ShakeScript is a cutting-edge, AI-powered storytelling system designed to generate immersive, multi-episode narratives with rich characters, evolving plots, and long-term memory. By blending the strengths of GPT-4o and Google Gemini, it overcomes traditional limitations in AI storytelling—like token constraints and inconsistent narratives.
Traditional AI-generated stories often struggle with:
| Challenge | Description |
|---|---|
| 🔄 Narrative Coherence | Maintaining seamless connections between episodes |
| 🧠 Token Limitations | Handling restricted context windows in large language models |
| 👤 Character Consistency | Preserving character traits, relationships, and emotional states |
| 📚 Extended Narratives | Structuring long stories into coherent, episodic chunks |
| 💾 AI Memory Integration | Retaining relevant story context across episodes |
ShakeScript enables long-form storytelling with AI memory, human feedback integration, and cultural nuance.
- Accepts brief prompts (genre, trope, or plotline)
- Generates multi-episode stories with world-building and character arcs
- Maintains narrative continuity via metadata & embeddings
- Supports Hinglish storytelling
- Offers both AI-driven and human-in-the-loop episode refinement
- Uses a robust database + semantic embeddings for memory
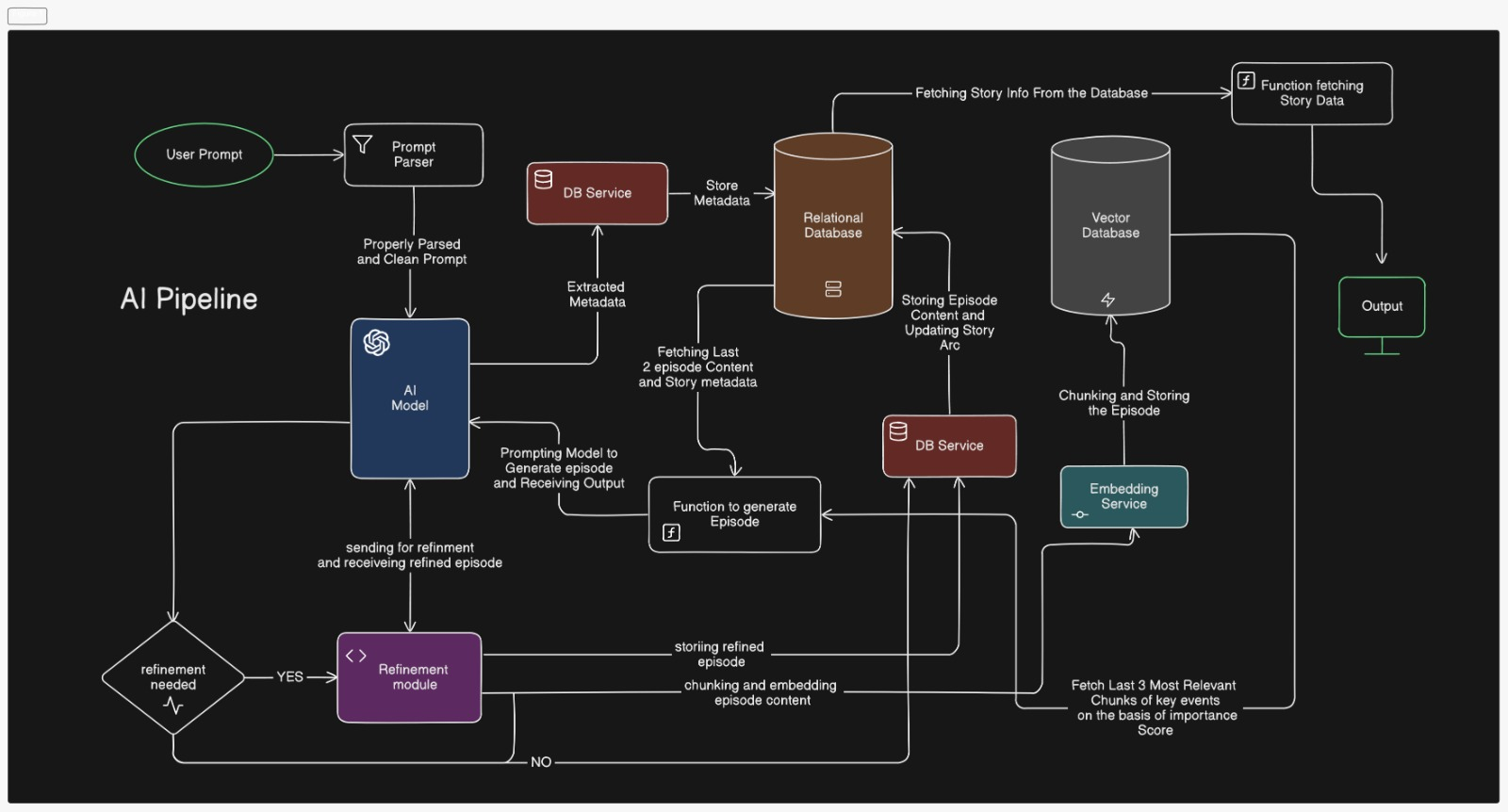
- Endpoint:
/stories - Gemini extracts:
- Characters: Names, roles, relationships, emotions
- Settings: Detailed location descriptions
- Structure: Exposition → Climax → Denouement
- Theme & Tone: (e.g., Suspenseful, Romantic)
- Data stored in Supabase:
stories,characterstables
- Uses structured metadata
- Generates the episode aligned to outline (e.g., Exposition)
- Retrieves up to 2-3 past episodes for context
- Embeddings fetch relevant content chunks for long-form continuity
- Ensures:
- Character consistency
- Thematic alignment
- Narrative progression
- Saves episode content, title, summary, emotion in
episodestable - Splits episode into semantic chunks using
SemanticSplitterNodeParser - Vectorizes & stores in
chunkstable
- Checks:
- Timeline alignment
- Character location/motivation consistency
