sycl::double2 type degrades sycl performance on NV GPU with additional generated memory instructions #6583
Description
Describe the bug
sycl::double2 type passed to a kernel function significantly degrades sycl performance on NV GPU with numerous, additional generated memory instructions compared to CUDA implementation baseline
Description
- CUDA SDK Blackscholes vs. DPCT migrated SYCL Blackscholes. Both run on NV GPU (A100)
- DPCT migrated SYCL performance on NV GPU is more than 50% worse than baseline CUDA version (CUDA: 53 Goptions/s vs. SYCL: 22 Goptions/s)
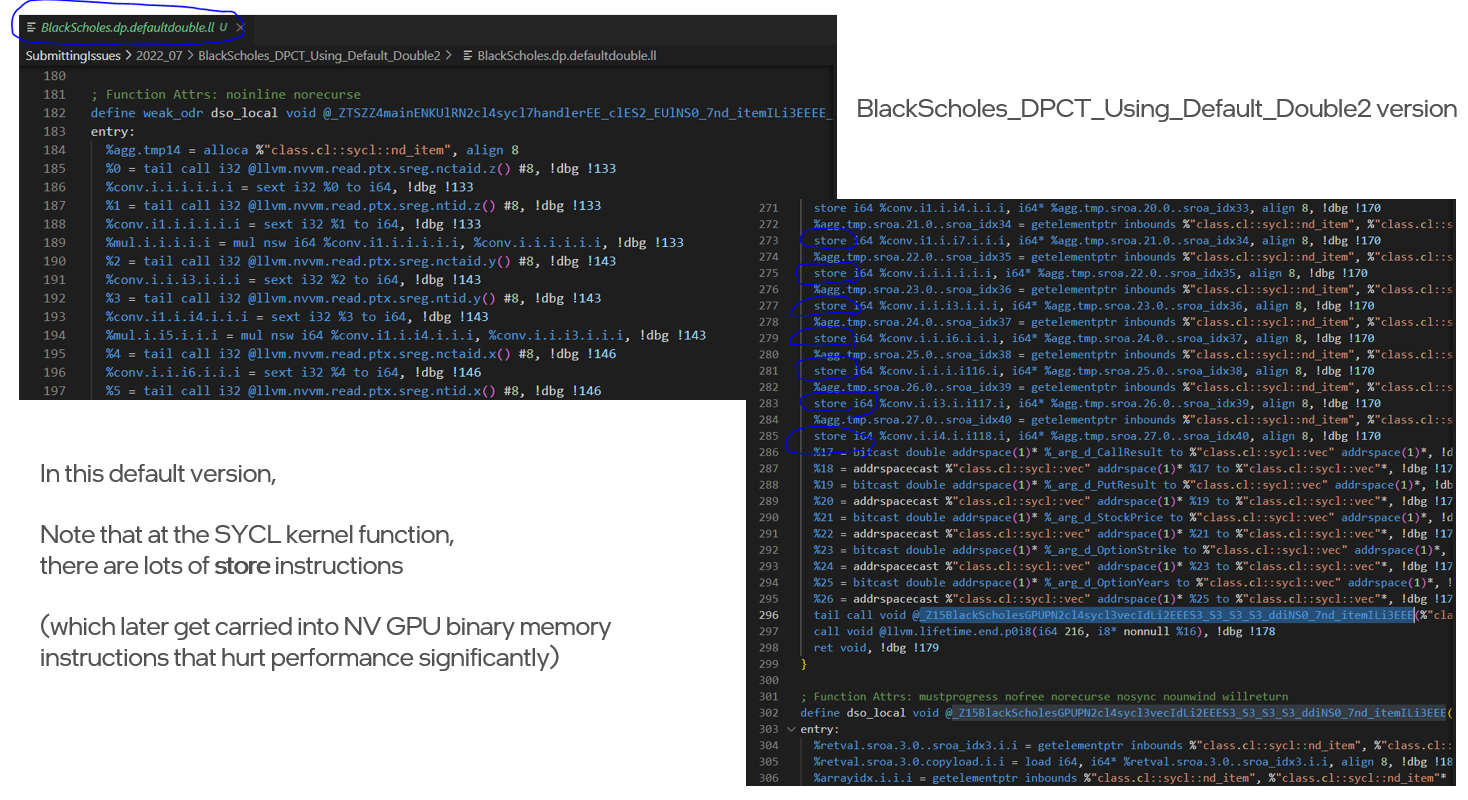
- [Discovered reason] using sycl::double2 generates lots of additional memory instructions in LLVM IR, which then get carried into final NV binary (more details below), that degrades performance significantly
