-
Marca/modelo: Nitro AN515-51
-
Tipo: Notebook
-
Año adquisición: 2018
-
Procesador:
- Marca/Modelo: Intel Core i7-7700HQ
- Velocidad Base: 2.80 GHz
- Velocidad Máxima: 2.81 GHz
- Numero de núcleos: 4
- Numero de hilos: 8
- Arquitectura: x64
- Set de instrucciones (Intel): MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, EM64T, VT-x, AES, AVX, AVX2, FMA3
-
Tamaño de las cachés del procesador
- L1d: 32KB
- L1i: 32KB
- L2: 256KB
- L3: 6MB
-
Memoria
- Total: 16 GB
- Tipo memoria: DDR4
- Velocidad: 3490 MHz
- Numero de SODIMM: 4
-
Tarjeta Gráfica
- Marca / Modelo: Nvidia GeForce GTX 1050
- Memoria dedicada: 4 GB
- Resolución: 1920 x 1080
-
Disco 1:
- Marca: WDC WD10SPZX-21Z10T0
- Tipo: Disco duro fijo
- Tamaño: 931.5 GB
- Particiones: 1
- Sistema de archivos: NTFS
-
Disco 2:
- Marca: Toshiba THNSNK256GVN8
- Tipo: Disco duro fijo
- Tamaño: 240 GB
- Particiones: 3
- Sistema de archivos: NTFS
-
Dirección MAC de la tarjeta wifi: 70:C9:4E:71:99:A3
-
Dirección IP (Interna, del router): 192.168.2.227
-
Dirección IP (Externa, del ISP): 190.153.135.134
-
Proveedor internet: GTD Manquehue S.A.
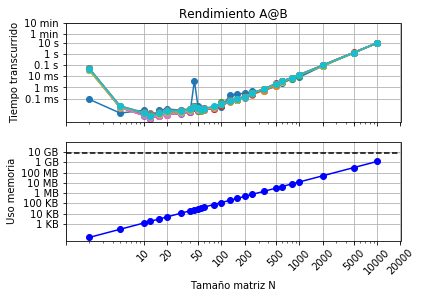
- ¿Cómo difiere del gráfico del profesor/ayudante?
R: Las curvas de los gráficos difieren, ya que en mi caso se utilizaron los datos en el archivo rendimiento.txt pero en el caso del profesor/ayudante, se usaron otros datos. Esto implica que los gráficos de tiempo transcurrido vs tamaño matriz y uso memoria vs tamaño matriz serán distintas. A pesar de esto, se puede ver que los gráficos del profesor/ayudante y los mios tienen un comportamiento bastante similar. Para el uso de la memoria ambas curvas son lineales, y para el tiempo transcurrido los valores varian notoriamente entre corridas a menor tamaño de matriz, pero a medida que aumenta el tamaño de la matriz, el tiempo transcurrido tiene un comportamiento casi lineal (se puede ver que las curvas de las 10 corridas comienzan a traslaparse cuando N es mayor a 500.
- ¿A qué se pueden deber las diferencias en cada corrida?
R: Para el uso de la memoria, se obtienen los mismos valores para todas las corridas y tiene un comportamiento lineal, pero en el caso del tiempo transcurrido, se puede ver claramente que los datos varian notoriamente en cada corrida. Esto último se debe a que cada proceso tiene su contador de programa, registros y variables, por lo que el tiempo en realizar operaciones puede variar ligeramente en el caso de sistemas operativos de varios thread. Se puede notar esto último en el gráfico, ya que a menor tamaño de matriz el tiempo varía notoriamente entre cada corrida. A diferencia de esto último, cuando el tamaño de la matriz es muy grande, cada corrida tendrá un tiempo transcurrido similar porque el proceso de multiplicar de matrices grandes se demora, entonces al variar ligeramente el tiempo, no se notará. Ejemplo: imaginemos que en cada corrida, al realizar el MATMUL el tiempo transcurrido varía en 0.1 ms. Este valor será muy notorio para las primeras operaciones que se demoran menos de 1 ms, pero al usar MATMUL con matrices grandes, el proceso se demora segundos, por lo que variar 1 ms no se notará.
- El gráfico de uso de memoria es lineal con el tamaño de matriz, pero el de tiempo transcurrido no lo es ¿porqué puede ser?
R: Esto se debe principalmente a que, a diferencia del uso de memoria que es un proceso lineal, el tiempo transcurrido es exponencial. Esto significa que a medida que se aumenta el tamaño de la matriz, el tiempo transcurrido aumenta exponencialmente. Por esto, en mi computador, multiplicar matrices del orden N=10, es practicamente instantaneo, pero al multiplicar matrices de N=10000, puede demorarse minutos (dependiendo de la corrida). Esto ocurre debido a que para multiplicar matrices, se usa un algoritmo de complejidad computacional O(n^3) o si se usa el algoritmo de Volker Strassen tiene una complejidad computacional de O(n^2.8074) o O(n^2.3728596) si se usa el algoritmo por Josh Alman. En cualquiera de estos casos, se puede notar que a medida que se aumenta el tamaño de la matriz, el tiempo en hacer un MATMUL de esas matrices, aumentará exponencialmente. Ejemplo: La capacidad RAM disponible de mi computador es alrededor de 7.5 GB, y puede soportar máximo una matriz de N=25000. El tiempo transcurrido para hacer esta matriz fue de 850 segundos, lo cual es mucho más tiempo que hacer una matriz de N=10000 se demora solamente 30 segundos en algunos casos. Claramente se puede ver que el tiempo transcurrido es exponencial dependiendo del tamaño de la matriz.
- ¿Qué versión de python está usando?
R: 3.6.5
- ¿Qué versión de numpy está usando?
