trying to understand a network by calculate the graph-level and node-level metrics.

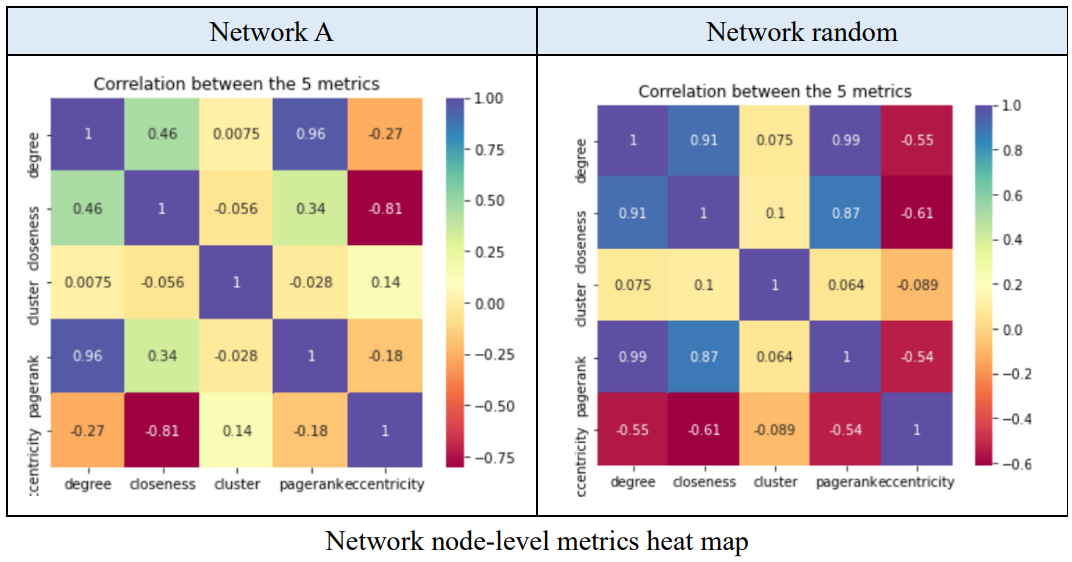
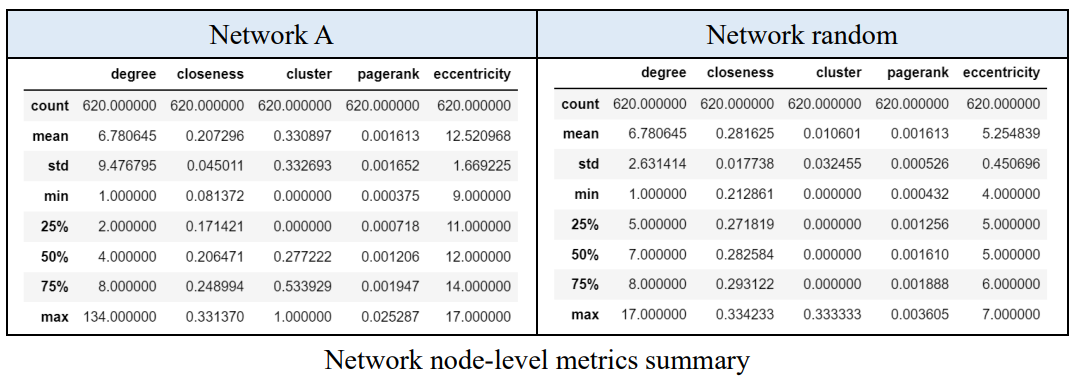
How many nodes are directly linked to this node. We can use degree to understand how many connections this person has. If he has a higher degree, he is more likely to be a social person and therefore, you can approach him with a greater probability of getting what you are aiming for.
How much distance a node is to any other nodes. We can use closeness to see whether someone is central in the network and won’t need to take a lot of steps to meet other nodes. For example, if one has a low closeness score, it means that this person is in short distance with others and can reach whoever in the network more quickly and easily. Thus, if we are in urgent situations, we can always find this person to be a transmitter in the network.
How close a node’s neighbors is going to form a cluster (triangle). If a node’s neighbor’s is unlikely to make connections, then we can somehow predict that this node is not as centric and might even be an outlier.
How important is this node in a sense that more nodes are linked to this node. Page Rank comes from the search engine algorithm, determining the importance of a website, therefore, I assume that Page Rank can help us with SEO (Search Engine Optimization). We can insert more hyperlinks to the other nodes and therefore giving the website a higher probability of being entered.
The longest distance between a node and another one. Knowing the eccentricity can help us to determine whether a node is in the set of center nodes or periphery nodes. For example, if one person has a longest distance 5 to another person in a network and the network’s radius is also 5. Then we can conclude that this person might be in the set of center nodes, and he might be more resourceful in the network.
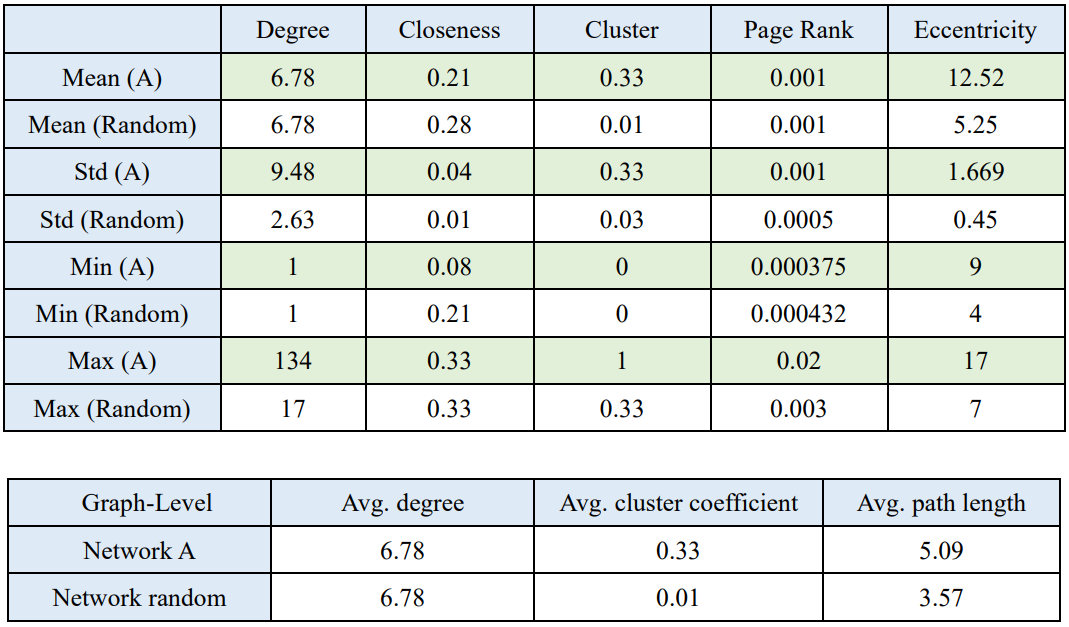
Network A has a higher global cluster coefficient than network random, meaning that the real network has a more clustered network. However, the average path length in network random is lower than network A. This phenomenon might because the path length distribution in network random has a lower standard deviation.