Per-request token cost + latency + cache observability for any Flutter LLM app. Drop-in wrapper, live HUD in dev, silent telemetry sink in prod.

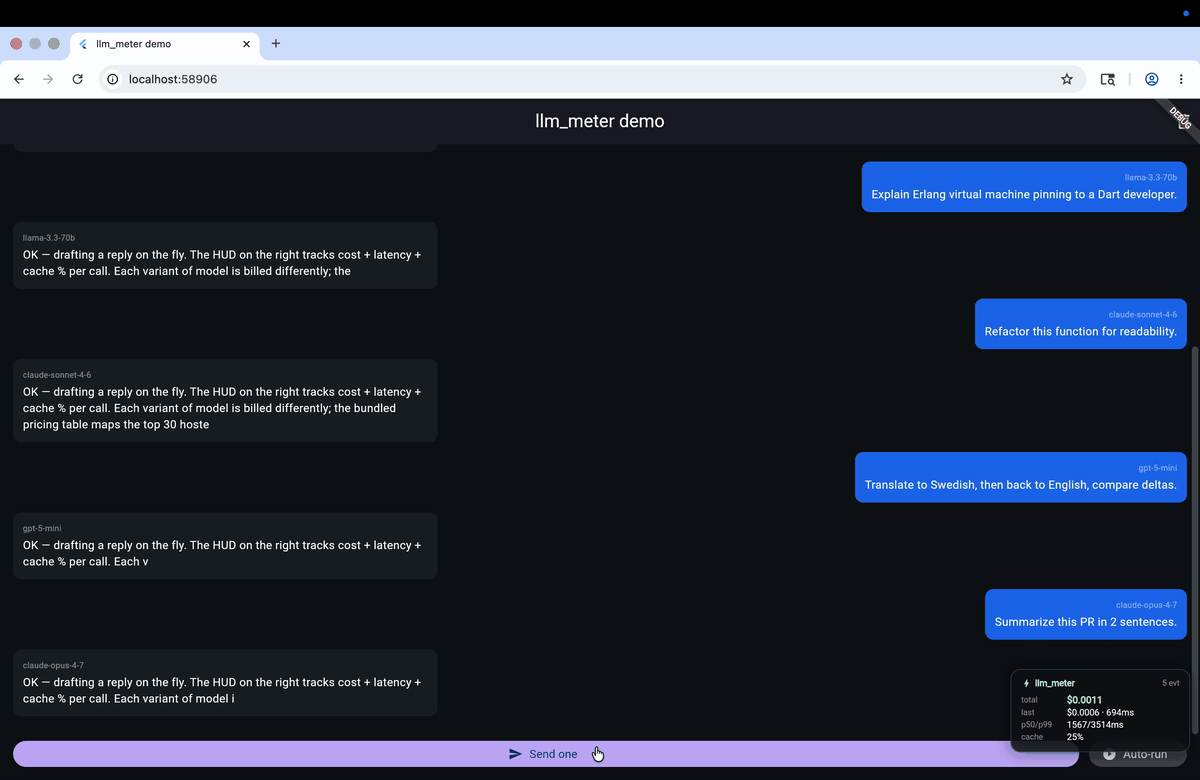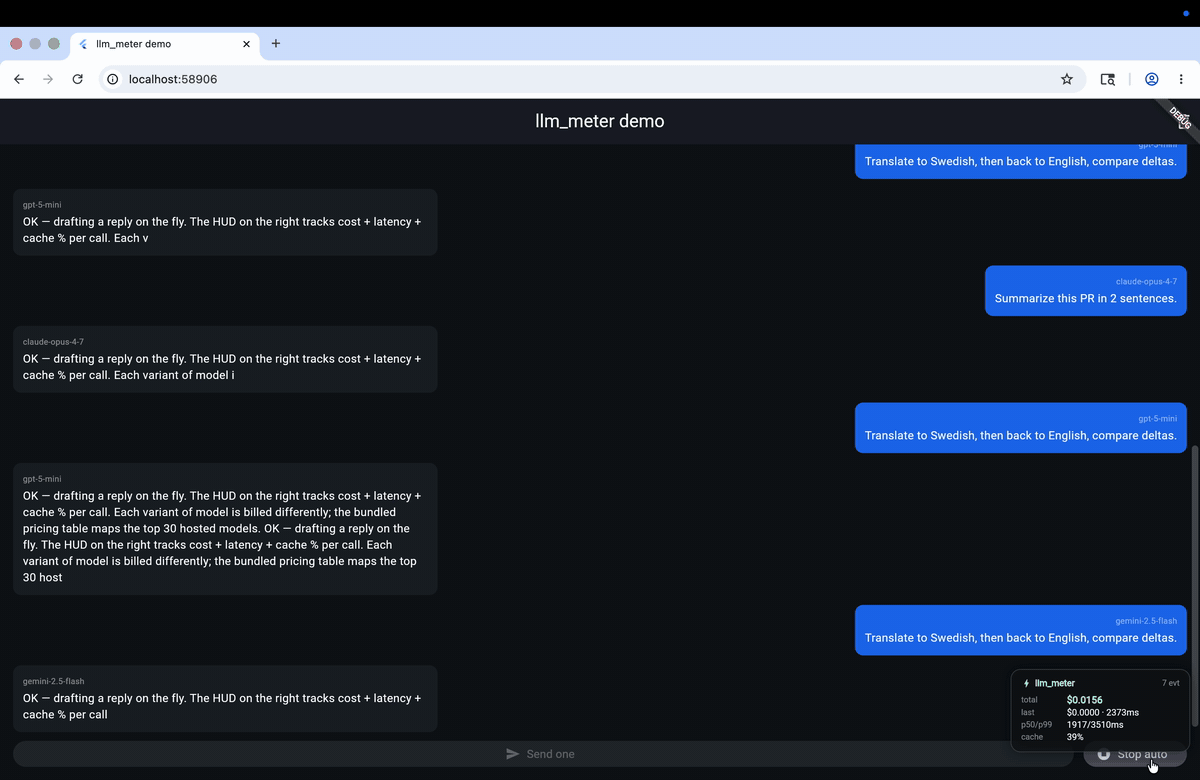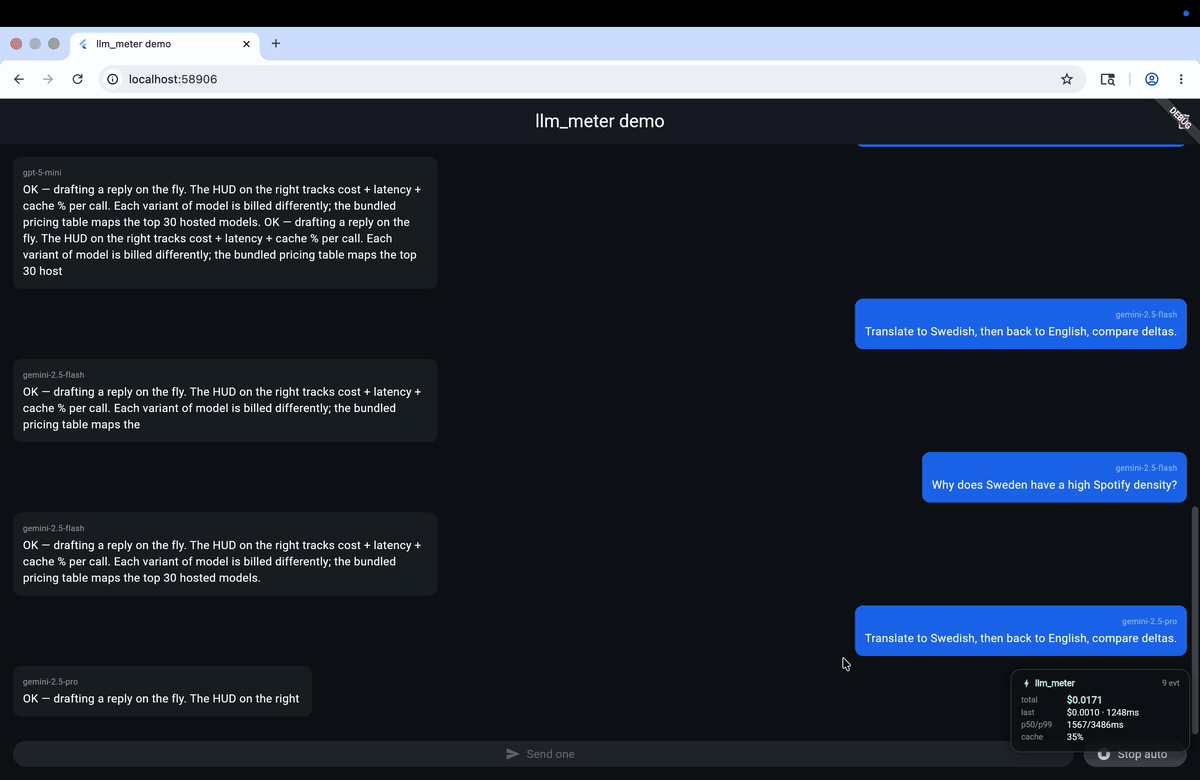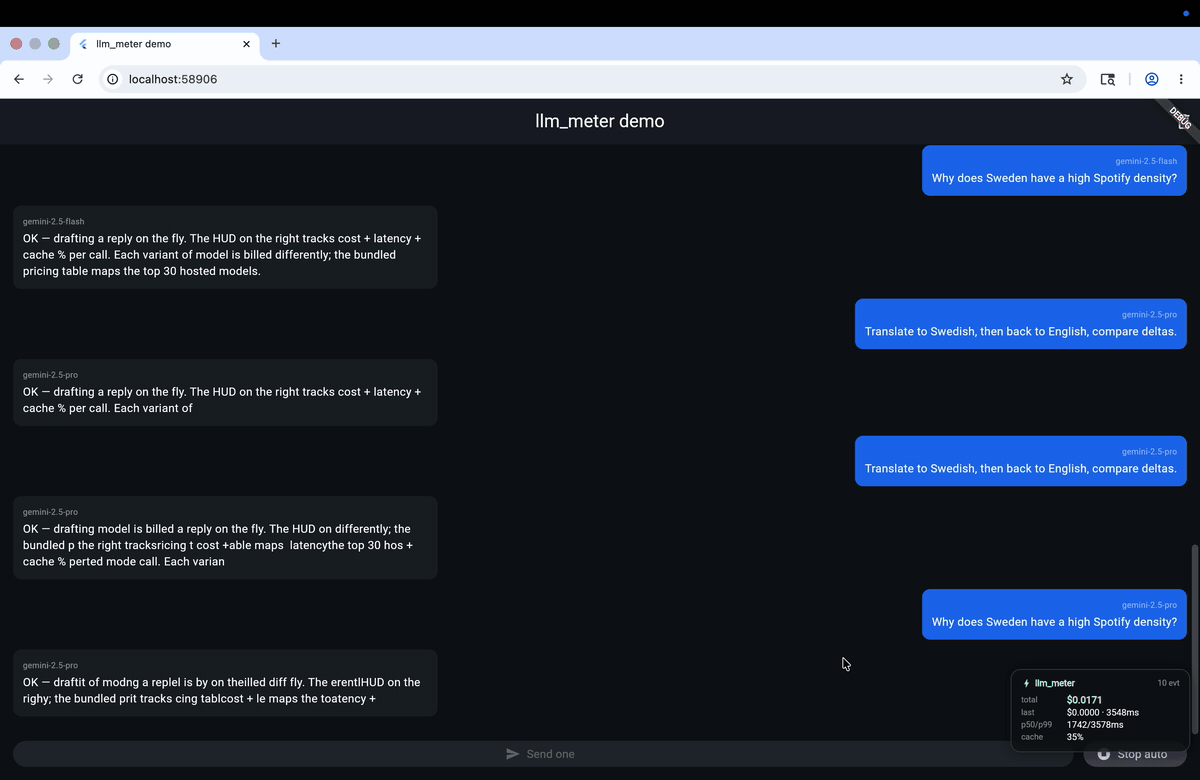
Most Flutter LLM apps ship with zero visibility into how much each call
costs, how slow the slowest call is, or how often the prompt cache actually
hits. llm_meter fixes that in three lines:
LlmMeter.init(const MeterConfig(sinks: [ConsoleSink()]));
final response = await MeteredCall.run(
provider: 'openai', model: 'gpt-5',
call: () => myClient.chat(...),
extract: (r) => openAiUsage(r.toJson()),