- Dialogue and tone coherence
- Refines up to 3 times if inconsistencies found
- Users can refine via
/refine-batch - Gemini regenerates while preserving core elements
- Default batch size: 2 episodes
- Intermediate state stored in
current_episodes_content
- Tracks:
current_episodekey_events,timeline- Character evolution
- HuggingFace embeddings vectorize story chunks
- Relevance scored based on:
- Characters involved
- Episode order
- Enables memory-aware story generation
- Endpoints:
/stories– Create new story/generate-batch– Batch generate episodes/validate-batch– AI validation/refine-batch– Human feedback and refinement
- Uses Pydantic models for structure (
schemas.py)
- React/Next.js UI
- Features:
- Episode display
- Character profiles
- Hinglish support
- Real-time story updates
| Category | Technologies Used |
|---|---|
| AI & NLP | GPT-4o, Google Gemini, HuggingFace Embeddings |
| Backend | FastAPI, Pydantic, Asyncio |
| Database | Supabase (PostgreSQL) |
| Embeddings & Retrieval | LlamaIndex (SemanticSplitterNodeParser), Supabase Vector DB |
| Language | Python 3.13 with type hints |
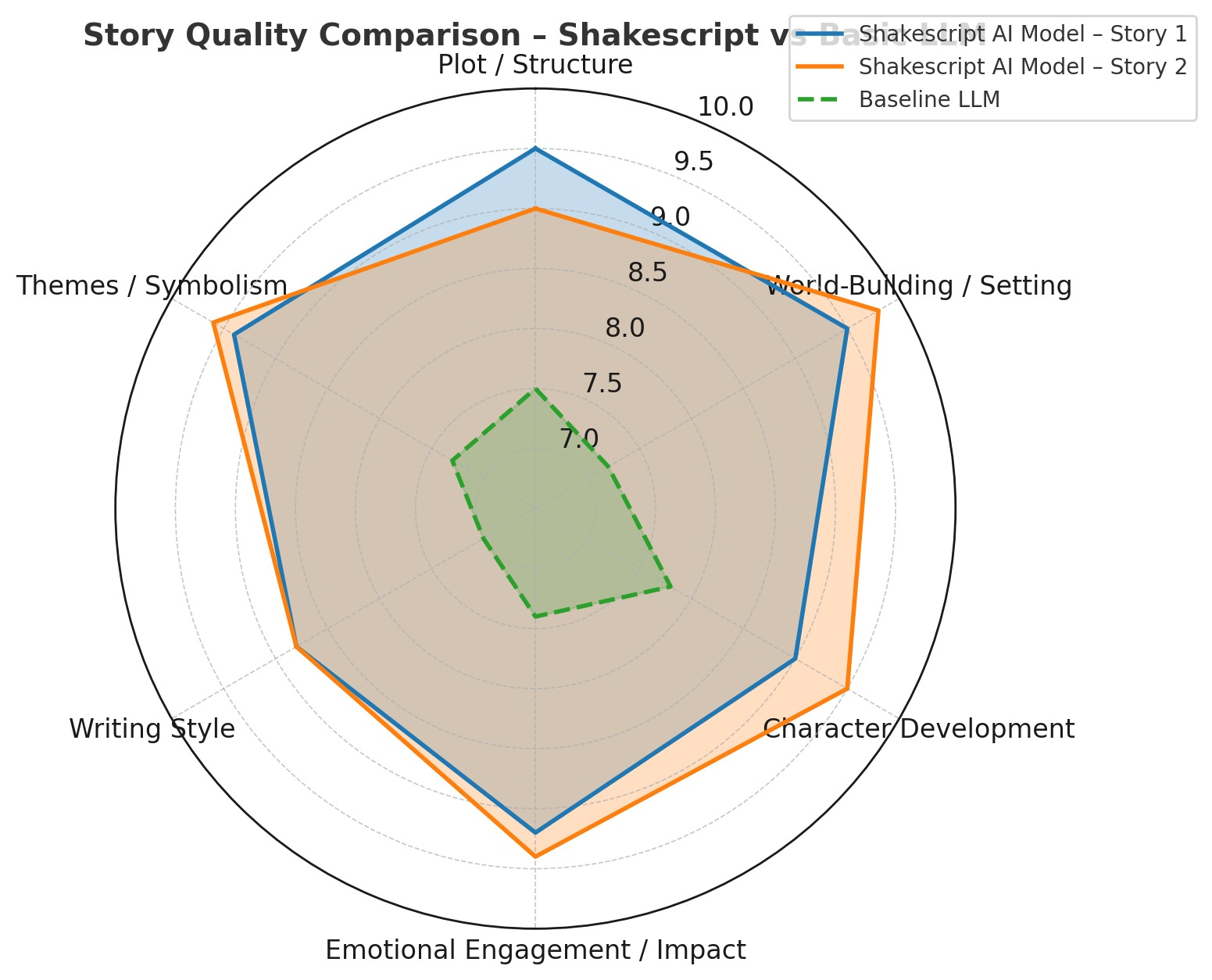
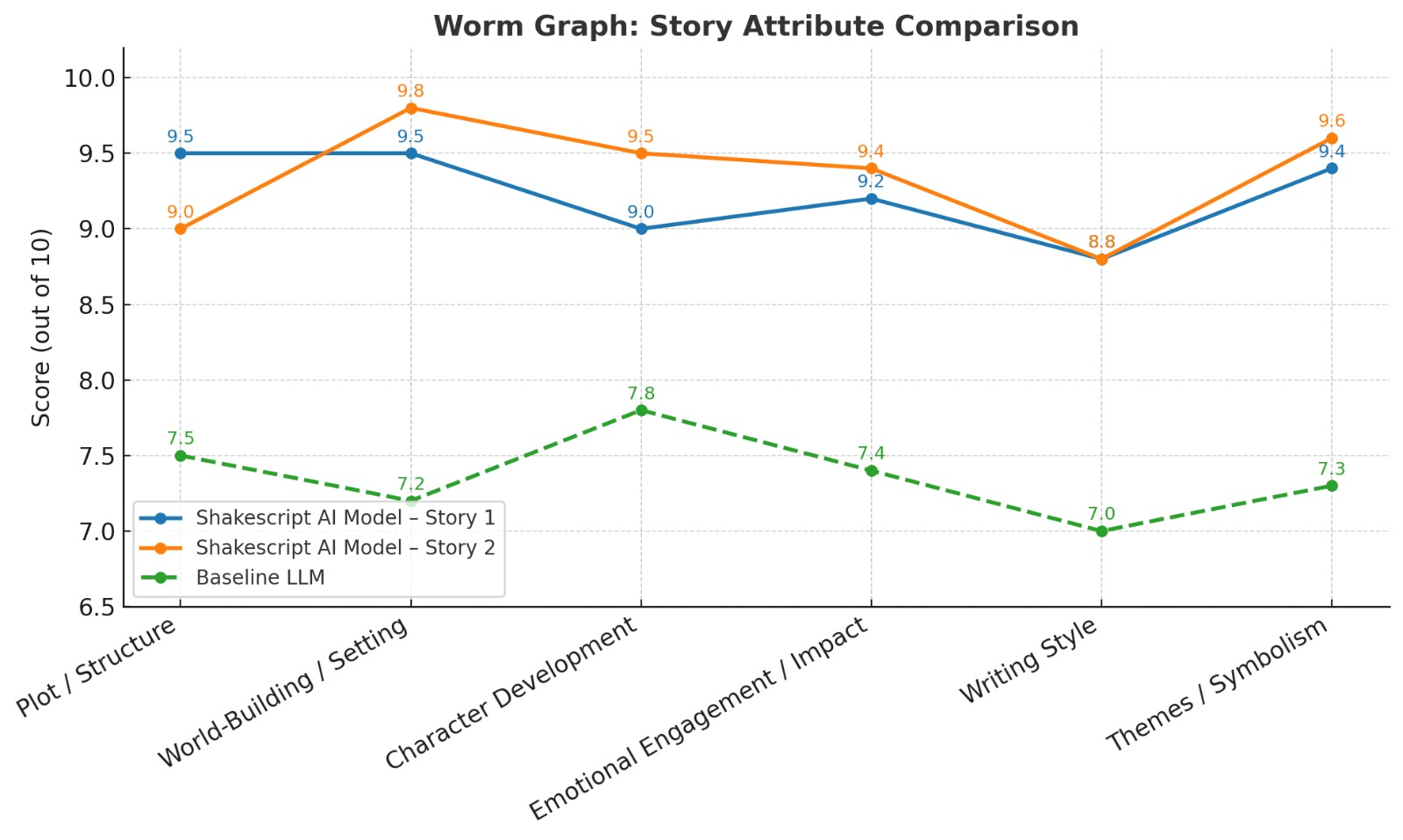
- 🏆 Multi-Episode Consistency – Maintains coherent, evolving narratives
- 💡 Token Limit Workaround – Smart retrieval with embeddings
- 👤 Character Evolution – Tracks traits, arcs, and relationships
- 🔁 AI + Human Refinement – Combines LLM polish with user feedback
- 🌍 Hinglish Support – Culturally tuned storytelling
| Feature | Description |
|---|---|
| 🎮 Interactive Storylines | Let users influence story direction via input parameters |
| 🎧 TTS Narration | Audio playback support with Text-to-Speech |
| 🧠 Custom AI Models | Fine-tune LLMs for specific genres or styles |
| 📱 Frontend UI | Responsive, real-time React/Next.js interface |
| 🔍 Smart Retrieval | Advanced hybrid/cosine similarity chunk search |
ShakeScript redefines AI-powered storytelling by:
- Solving token limitation challenges
- Supporting long-form, culturally nuanced storytelling
- Seamlessly blending LLMs, embeddings, and human input
🎉 Let the stories unfold — with ShakeScript, your narrative has no limits.