R: 1.14.3
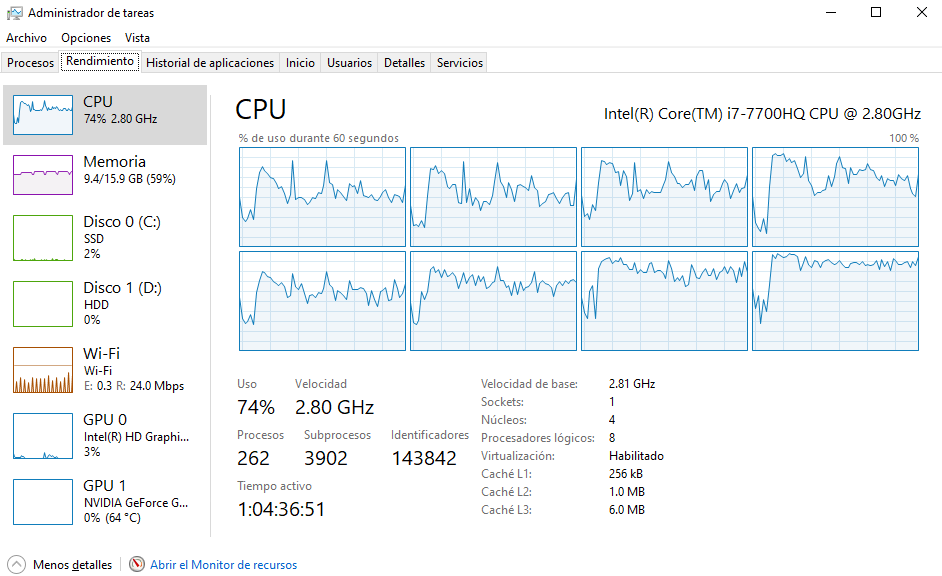
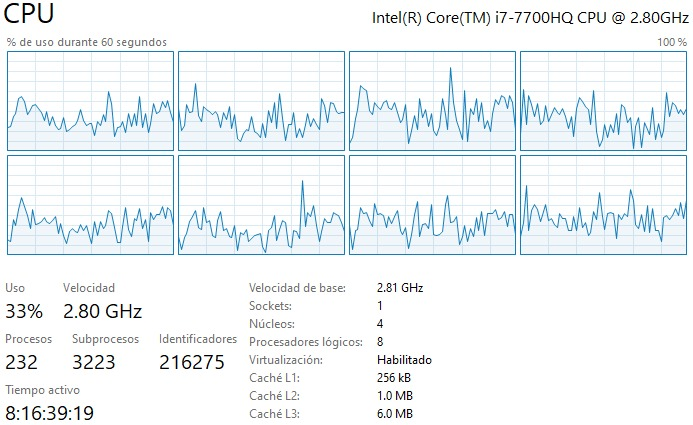
- Durante la ejecución de su código ¿se utiliza más de un procesador? Muestre una imagen (screenshot) de su uso de procesador durante alguna corrida para confirmar.
R: Durante la ejecición del código se usan los 4 núcleos y 8 procesadores lógicos disponibles. Eso se debe principalmente a que NumPy hace una paralelización automática al correr el código, por lo que se usan múltiples procesadores simultáneamente.
Observaciones:
- NumPy: np.half y np.longdouble no son soportados por numpy.linalg.inv para mi versión de Python, por lo que no se entregan archivos de estos para NumPy (caso 1).


- SciPy: np.half entrega un valor mayor (recibe un buff a single) a np.single, esto se debe principalmente a que al usar la función INV de SciPy puede usar más memoria para este proceso. Además, np.double y np.longdouble (recibe un nerf a double) entregan la misma cantidad de bits para mi versión de Python, por lo que no se entregan un archivos para np.longdouble en SciPy (caso 2 y caso 3). Esto último se debe a que Python 3 usa 64 bits, tal como se ve a continuación:

- Otros: para usar el código de visualización es necesario que el usuario ingrese el nombre del archivo.txt deseado. Por ejemplo, si se quiere ver el desempeño para el caso 2 usando np.single se ingresa lo siguiente: rendimiento_caso_2_single (se puede poner el archivo con ".txt" o no, el código acepta ambos casos).
Comentarios:
- Se puede notar que Overwrite_a = True mejora levemente el tiempo en realizar la función INV, sin embargo, no afecta a la cantidad de bytes generado al realizar dicha función.
- Se puede notar que usar SciPy en vez de NumPy mejora significativamente el tiempo en realizar la función INV, sin embargo, no afecta a la cantidad de bytes generado al realizar dicha función. Esto se debe a que SciPy contiene una mayor cantidad de funciones que NumPy, por lo que se calcula la matriz inversa de manera más eficiente que NumPy.
- Np.half es un float16 (no soportado por numpy), np.single es un float32 (4 bytes), np.double es un float64 (8 bytes) y np.longdouble es un float128 (8 bytes debido a que Python trabaja con un máximo de 64 bits).
- ¿Qué algoritmo de inversión cree que utiliza cada método (ver wiki)? Justifique claramente su respuesta.
R: Numpy.linalg.inv(MatrizNxN) en realidad llama a numpy.linalg.solve(MatrizNxN, I), donde I es la identidad, y solve usa la factorización LU de Lapack. Por el otro lado, SciPy está construido utilizando las bibliotecas optimizadas Atlas, Lapack y Blas, tiene capacidades de álgebra lineal muy rápidas. Por esto se puede ver, en los archivos entregados, que SciPy requiere menos tiempo para invertir una matriz que NumPy. Finalmente, implementar Overwrite_a = True a scipy.linalg.inv() hace que la memoria utilizada en calcular la inversa de la matriz, se sobreescriba en la memoria en lugar de crear la matriz de 0. Esto último sucede al tener Overwrite_a = False, lo cual es la opción default de SciPy. Debido a esto, se puede esperar que usar Overwrite_a = True disminuya el tiempo en invertir una matriz.
