If you like our project, please give us a star ⭐ on GitHub for the latest update.
Code for the paper "MMSpec: Benchmarking Speculative Decoding for Vision-Language Models".
For more details, please refer to the project page with dataset exploration and visualization tools: MMSpec Project Page.
[🌐 Project Page] [📖 Paper] [🤗 Checkpoints]
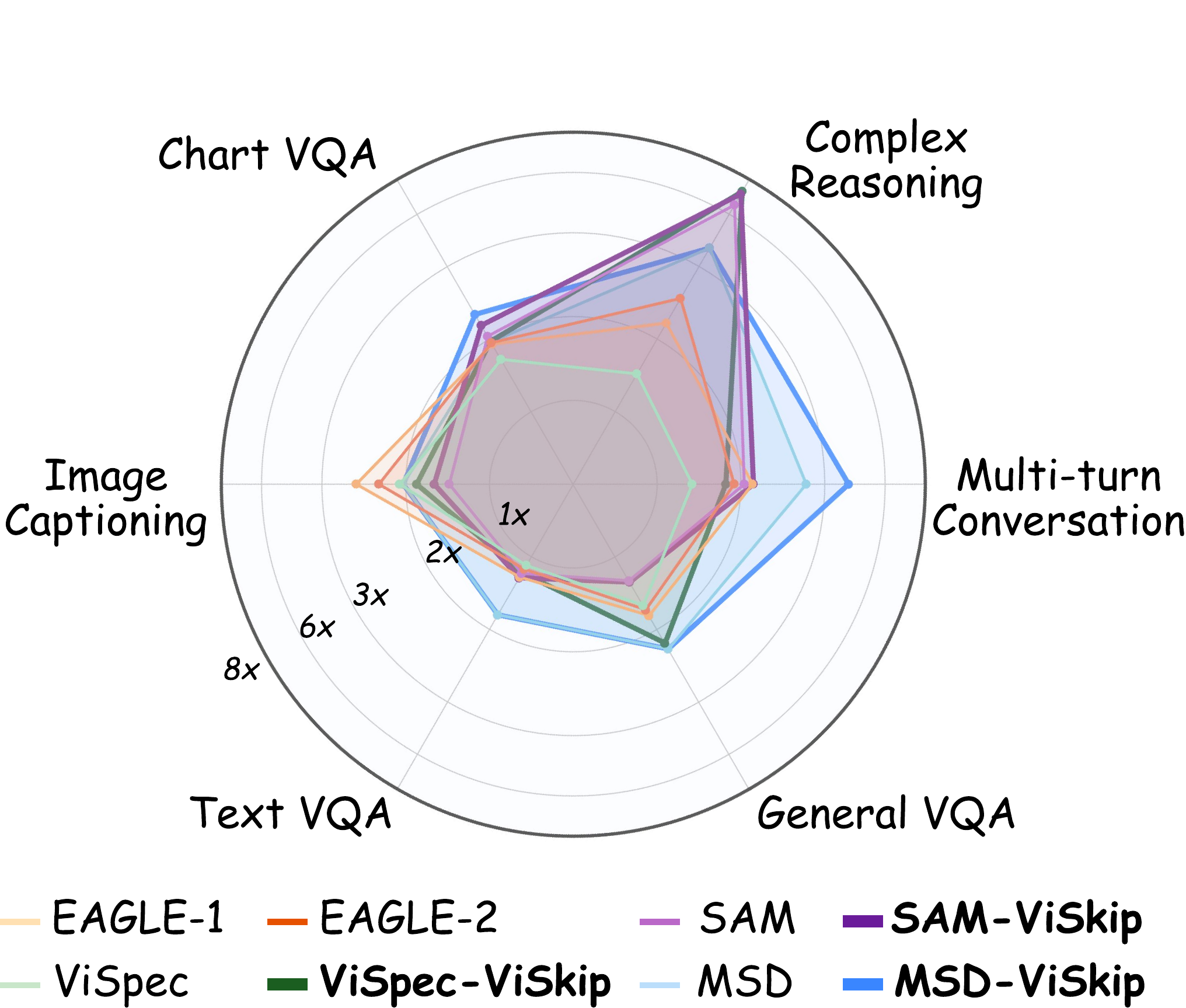
MMSpec is a benchmark for studying speculative decoding in vision-language models (VLMs). It is designed for fair third-party comparison under a unified evaluation protocol and introduces ViSkip, a plug-and-play vision-aware strategy that skips speculative drafting when the next token depends heavily on visual evidence.
