2021 11 17
Let's discuss the evaluation on a concrete example:
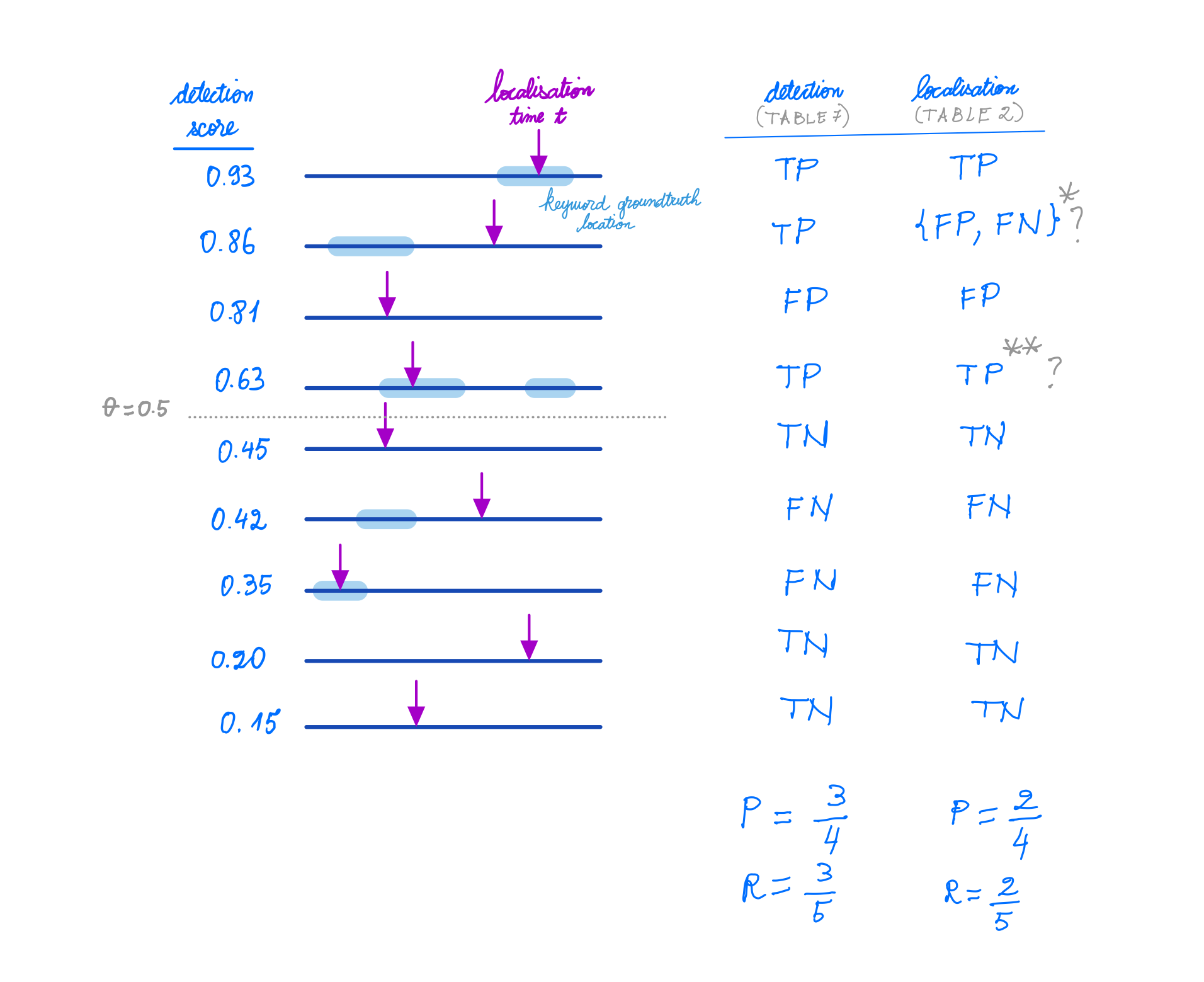
Here we show nine audio utterances with a keyword of interest w appearing in the thick light-blue regions.
The system predicts a detection score s (shown on the left) and a location t for the query keyword w (shown as a magenta arrow).
Defining the metrics. We evaluate the performance in two settings: keyword detection (as we do in Table 7 of the paper) and actual keyword localisation (as we do in Table 2 of the paper).
For keyword detection, it is rather straightforward to define the classes of interest for evaluation:
- True positive (TP):
s ≥ θandwappears at least once in the utterance. - True negative (TN):
s < θandwdoesn't appear in the utterance. - False positive (FP):
s ≥ θandwdoesn't appear in the utterance. - False negative (FN):
s < θandwappears at least once in utterance.