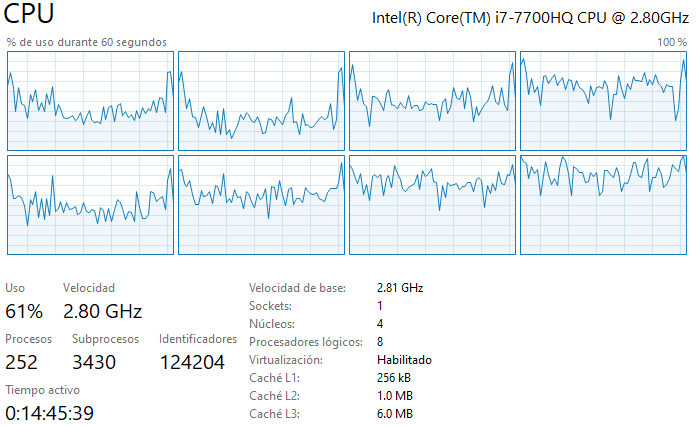
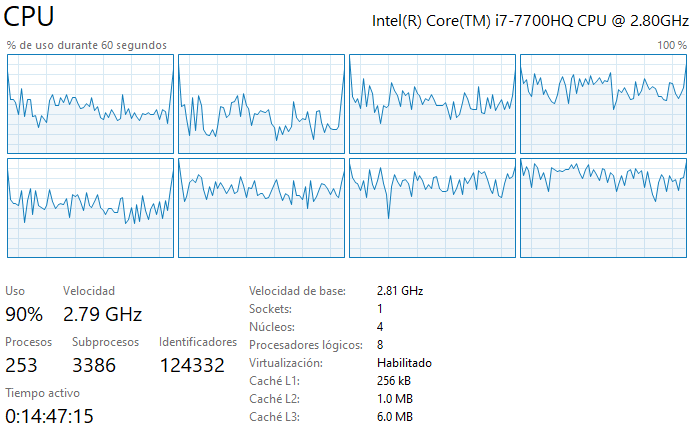
- ¿Como incide el paralelismo y la estructura de caché de su procesador en el desempeño en cada caso? Justifique su comentario en base al uso de procesadores y memoria observado durante las corridas.
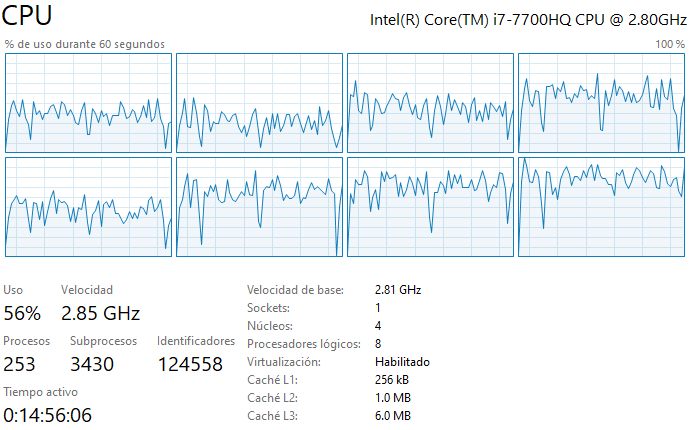
R: Durante la ejecición del código se usan los 4 núcleos y 8 procesadores lógicos disponibles (esto se aplica a todos los casos solicitados, ver imagenes). Eso se debe principalmente a que NumPy y SciPy hacen una paralelización automática al correr el código, por lo que se usan múltiples procesadores simultáneamente. Se puede además mencionar que, usar NumPy o SciPy no influye en la memoria utilizada al calcular la matriz inversa, a modo de ejemplo, la memoria de rendimiento_caso_1_double es igual a la memoria de rendimiento_caso_3_double. Esto último se debe a que las librerias NumPy o SciPy no cambiaran la cantidad de bytes usando los distintos métodos, lo que sucede es que las librerias no pueden manejar algunos FPU (floating point unit), por ejemplo en mi caso, NumPy no puede invertir una matriz float16 pero SciPy si puede. Finalmente, se puede observar que el código adjunto en el repositorio no es eficiente, para hacer que el código sea eficiente sería bueno almacenar información en el caché de matrices previamente calculadas para facilitar el cálculo de matrices más complejas. Esto puede reducir significativamente el tiempo de ejecución del código.