);Drop const LlmMeterHud() somewhere in your widget tree and the floating
HUD shows live cost / latency / cache% / p50 / p99 — auto-hidden in release
builds.
| 🪶 | Zero runtime deps — pure Flutter. Adds nothing to your install size. |
| 💰 | 31 hosted models priced out of the box (OpenAI, Anthropic, Gemini, Llama, Mistral, xAI, DeepSeek, Cohere) |
| 🚦 | Cache discount correctly applied for Anthropic + Gemini context caching |
| 📈 | Live HUD — draggable, snap-to-corner, tap-to-expand event log |
| 📤 | Sinks for PostHog, Mixpanel, plus Batching + Retrying decorators |
| 🔐 | Zero credentials in package — never reads keys; you bring your own client |
| 🇪🇺 | GDPR-safe scrub helper for sinks |
| ✅ | 124 tests, flutter analyze --fatal-warnings clean |
llm_meter |
LangSmith | Helicone | Build it yourself | |
|---|---|---|---|---|
| Flutter-native widget | ✅ | ❌ | ❌ | maybe |
| Works offline / fully local | ✅ | ❌ | ❌ | ✅ |
| No vendor lock-in | ✅ | ❌ | ❌ | ✅ |
| Per-model cost table built in | ✅ | partial | ✅ | ❌ |
| Drop-in dev HUD | ✅ | ❌ | ❌ | ❌ |
| Cost in production telemetry | ✅ | ✅ | ✅ | weeks of work |
dependencies:
llm_meter: ^0.1.0import 'package:flutter/material.dart';
import 'package:llm_meter/llm_meter.dart';
void main() {
LlmMeter.init(const MeterConfig(
sinks: <MeterSink>[ConsoleSink()],
displayCurrency: Currency.usd, // or Currency.eur, Currency.sek, ...
