", "Manchuria", 27]# d3.shuffle(array[, lo[, hi]]) <>
使用Fisher–Yates shuffle算法对数组进行随机重排.
# d3.ticks(start, stop, count) <>
在start和stop之间计算出一个等间隔的、精确的刻度序列,count用于指定参考刻度个数。由于小数可能并不精确,因此使用了d3-format进行了格式化。
# d3.tickStep(start, stop, count) <>
根据start和stop以及count返回刻度的间隔大小。
# d3.range([start, ]stop[, step]) <>
根据start(如果指定)和stop以及step(如果指定)返回生成的序列。start默认为0,step默认为1。返回的序列不包含stop.例如:
d3.range(0, 1, 0.2) // [0, 0.2, 0.4, 0.6000000000000001, 0.8]d3.range(0, 1, 1 / 49); // BAD: returns 50 elements!
d3.range(49).map(function(d) { return d / 49; }); // GOOD: returns 49 elements.数组重合并
d3.zip([1, 2], [3, 4]); // returns [[1, 3], [2, 4]]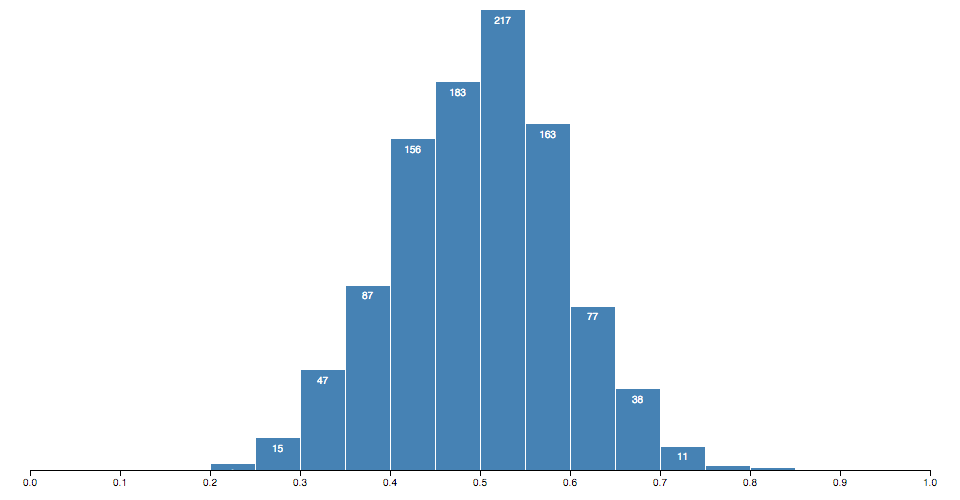
Histograms bin many discrete samples into a smaller number of consecutive, non-overlapping intervals. They are often used to visualize the distribution of numerical data.
使用默认的设置构建一个直方图生成器.
根据给定的数据样品计算对应的直方图。返回一个bins(纵向柱子)数组,每个bin都包含了与输入数据相关联的元素。bin的length属性表示这个bin里包含的元素个数,每个bin包含两个属性:
x0- bin的下界 (包含).x1- bin的上界 (不包含,最后一个bin除外).
如果指定了value,则为直方图设置值访问器并返回直方图生成器。如果value没有指定,则返回当前的值访问器。
当生成直方图时, 值访问器会在数据的每个元素上调用,并传递当前的元素 d, 索引 i, 以及原始数据 data . 默认的值访问器是假设输入数据是可以排序的(比如数值类型和日期类型),如果原始数据不能直接排序,则需要设置值访问器,并在访问器内部返回一个可排序的值。
# histogram.domain([domain]) <>
如果指定了domain则设置直方图的输入范围,这个值是一个[min,max]数组,表示直方图可取的最小值和最大值,如果生成的数据某个元素的值超出这个范围,则忽略这个元素。
例如,如果直方图与线性比例尺 x 结合使用时,则需要进行如下设置:
var histogram = d3.histogram()
.domain(x.domain())
.thresholds(x.ticks(20));然后使用如下方法计算bins:
var bins = histogram(numbers);domian访问器是被生成后的bins数组调用,而不是原始数据。
# histogram.thresholds([count]) <>
# histogram.thresholds([thresholds]) <>
如果指定了thresholds,则根据指定的数组或方法设置阈值生成器并返回直方图生成器。默认的阈值是使用Sturges’ formula方法. 阈值是以数组的形式定义的,比如 [x0, x1, …]. 任何比 x0 小的值被放置在第一个bin中。大于等于 x0 但是小于 x1 的被放置在第二个bin中; 以此类推. 最终直方图生成器 将包含 thresholds.length + 1 个 bins. 参考 histogram thresholds 获取更多信息.
如果使用 count 来代替 thresholds, 则 domain 将被分割成 count 个 bins; 参考 ticks.
这些方法一般不直接使用,而是传递给histogram.thresholds使用.
# d3.thresholdFreedmanDiaconis(values, min, max) <>
根据Freedman–Diaconis rule方法计算bins; values 必须为数值类型.
# d3.thresholdScott(values, min, max) <>
根据Scott’s normal reference rule方法计算bins; values 必须为数值类型.
# d3.thresholdSturges(values) <>
根据Sturges’ formula方法计算bins; values 必须为数值类型.