Caso 1 Single:
Caso 1 Double:
Caso 2 Half:
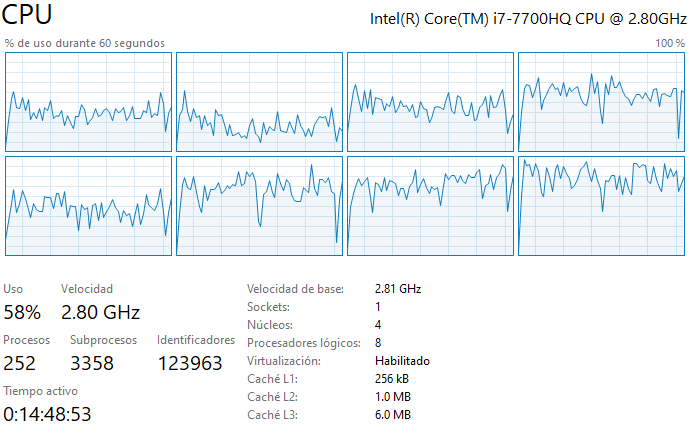
Caso 2 Single:
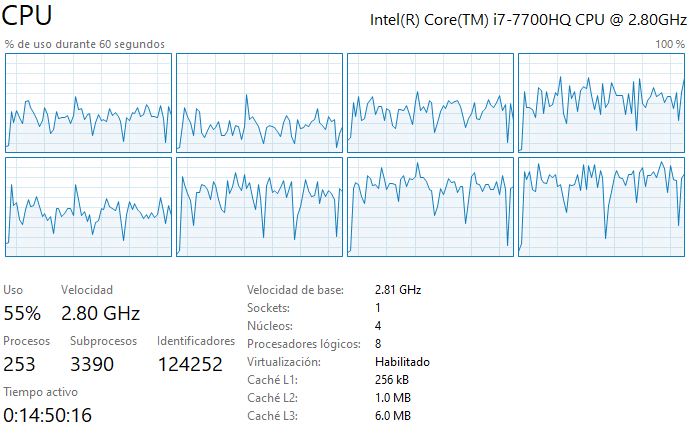
Caso 2 Double:
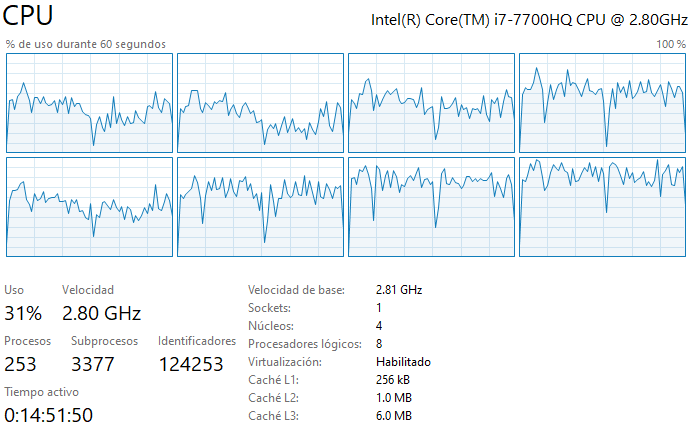
Caso 3 Half:
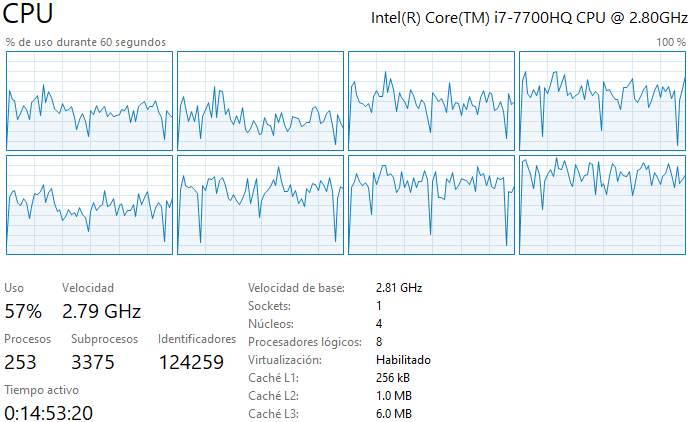
Caso 3 Single:
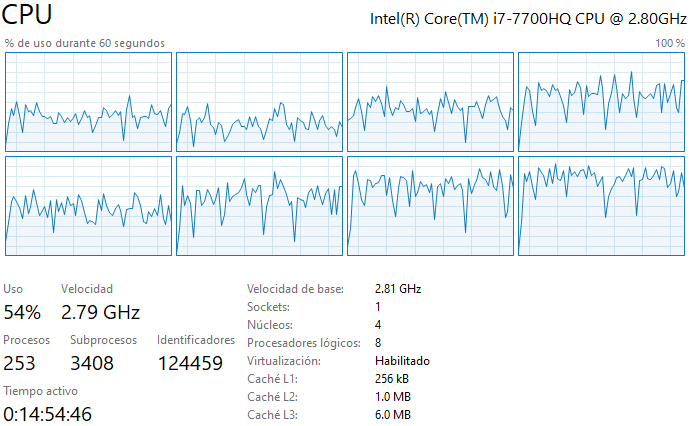
Caso 3 Double:
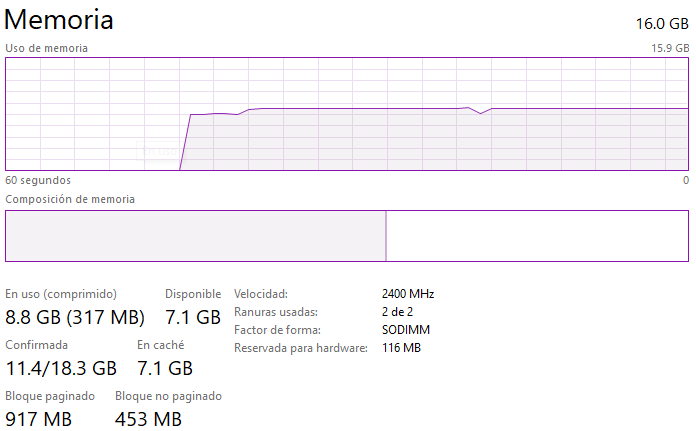
Memoria Half:
Memoria Single:
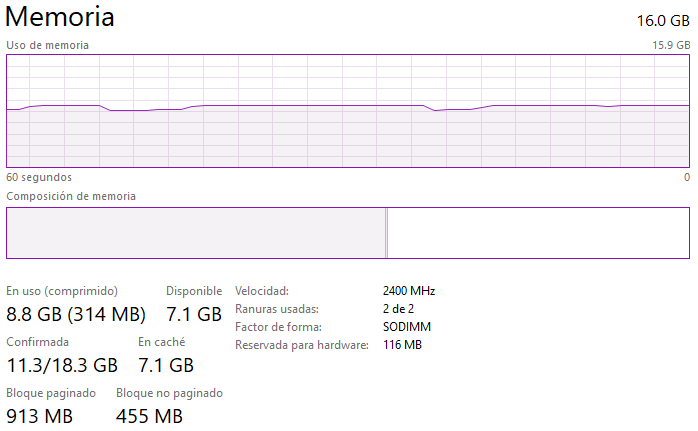
Memoria Double:
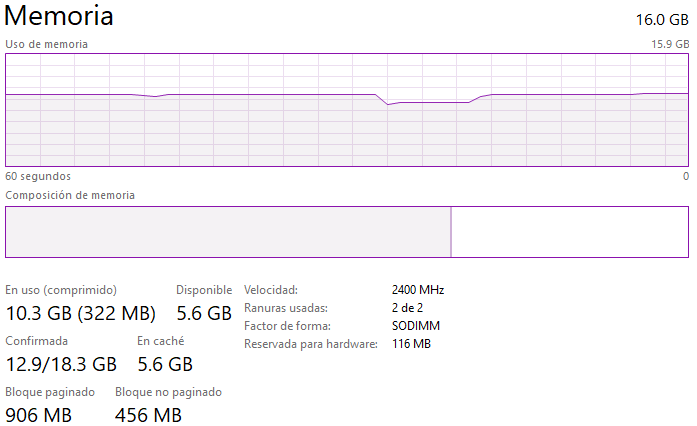
Observaciones:
- Se asume que el float mencionado en el enunciado es float32.