- [Discovered workaround] Insert
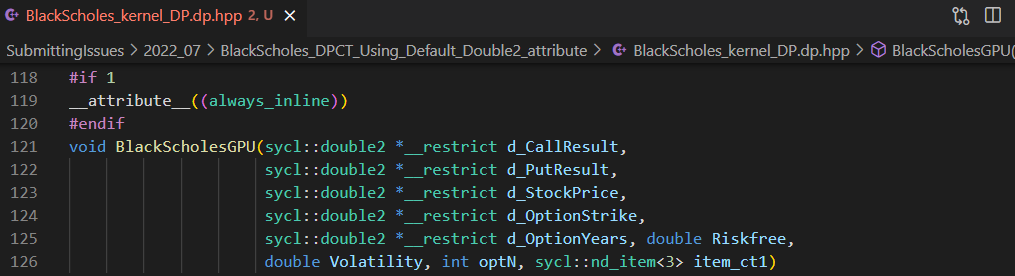
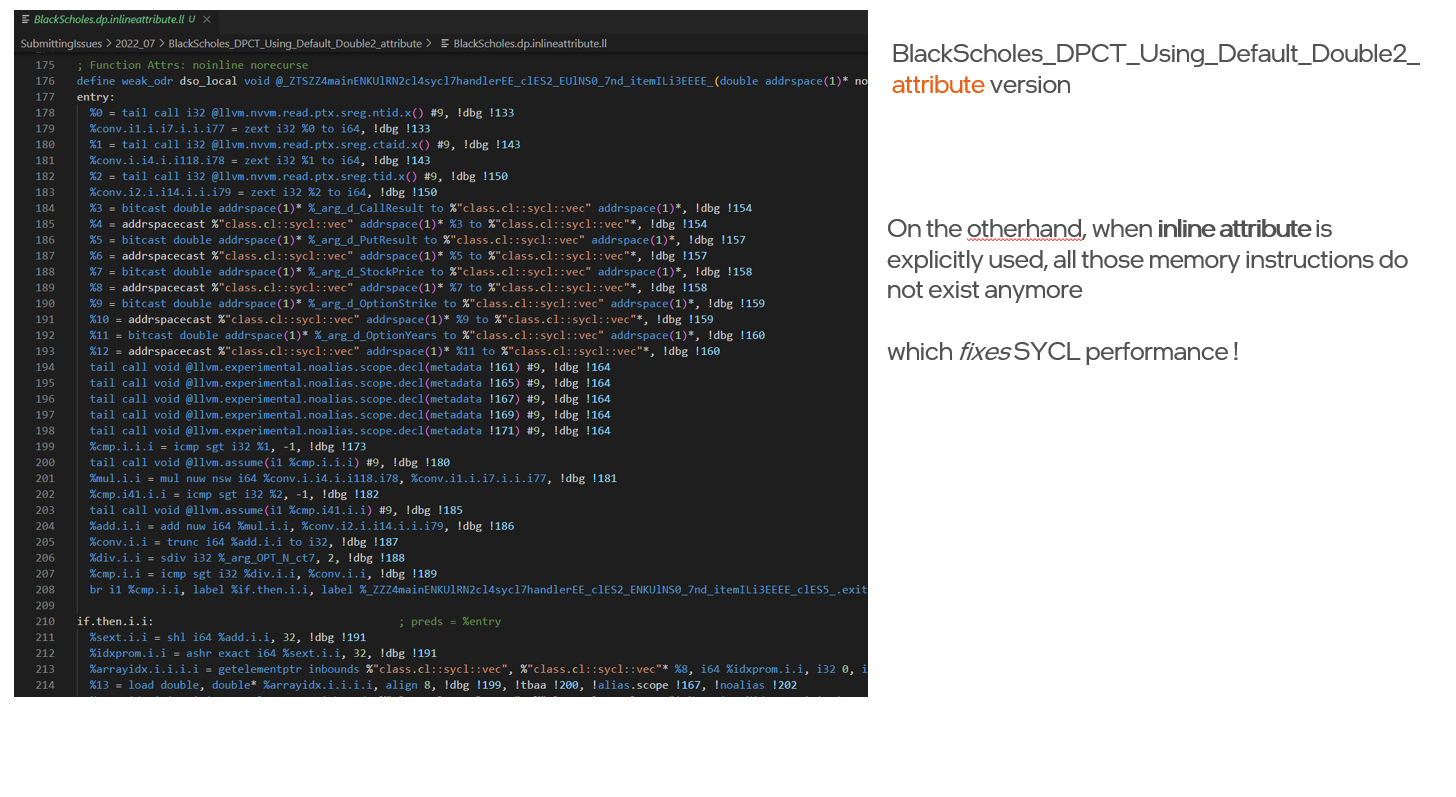
__attribute__((always_inline))before the sycl kernel function. Then SYCL performance matches with CUDA implementation - [What needs to be done] For the PTX backend needs to optimize the additional memory instructions (without user having to put the inline keyword). and/or use the optimized LLVM IR in the first place
To Reproduce
git clone https://github.com/sphblue/BlackScholes_From_CUDA_SDK_Samples_PublicVersion.git
Default DPCT migrated sycl version
cd BlackScholes_DPCT_Using_Default_Double2
clang++ -O2 -gline-tables-only -fsycl -fsycl-unnamed-lambda -fsycl-targets=nvptx64-nvidia-cuda *.cpp -I/opt/intel/oneapi/dpcpp-ct/latest/include -o BlackScholes.dpct.nvgpu
