Repository for my bachelor thesis, where I try to improve on previous code search (NL to PL) methods by applying the xMoCo framework and other methods. The thesis itself can be found here.
For comparable results, it is necessary to download the pre-processed and pre-filtered CodeSearchNet dataset by the authors of CodeBERT from https://github.com/microsoft/CodeBERT/tree/master/CodeBERT/code2nl (download link: https://drive.google.com/file/d/1rd2Tc6oUWBo7JouwexW3ksQ0PaOhUr6h).
Place the unpacked data (the "CodeSearchNet" folder) in "datasets/" (so you would e.g. have the Python training data under "datasets/CodeSearchNet/python/train.jsonl")
To download this using command line, do the following:
pip install gdown
mkdir datasets
cd datasets/
gdown https://drive.google.com/uc?id=1rd2Tc6oUWBo7JouwexW3ksQ0PaOhUr6h
unzip Cleaned_CodeSearchNet.zip
rm Cleaned_CodeSearchNet.zip
cd ..
Requirements to run:
Python 3.9
PyTorch 1.9.0
pytorch-lightning 1.4.0
transformers
faiss-cpu 1.7.1
nltk
torchvision 0.10.0
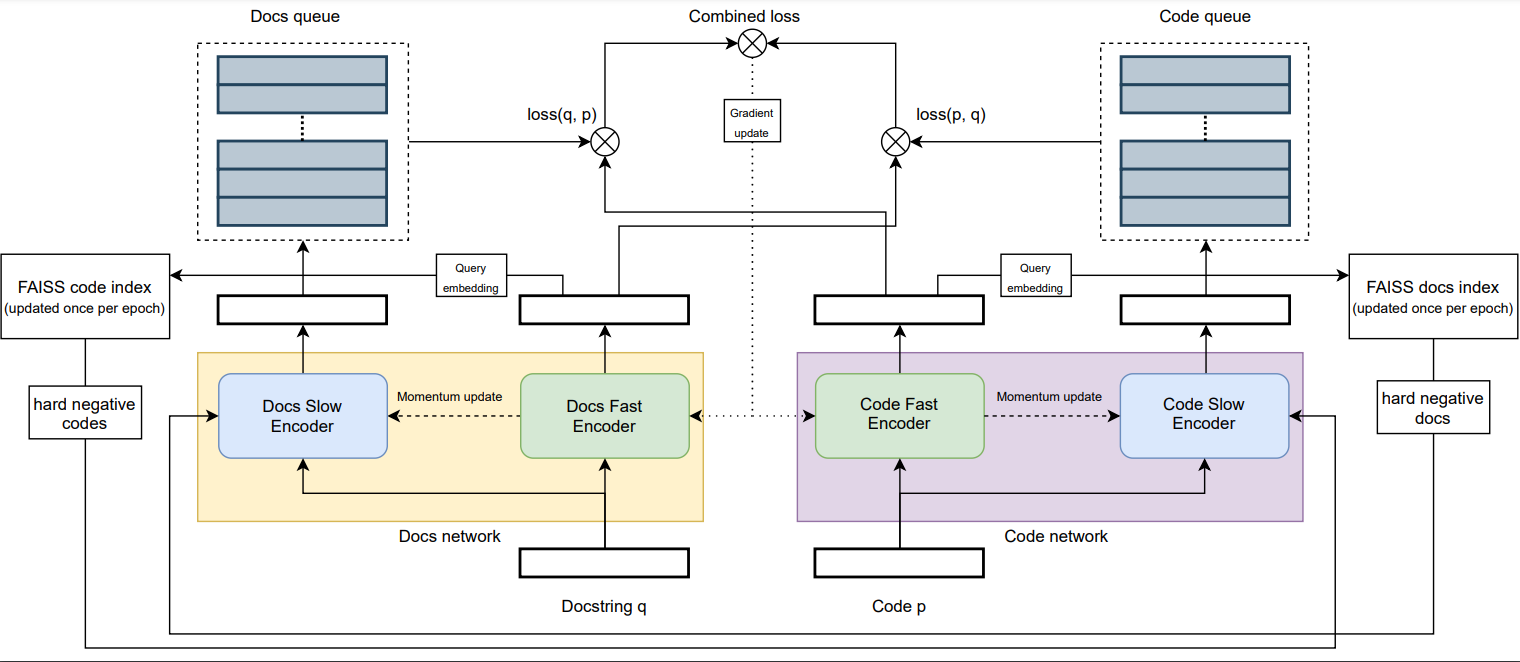
There are many flags for xMoCo_pl.py, some for hyperparameters and some for debugging. The important ones are:
--docs_encoder: Huggingface model path for the docstring encoder (needs to have 768 embedding size)
--code_encoder: Huggingface model path for the code encoder (needs to have 768 embedding size)
--num_epochs: Number of epochs to train for at most (early stopping is enabled)
--effective_batch_size: Effective batch size. a batch of effective_batch_size/num_gpus is used per gpu
--learning_rate: Learning rate
--temperature: Temperature parameter for the adapted InfoNCE loss
--effective_queue_size: Number of samples the queue can hold
--momentum_update_weight: Factor used for the momentum encoder updates
--num_hard_negatives: Number of hard negatives to fetch per sample
--hard_negative_queue_size: The size of the hard negative queue
--enable_barlow_loss: Enables the Barlow loss in addition to the InfoNCE loss
--barlow_lambda: Weight of off-diagonal elements in the Barlow loss
--barlow_weight: Importance of Barlow loss (used to trade off InfoNCE and Barlow)
--barlow_projector_dimension: Dimension of the barlow projector (0 to disable)
--barlow_tied_projectors: Ties the two barlow projectors such that Docs and Code are pushed through the same projector
--shuffle: Enables shuffling of the training data
--augment: Enables EDA augmentation of the NL part of the training data
--base_data_folder: Folder that contains the cleaned CodeSearchNet dataset
--debug_data_skip_interval: Take only every i-th entry of the train/val dataset to decrease amount of data used
--always_use_full_val: Ignores the debug_data_skip_interval flag for the validation set
--language: Which subset of the CodeSearchNet dataset to use
--skip_training: Skips training and jumps right into testing (if enabled)
--checkpoint_path: Path to the model checkpoint that should be used for testing
--do_test: When set, the best checkpoint is loaded after training and the combined val/test set is used to determine the final MRR
An example command can be seen below:
python xMoCo_pl.py --effective_queue_size=4096 --effective_batch_size 32 --learning_rate=1e-5 --shuffle --num_hard_negatives=2 --language="ruby" --debug_data_skip_interval=1 --always_use_full_val