- En scipy.linalg.eigh() se usa turbo = "ev" en lugar de driver = "ev" esto se debe a que driver fue incorporado en scipy a partir de su versión 1.5.0, en mi caso tengo la versión 1.1.0 por lo que tengo que usar turbo = "ev".
- El código se separó en los casos, pero cada código contiene funciones para determinar cualquier cosa que se busca en esta entrega.
- Para scipy.linalg.eigh() se usó como tamaño máximo de matriz 7500, debido al tiempo de ejecución de dicha función.
- ¿Como es la variabilidad del tiempo de ejecucion para cada algoritmo?
SOLVE(): Para la función solve, se puede ver en los gráficos que para tamaños de matrices pequeños, es más rápido invertir la matriz y luego multiplicar la matriz inversa por el vector b, pero a medida que el tamaño de la matriz aumenta, se puede notar claramente que el desempeño de solve(matriz, b) es más eficiente que invertir la matriz y luego multiplicarla por el vector (esto sucede para float32 y para np.double de la misma forma). Se puede tambien mencionar, que utilizar np.double o float32 no afecta notoriamente el tiempo de las corridas.
EIGH(): Se puede ver que utilizar overwrite_a = True no mejora el desempeño notoriamente en mi computador. Se puede tambien mencionar, que utilizar np.double o float32 afecta significativamente el desempeño de la función EIGH(). Finalmente, se puede observar que todos los casos de EIGH() tienen un desempeño muy similar, se encuentran las mayores diferencias entre estos casos para matrices pequeñas.
- ¿Qué algoritmo gana (en promedio) en cada caso?
SOLVE(): En promedio, los casos 2 al 7 le ganan al primer caso. Esto se debe a que la función solve() es más eficiente que invertir una matriz y luego multiplicarla por el vector b. Scipy usa algoritmos más eficientes para que solve() requiera poco tiempo para resolver sistemas de ecuaciones. De los 7 casos, el más eficiente es el caso 3. Este caso es el que más se diferencia del resto en cuanto a eficiencia debido a que define el valores positivos en el sistema de ecuaciones.
EIGH(): En promedio, todos los casos se demoran la misma cantidad de tiempo. Se puede notar que usar float32 disminuye el tiempo de corridas en comparación a np.double, debido a que se esta ocupando menos memoria.
- ¿Depende del tamaño de la matriz?
SOLVE(): Si depende del tamaño de la matriz, como se mencionó previamente, para matrices pequeñas, es más rápido invertir la matriz y luego multiplicarla por el vector b, pero para matrices más grandes es significativamente más rápido usar la función solve(A,b).
EIGH(): No depende del tamaño de la matriz, para todos los casos se obtiene un desempeño promedio bastante parecido. Esto se puede ver en los gráficos en la carpeta "Entrega 4". Por lo tanto, ningún caso es más eficiente al aumentar o disminuir el tamaño de la matriz.
- ¿A que se puede deber la superioridad de cada opción?
SOLVE(): Como se mencionó previamente, la superioridad del caso 3 se debe a que asume valores positivos en el sistema de ecuaciones, por lo que el tiempo en calcular las variables se acorta bastante (debido a que solo se buscan valores positivos y no negativos).
EIGH(): La superioridad de cada opción se debe al tamaño de la memoria que es utilizado. En promedio, al usar float32, se obtienen intervalos de tiempos más pequeños.
- ¿Su computador usa más de un proceso por cada corrida?
R: Para ambas funciones se usan los 4 núcleos y 8 procesadores lógicos disponibles (esto se aplica para todos los casos solicitados. Eso se debe principalmente a que NumPy y SciPy hacen una paralelización automática al correr el código, por lo que se usan múltiples procesadores simultáneamente.
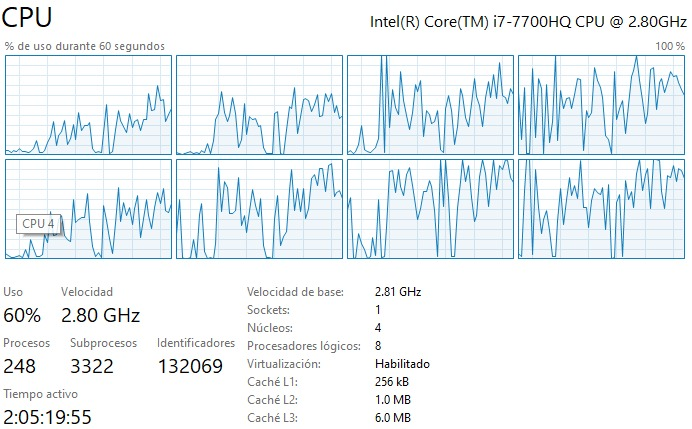
- ¿Que hay del uso de memoria (como crece)?