./BlackScholes.dpct.nvgpu
Fixed sycl version (with inline keyword)
cd BlackScholes_DPCT_Using_Default_Double2_attribute
clang++ -O2 -gline-tables-only -fsycl -fsycl-unnamed-lambda -fsycl-targets=nvptx64-nvidia-cuda *.cpp -I/opt/intel/oneapi/dpcpp-ct/latest/include -o BlackScholes.dpct.nvgpu.inlineattribute
Baseline cuda version (for reference, not needed for this issue)
cd BlackScholes_CUDA_Using_Default_Double2
make
Code
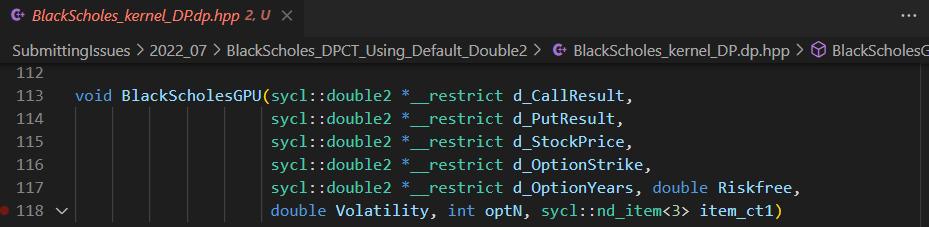
Default DPCT migrated SYCL
SYCL with inline attribute manually inserted
Performance Outputs
Baseline CUDA: 54854 goptions / s
Default DPCT migrated SYCL: 22137 goptions / s
Fixed inline attribute SYCL: 53898 goptions / s
LLVM IR
Default DPCT migrated SYCL
