CSS权重计算
A selector’s specificity is calculated as follows:
一个选择器的权重计算依据下面规则:
- count 1 if the declaration is from is a ‘style’ attribute rather than a rule with a selector, 0 otherwise (= a) (In HTML, values of an element’s “style” attribute are style sheet rules. These rules have no selectors, so a=1, b=0, c=0, and d=0.)
- count the number of ID attributes in the selector (= b)
- count the number of other attributes and pseudo-classes in the selector (= c)
- count the number of element names and pseudo-elements in the selector (= d)
- The specificity is based only on the form of the selector. In particular, a selector of the form “[id=p33]” is counted as an attribute selector (a=0, b=0, c=1, d=0), even if the id attribute is defined as an “ID” in the source document’s DTD.
Concatenating the four numbers a-b-c-d (in a number system with a large base) gives the specificity.
- 如果声明是“style”属性而不是带有选择器的规则, 计数1,否则为计数0(= a)(在HTML中,元素的“样式”属性的值是样式表规则)。这些规则没有选择器,所以a=1,b=0,c=0,d=0。
- 在选择器中计数ID属性的数目 (= b)
- 在选择器中计数其他属性和伪类的数目 (= c)
- 在选择器中计算元素名称和伪元素的数目 (= d)
- 特异性仅基于选择器的形式。特别地,将形式“[id= p33”]的选择器作为属性选择器(a=0,b=0,c=1,d=0)计数,即使id属性被定义为源文档DTD中的“id”。
注意 1 :这里的 (= n) 这个代表的含义是 将统计出来的数目用 n 来表示, 那这里,在一组(一组指的是我们写的复合选择器)选择器里,a就是style属性是否存在(存在为a=1,不存在a=0),b就是id选择器的数目,c就是属性和伪类的数目,d就是元素和伪元素的数目.
注意 2 :通用选择器(*),子选择器(>)和相邻同胞选择器(+)并不在这四个等级中,所以他们的权值都为0。
将四个数字a-b-c-d(在一个有大小关系的数字系统中)连接起来给出了特殊性。 再解释下:将这四个数字连起来,并放入一个有大小关系的数字系统中,其值就代表了这条选择器的权重。
请看下面例子:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
有人总结说: a的权重是1000,b是100, c是10, d是1。 然后 得出 a1000 + b100 + c10 + d1 这样算出的值,我们来测试下
请看如下测试:
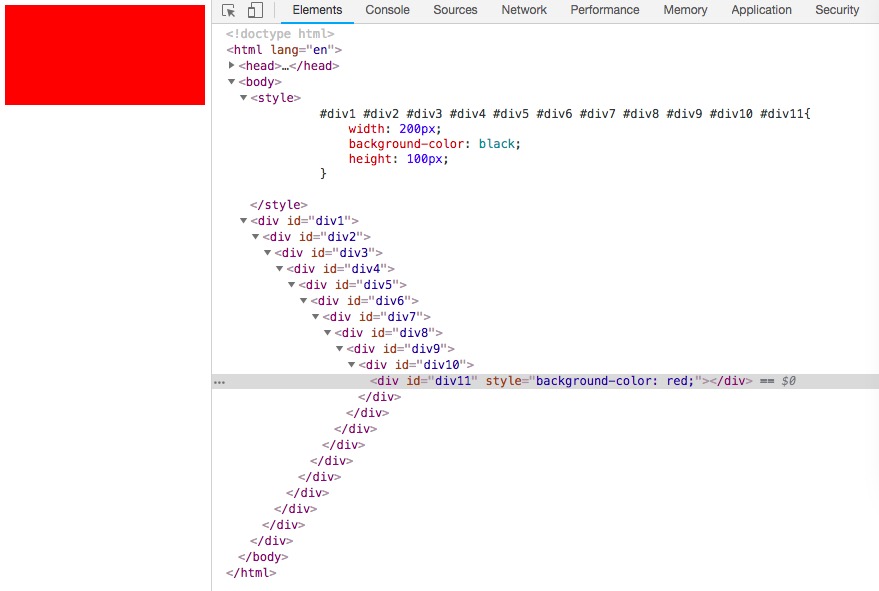
#div11 应用了11个id选择器,一个style属性,按照上述计算:11 * 100 > 1000 * 1 应该id选择器生效,
但是最后生效的样式仍然使style属性,所以这个权重系统的假设并不正确,而这个权重系统的判断规则应是如下规则,
规则1 a1-b1-c1-d1
规则2 a2-b2-c2-d2
if a1 > a2 规则1生效
if b1 > b2 规则1生效
if c1 > c2 规则1生效
if d1 > d2 规则1生效
另外注意的是:
!important的使用始终高于其他规则;- 俩条都有!important时,还是依据上述规则。
http://www.snook.ca/archives/html_and_css/understanding_c/,其中说到解决权重快速的方法是**避免使用`!important`**, 所以你要是不想给自己找麻烦,就不要使用!important。
原文链接:https://yatoo2018.github.io/Yatoo/2018/07/31/CSS-Cascade.html
CSS权重计算
A selector’s specificity is calculated as follows:
一个选择器的权重计算依据下面规则:
Concatenating the four numbers a-b-c-d (in a number system with a large base) gives the specificity.
注意 1 :这里的 (= n) 这个代表的含义是 将统计出来的数目用 n 来表示, 那这里,在一组(一组指的是我们写的复合选择器)选择器里,a就是style属性是否存在(存在为a=1,不存在a=0),b就是id选择器的数目,c就是属性和伪类的数目,d就是元素和伪元素的数目.
注意 2 :通用选择器(*),子选择器(>)和相邻同胞选择器(+)并不在这四个等级中,所以他们的权值都为0。
将四个数字a-b-c-d(在一个有大小关系的数字系统中)连接起来给出了特殊性。 再解释下:将这四个数字连起来,并放入一个有大小关系的数字系统中,其值就代表了这条选择器的权重。
请看下面例子:
有人总结说: a的权重是1000,b是100, c是10, d是1。 然后 得出 a1000 + b100 + c10 + d1 这样算出的值,我们来测试下
请看如下测试:

#div11 应用了11个id选择器,一个style属性,按照上述计算:11 * 100 > 1000 * 1 应该id选择器生效,
但是最后生效的样式仍然使style属性,所以这个权重系统的假设并不正确,而这个权重系统的判断规则应是如下规则,
另外注意的是:
!important的使用始终高于其他规则;http://www.snook.ca/archives/html_and_css/understanding_c/,其中说到解决权重快速的方法是**避免使用`!important`**, 所以你要是不想给自己找麻烦,就不要使用
!important。