R: Se puede ver a continuación que cuando corre el código, la memoria varía dependiendo del tamaño de la matriz que se esta intentando de resolver. Resolver matrices muy grandes utilizan harta memoria en comparación a cuando se resuelven matrices pequeñas. También, ejecutar el código para float32 hace que se consuma menos memoria que np.double debido a que float32 es menos preciso que np.double (utiliza menos bits). La imagen a continuación es representativa para la mayoría de los casos solicitados para la Entrega 4:
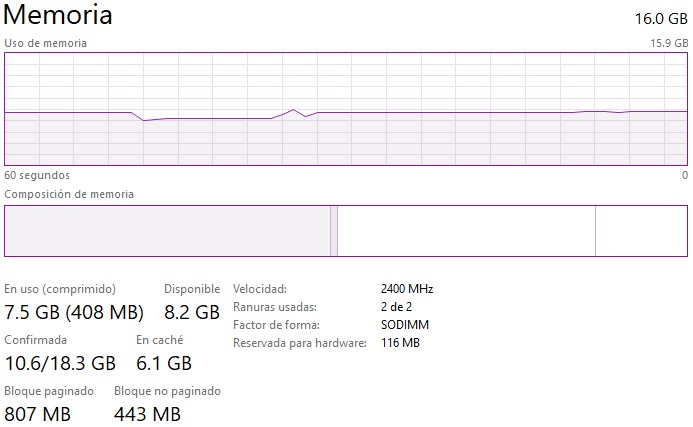
Los códigos de ensamblajes de la matriz laplaciana usados son los siguientes (uno es para el caso de la matriz llena y el otro es para el caso de la matriz dispersa):
def laplacianaLlena(N, t):
e = eye(N) - eye(N,N,1)
return(t(e+e.T))
def laplacianaDispersa(N, t):
e = sparse.eye(N, dtype = t) - sparse.eye(N, N, 1, dtype = t)
return(e+e.T)
Comentarios:
Mientras más pequeño es O(N), mejor será el desempeño. A continuación se puede ver que la matriz dispersa para tamaños de matriz pequeños, se tiene O(N⁰) pero para matrices más grandes (N = 25 000 000) tiende a O(N), esto se aplica para el tiempo de ensamblaje y el tiempo de solución. Mientras que para la matriz llena para el tiempo de ensamblaje tiende a O(N) y a O(N²) para el tiempo de solución. Se puede ver que el tiempo de ensablaje tiene mejor desempeño para ambas matrices que el tiempo de solución (matmul). Además se puede notar que la matriz dispersa tiene mucho mejor desempeño que la matriz llena.
MATRIZ LLENA
- Los datos usados son hasta un N = 10 000.
- A partir de los gráficos obtenidos, se puede ver que el tiempo de ensamblaje de la matriz llena tiende a O(N), mientras que el tiempo de solución tiende a O(N²).
Procesadores:
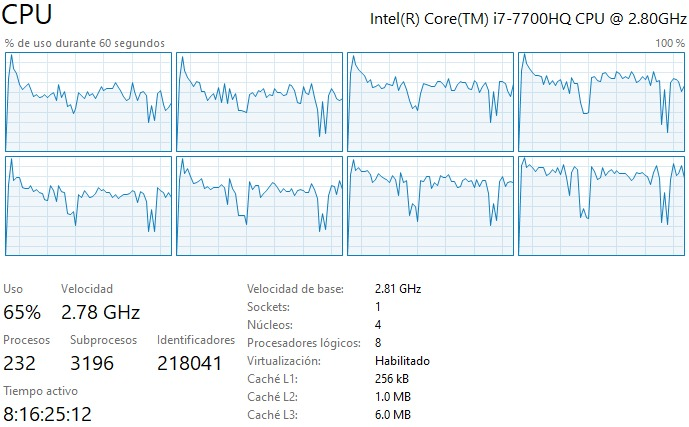
Memoria:
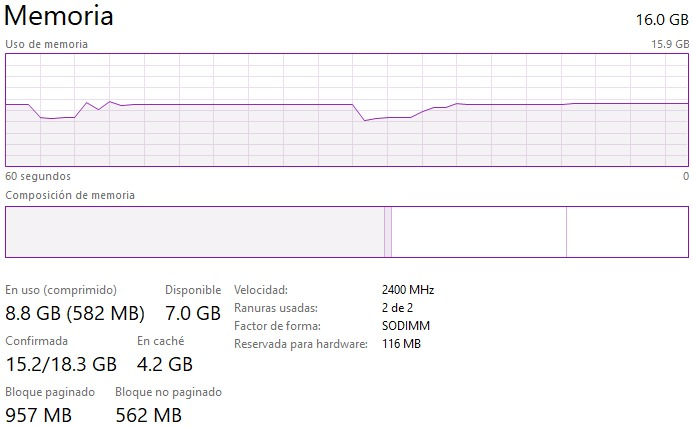
MATRIZ DISPERSA
- Los datos usados son hasta un N = 25 000 000, esto se hace para que los tiempos de ensamblado y solución no sean tan pequeños. Se puede ver que si se utiliza N = 10 000 (el mismo valor usado para la matriz llena), todos los valores obtenidos tienden a una constante.