Workaround version, inline attribute SYCL
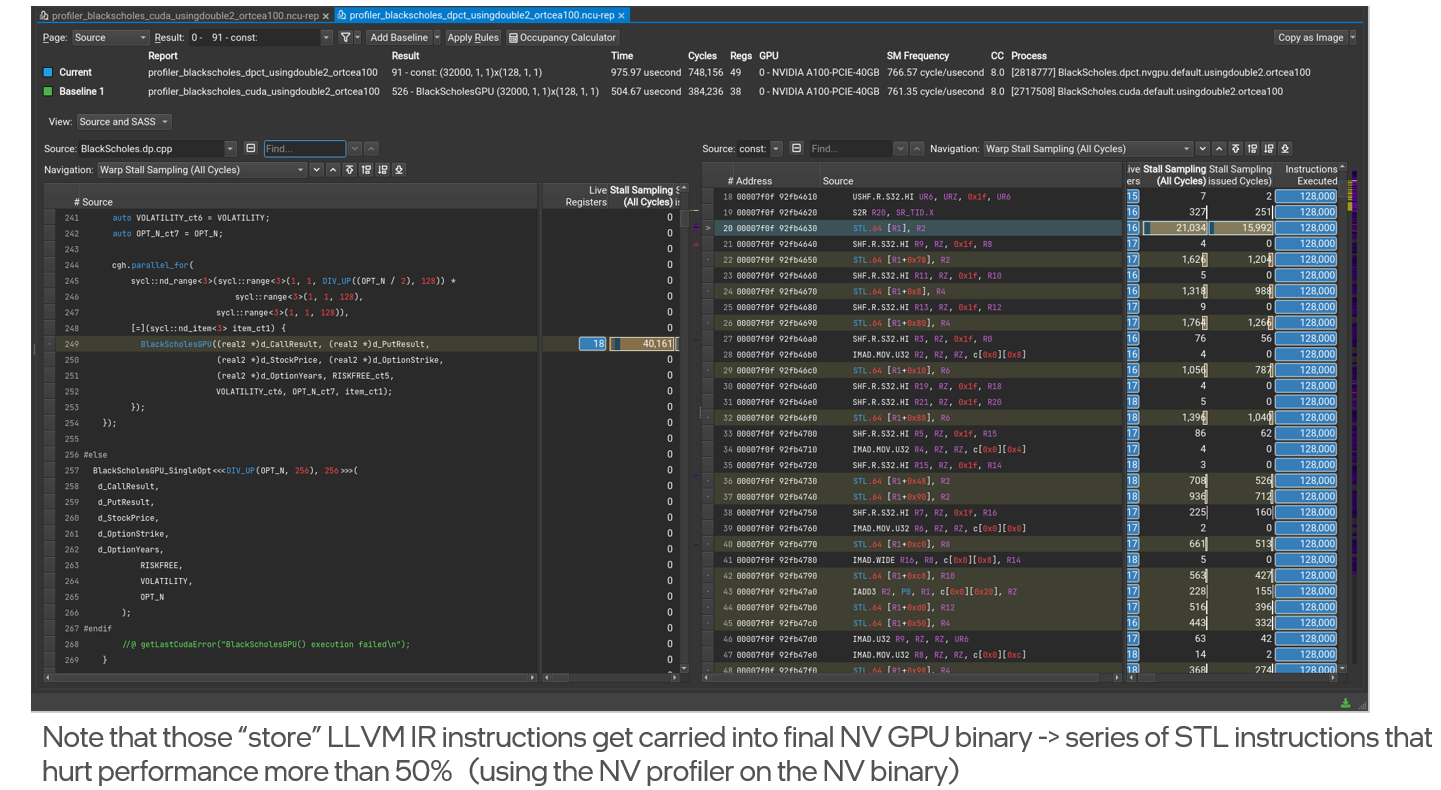
Using Nvidia profiler
Using the Nvidia profiler shows that all those extra memory instructions that were in LLVM IR got carried into final NV binary
Environment (please complete the following information):
- OS: Ubuntu 22.04
- Target device and vendor: NVidia A100
- DPC++ version: clang version 16.0.0
- Dependencies version: Using A100, normal config
Additional context
I believe that it's not only SYCL's double2 type (sycl::double2 is coming from CUDA's double2 type during dpct migration)
CUDA workloads often use double2, double4, ... when user migrates those cuda workloads, then I expect there will be performance degradation of sycl on NV GPU due to those extra memory instructions