));
runApp(MaterialApp(
home: Stack(children: const <Widget>[
MyChatPage(),
LlmMeterHud(), // ← floating dev HUD
]),
));
}Bring your own LLM client; llm_meter just measures it.
final response = await MeteredCall.run<MyOpenAiResponse>(
provider: 'openai',
model: 'gpt-5',
call: () => openai.chat.completions.create(
model: 'gpt-5',
messages: [...],
),
extract: (r) => openAiUsage(r.toJson()),
);final stream = MeteredStream.wrap<OpenAiChunk>(
provider: 'openai',
model: 'gpt-5',
stream: openai.chat.completions.createStream(...),
extractChunk: (chunk) => chunk.usage == null
? null
: MeterUsage(
tokensIn: chunk.usage!.promptTokens,
tokensOut: chunk.usage!.completionTokens,
),
);
await for (final chunk in stream) {
appendToUi(chunk.text);
}LlmMeter.instance.record(MeterEvent(
provider: 'openai',
model: 'gpt-5',
tokensIn: 1240,
tokensOut: 286,
cachedTokensIn: 800,
costUsd: 0, // auto-priced from the bundled table
latency: const Duration(milliseconds: 420),
timestamp: DateTime.now(),
));The three big providers all hand back JSON. Bundled helpers take that JSON
and emit a MeterUsage:
extract: (r) => openAiUsage(r.toJson())
extract: (r) => anthropicUsage(r.toJson())
extract: (r) => geminiUsage(r.toJson())Anthropic cache_read_input_tokens and Gemini cachedContentTokenCount
flow into the cache discount automatically.
LlmMeter.init(MeterConfig(
sinks: <MeterSink>[
BatchingSink(
inner: RetryingSink(
inner: PosthogSink(
apiKey: dotenv.env['POSTHOG_KEY']!, // ← user-supplied
host: 'https://eu.posthog.com', // EU residency
scrubGdpr: true,
),
),
maxBatchSize: 25,
flushInterval: const Duration(seconds: 30),
),
],
gdprMode: true,
));| Sink | Use |
|---|---|
ConsoleSink |
dev default; prints with debugPrint |
PosthogSink |
fire-and-forget /capture/ via dart:io HttpClient |
MixpanelSink |
/track ingestion with base64 JSON |
BatchingSink |
groups events by count or time |
RetryingSink |
exponential backoff + offline queue |
API keys are constructor args only. This package never reads from env vars, shared prefs, or any file on disk.
Override or add models on the fly. Useful when a provider updates a price or you're calling a fine-tune.
LlmMeter.init(MeterConfig(
pricingOverrides: <String, ModelPricing>{
'gpt-5': const ModelPricing.perMillion(
inputPerMillion: 1.25,
outputPerMillion: 10.0,
cachedInputPerMillion: 0.125,
),
'my-finetuned-llama': const ModelPricing.perMillion(
inputPerMillion: 0.40,
outputPerMillion: 0.60,
),
},
));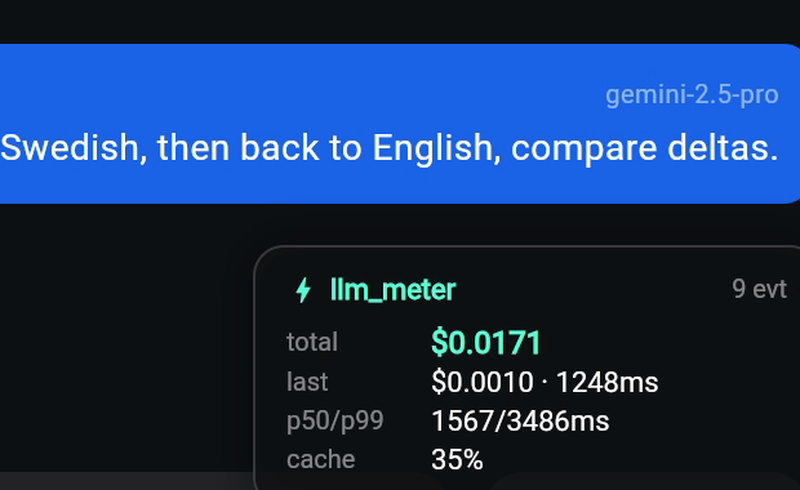
const LlmMeterHud(
corner: HudCorner.bottomRight,
padding: EdgeInsets.all(16),
maxEventsInLog: 20,
)Auto-hidden in release builds. Pass forceShow: true for staging.
- OpenRouter wrapper (planned for 0.2)
- Local Ollama / LM Studio wrappers (planned for 0.2)
- Datadog and Sentry sinks (planned for 0.2)
- Daily / session cost caps with hard-stop callbacks (planned for 0.2)
BSD-3-Clause. See LICENSE.