- A partir de los gráficos obtenidos, se puede ver que el tiempo de ensamblaje de la matriz, para matrices pequeñas, tiende a una constante. A medida que el tamaño de la matriz aumenta (a 25 000 000) se puede ver que el tiempo de ensamblado y el tiempo de solución tienden a O(N).
- Se puede mencionar que dado que la matriz dispersa no tiene que calcular los 0's de la matriz laplaciana, este es un método mucho más eficiente que la matriz llena (la matriz llena si tiene que calcular los 0's). Dado esto y dado que la mayor porción de la matriz laplaciana al ser una matriz N >= 6, se puede notar que el tiempo de ensamblado y de solución de la matriz dispersa será bastante más rápido que la matriz llena. Esto se puede corroborar al ver los gráficos obtenidos (las siguientes comparaciones son de tiempos de ensamblaje, pero para el caso de tiempo de solución, la matriz dispersa también es mucho más eficiente), ya que la matriz llena se demora alrededor de 4.75s para una matriz de N = 10 000, mientras que la matriz dispersa se demora alrededor de 2.5s para una matriz de N = 10 000 000 y 7s para una matriz de N = 25 000 000. Por lo que se puede ver que la matriz dispersa puede ensamblar y solucionar matrices laplacianas de tamaño mucho mayor en un tiempo más corto.
Procesadores:
Memoria:
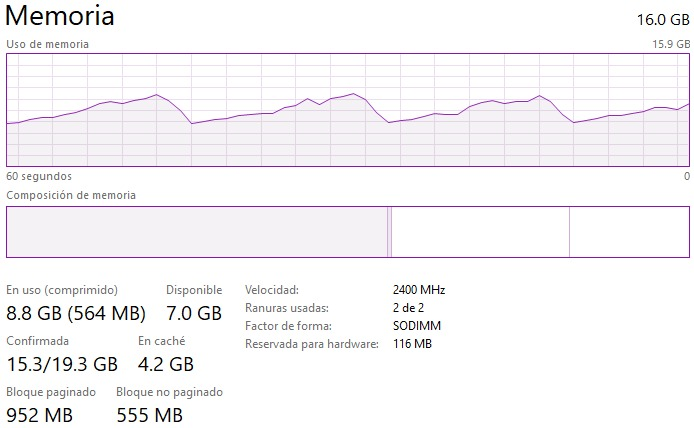
PROCESADORES Y MEMORIA
- Al comparar la memoria de la matriz llena vs la matriz dispersa, se puede ver claramente que la matriz llena tiene un valor que tiende a ser constante y la matriz dispersa no, se ve que la matriz dispersa tiende a ser lineal dado a que los procesos son más rapidos que la matriz llena.
- Se puede ver además que durante ambas ejecuciones del código, se usan los 4 núcleos y los 8 procesadores lógicos disponibles. Esto se debe a que hay una paralelización automática al correr el código, por lo que se pueden usar múltiples procesadores simultáneamente.
- Al comparar el uso de CPU de la matriz llena vs la matriz dispersa, se puede ver que dado que la matriz dispersa es más eficiente que la matriz llena, usa mucho menos porcentaje del CPU.
Los códigos de ensamblajes de la matriz laplaciana usados son los siguientes (uno es para el caso de la matriz llena y el otro es para el caso de la matriz dispersa):
def laplacianaLlena(N, t):
e = eye(N) - eye(N,N,1)
return(t(e+e.T))
def laplacianaDispersa(N, t):
e = sparse.eye(N, dtype = t) - sparse.eye(N, N, 1, dtype = t)
return(e+e.T)
Comentarios:
- Esta elección de funciones son las más eficientes que logré encontrar. Se hicieron varias comparaciones con otras funciones, pero estas fueron las que tenian mejor desempeño. Dentro de estas dos funciones, se puede destacar la segunda, ya que esta proporciona una manera más eficiente de guardar datos. Para dicha matriz no es necesario almacenar los 0's, por lo que al hacer operaciones con esta matriz, será más rápido que la otra, ya que evita hacer operaciones que serán 0. Más adelante se explica en mayor detalle las diferencias de ambas matrices.
- El código hace las corridas dependiendo del tiempo que tarde por corrida. Se le implementó un límite de 2 minutos por corrida, ya que esto fue lo que sugirió el profesor. Se puede incrementar el tamaño de las matrices manualmente para ver que se cumple esto. En el código subido no se quiere ver hasta que matriz llega, se dejó un tamaño de matriz estable para cada tipo de corrida (matriz llena, matriz dispersa) para que se pueda comparar de manera más justa cada una de estas matrices.
SOLVE: se usó "solve(matrizNxN, b, assume_a = 'pos')" dado que fue el más eficiente para mi computador.
-
Matriz llena:
- Se puede observar que el tiempo de ensamblaje tiende a O(N) cuando N → ∞ y el tiempo de solución tiende a O(N²) cuando N → ∞. Esto se deduce a partir de los los graficos obtenidos (ver carpeta P0E6), ya que, la curva tiende a asemejarse con la curva de O(N) y O(N²) respectivamente, por lo que esas serán sus complejidades computacionales.
- El tamaño de la matriz afecta significativamente el desempeño del tiempo de ensamblado y el tiempo de solución, a partir de los gráficos se puede determinar que se cumple una función exponencial, es decir, a medida que aumenta el tamaño de la matriz, el tiempo (de ensamblado y solución) aumentaran exponencialmente (en O(N) y O(N²) respectivamente).
- Se puede ver que para el tiempo de ensamblado hay un comportamiento relativamente estable, a diferencia de un par de puntos. En cambio, para el tiempo de solución, se ve que no es tan estable, se ve que hay un par de corridas menos estables que otras. No obstante, para ambos tiempos se ve que la mayoría de las corridas son estables, esto se puede notar ya que según mi código las lineas son negras pero con transparencia, y dado que la linea principal se ve negra (sin transparencia) se puede notar que hay varias lineas (corridas) encima de otras. Esto significa que para ambos tiempos, todas las corridas se parecen entre si, en la mayoría de los casos.