For actual keyword localisation, to define the four classes we also to take into account localisation—whether the prediction location falls into a keyword's segment:
- True positive (TP):
s ≥ θandwappears at least once in the utterance andtis in one of the segments. - True negative (TN):
s < θandwdoesn't appear in the utterance. - False positive (FP):
s ≥ θandwdoesn't appear in the utterance; ors ≥ θandwappears, buttis not in any of the segments. - False negative (FN):
s < θandwappears at least once; ors ≥ θandwappears, buttis not in any of the segments.
With these definitions we see that the metrics for keyword detection (precision and recall) are upper bounds on the metrics for actual keyword localisation:
the denominator is constant between the two setups for both metrics—TP + FP (the number of retrieved samples) for precision and TP + FN (the number of samples to be retrieved) for recall—but
the numerator (the number of true positives; TP) is necessarily smaller in the actual localisation case,
since for a sample to count as a true positive it has to obey an additional condition
(the predicted location t has to fall within one of the groundtruth segments).
Subtleties. We notice at least two subtle points:
- In the actual localisation setting, can a sample be both a false positive and a false negative?
For example, the second sample from the example is clearly a false positive,
but I think it should also be treated as a false negative,
since the sum of TP and FN should yield the total number of samples to be retrieved.
Herman: I think you are correct, but don't know how it is implemented. If you aren't calculating the denominator as e.g. TP + FN for recall but simply keeping track of the number of samples to be retrieved, then this would come down to the same thing. So we should probably just consult the code. - If multiple keyword segments appear in a single utterance, but a single one is localised, will the others count as false negatives?
Herman: I do not think so; this is pretty rare, but I think to simplify things we just think of it as one keyword per utterance. Localisation is considered correct if the predicted location is within either of the occurrences. Dan: Yes, I agree that is a rare case and it will have a minor impact. So, this implies that the number of samples to be retrieved is the number of utterances that contain the query keywordw(at least once) and not the number of times the query keywordwappears throughout the dataset.
Herman: I also just include a similar figure from Kayode's proposal:
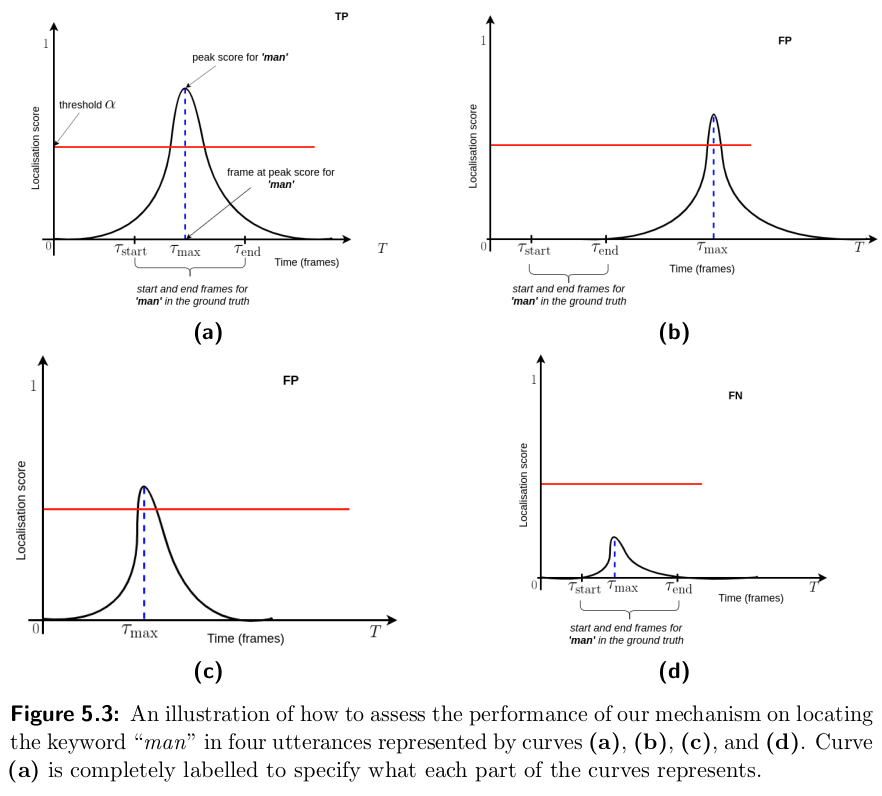
Dan: This is very helpful, but I have question: is the localisation score or the detection score used to decide whether a word appears in an utterance? The figure suggests that the answer is the localisation score, but I had the impresion we were using the detection score for ranking and judging the true positives.