-
Matriz dispersa:
- Se puede observar que el tiempo de ensamblaje tiende a una constante cuando N → ∞ y el tiempo de solución tiende a O(N) cuando N → ∞. Esto se deduce a partir de los los graficos obtenidos (ver carpeta P0E6), ya que, la curva tiende a asemejarse con la curva de Constante y O(N) respectivamente, por lo que esas serán sus complejidades computacionales.
- A partir de los gráficos se puede observar que el tamaño de la matriz afecta solo al desempeño del tiempo de solución, ya que para el tiempo de ensamblaje se ve un comportamiento constante. En cambio, para el tiempo de solución, se ve que aumenta exponencialmente de acuerdo al tamaño de la matriz (en O(N)).
- Se puede ver que para el tiempo de ensamblado las corridas son bastante estables, y para el tiempo de solución se puede ver que también es estable (a diferencia de un solo punto en el gráfico que hubo un "spike", pero esto puede ser debido a una falencia de mi computador). Se puede notar la estabilidad de las corridas debido a que según mi código las lineas son negras pero con transparencia, y dado que la linea principal se ve negra (sin transparencia) se puede notar que hay varias lineas (corridas) encima de otras. Esto último significa que para ambos tiempos, todas las corridas se parecen entre si, siempre.
-
Diferencias:
- Se puede ver que la matriz dispersa tiene mejor desempeño que la matriz llena, esto se debe a que esta matriz ocupa menos espacio en la memoria (debido a que no se acumulan los 0's de la matriz, en cambio, la matriz llena si). Se puede además comparar el desempeño con la linea de tendencia de las curvas. Como se menciona previamente, para el tiempo de ensamblaje, la matriz llena tiende a O(N) mientras que la matriz dispersa tiende a una constante; por lo que, para el tiempo de ensamblaje, la matriz dispersa tiene mejor desempeño. Analizando el tiempo de solución, la matriz llena tiende a O(N²) mientras que la matriz llena tiende a O(N) por lo que también tiene mejor desempeño en este caso.
INV: se usó "scipy.linalg.inv(matrizNxN, overwrite_a=True)" dado que fue el más eficiente para mi computador.
-
Matriz llena:
- Se puede observar que el tiempo de ensamblaje tiende a O(N) cuando N → ∞ y el tiempo de solución tiende a O(N²) cuando N → ∞. Esto se deduce a partir de los los graficos obtenidos (ver carpeta P0E6), ya que, la curva tiende a asemejarse con la curva de O(N) y O(N²) respectivamente, por lo que esas serán sus complejidades computacionales.
- El tamaño de la matriz afecta significativamente el desempeño del tiempo de ensamblado y el tiempo de solución, a partir de los gráficos se puede determinar que se cumple una función exponencial, es decir, a medida que aumenta el tamaño de la matriz, el tiempo (de ensamblado y solución) aumentaran exponencialmente (en O(N) y O(N²) respectivamente).
- Se puede ver que para ambos tiempos se tienen comportamientos estables. Se puede notar la estabilidad de las corridas debido a que según mi código las lineas son negras pero con transparencia, y dado que la linea principal se ve negra (sin transparencia) se puede notar que hay varias lineas (corridas) encima de otras. Esto último significa que para ambos tiempos, todas las corridas se parecen entre si, siempre.
-
Matriz dispersa:
- Se puede observar que el tiempo de ensamblaje tiende a una constante cuando N → ∞ y el tiempo de solución tiende a O(N) cuando N → ∞. Esto se deduce a partir de los los graficos obtenidos (ver carpeta P0E6), ya que, la curva tiende a asemejarse con la curva de Constante y O(N) respectivamente, por lo que esas serán sus complejidades computacionales.
- A partir de los gráficos se puede observar que el tamaño de la matriz afecta solo al desempeño del tiempo de solución, ya que para el tiempo de ensamblaje se ve un comportamiento constante. En cambio, para el tiempo de solución, se ve que aumenta exponencialmente de acuerdo al tamaño de la matriz (en O(N)).
- Se puede ver que para el tiempo de ensamblado las corridas son bastante estables (a diferencia de un par de corridas), y para el tiempo de solución se puede ver que también es estable (excepto para N < 10, en ese rango hay una una gran diferencia entre los datos recopilados). Se puede notar la estabilidad de las corridas debido a que según mi código las lineas son negras pero con transparencia, y dado que la linea principal se ve negra (sin transparencia) se puede notar que hay varias lineas (corridas) encima de otras. Esto último significa que para ambos tiempos, todas las corridas se parecen entre si, en la mayoría de los casos.
-
Diferencias:
- Se puede ver que para el tiempo de ensamblaje la matriz dispersa tiene un desempeño mucho mejor a la matriz llena, esto se debe a que esta matriz ocupa menos espacio en la memoria (debido a que no se acumulan los 0's de la matriz, en cambio, la matriz llena si). Al comparar los tiempos de solución se puede ver que el tiempo es bastante similar, especialmente a medida que N → ∞. Se puede además comparar el desempeño con la linea de tendencia de las curvas. Como se menciona previamente, para el tiempo de ensamblaje, la matriz llena tiende a O(N) mientras que la matriz dispersa tiende a una constante; por lo que, para el tiempo de ensamblaje, la matriz dispersa tiene mejor desempeño. Analizando el tiempo de solución, la matriz llena tiende a O(N²) mientras que la matriz llena tiende a O(N) por lo que también tiene mejor desempeño en este caso.