The benchmark contains 600 multimodal samples from 6 task categories, covers 10 representative lossless speculative decoding methods, and reports both Mean Accepted Tokens (MAT) and Walltime Speedup Ratio.
- First benchmark dedicated to speculative decoding for VLMs.
- Unified evaluation setup for both training-based and training-free methods.
- Covers Qwen2.5-VL-7B-Instruct and LLaVA-1.5-7B as the main evaluation targets.
- Includes ViSkip variants for vision-aware latency reduction on top of existing methods.
- Benchmark At A Glance
- Methods Covered
- Repository Structure
- Installation
- Evaluation
- Training
- Key Findings
- Citation
MMSpec is built around workload diversity, balanced topic coverage, multi-turn support, and method-agnostic measurement.
| Category | Source | Avg. output length |
|---|---|---|
| General VQA | GQA | 46.98 tokens |
| Text VQA | TextVQA | 63.15 tokens |
| Image Captioning | COCO | 191.90 tokens |
| Chart VQA | CharXiv | 68.56 tokens |
| Complex Reasoning | MMMU-Pro | 285.60 tokens |
| Multi-turn Conversation | ConvBench, MM-MT-Bench | 747.65 tokens |
Dataset splits are stored under dataset/MMSpec/:
testmini: quick sanity-check subsettest: full benchmark split
Each split contains mmspec.jsonl and an images/ directory. A typical sample includes id, image, turns, category, and topic.
MMSpec unifies 10 representative lossless speculative decoding families:
- ViSpec
- MSD
- EAGLE-1 / EAGLE-2 / EAGLE-3
- Medusa
- SAM Decoding
- Lookahead
- Recycling
- PLD
This repository additionally provides runnable evaluation entrypoints for:
- baseline autoregressive decoding
- ViSkip-enhanced variants:
vispec_vskip,msd_vskip,sam_vskip

dataset/: benchmark data used by MMSpec.evaluation/: Python entrypoints for benchmark execution.method/: speculative decoding implementations, including ViSpec and ViSkip variants.scripts/: ready-to-run evaluation scripts grouped by model.train/: training code and launch scripts for EAGLE, EAGLE3, Medusa, and MSD.
The current evaluation scripts are organized by target model:
MMSpec requires Python 3.10+ and transformers==4.51.3.
pip install -r requirements.txtIf you plan to train EAGLE3 or MSD with DeepSpeed, install the corresponding runtime separately.
Run all commands from the project root.
Evaluate the Qwen model on testmini:
bash scripts/Qwen2.5-VL-7B/eval_baseline_mmspec.sh testmini
bash scripts/Qwen2.5-VL-7B/eval_vispec_mmspec.sh testmini
bash scripts/Qwen2.5-VL-7B/eval_vispec_vskip_mmspec.sh testminiEvaluate the LLaVA model on the full test split:
bash scripts/LLaVA-1.5-7B/eval_baseline_mmspec.sh test
bash scripts/LLaVA-1.5-7B/eval_msd_mmspec.sh test
bash scripts/LLaVA-1.5-7B/eval_sam_vskip_mmspec.sh testAll evaluation scripts accept testmini or test as the first argument and write results to:
results/<model_name>/mmspec_<split>/
For both model folders, the following entrypoints are available:
eval_baseline_mmspec.sheval_eagle_mmspec.sheval_eagle2_mmspec.sheval_eagle3_mmspec.sheval_lookahead_mmspec.sheval_medusa_mmspec.sheval_msd_mmspec.sheval_msd_vskip_mmspec.sheval_pld_mmspec.sheval_recycling_mmspec.sheval_sam_mmspec.sheval_sam_vskip_mmspec.sheval_vispec_mmspec.sheval_vispec_vskip_mmspec.sh
Some scripts expose optional checkpoint overrides through environment variables or a second positional argument. The default model and checkpoint paths are defined directly inside each script.
Training utilities live in train/. The repository currently includes launch scripts and code for:
- EAGLE stage 1 / stage 2
- EAGLE3 stage 1 / stage 2
- Medusa
- MSD
See train/README.md for the available launch scripts and training entrypoints.
From the MMSpec benchmark and project page:
- Training-free methods usually provide limited gains in multimodal decoding and can even regress latency.
- Training-based methods that ignore visual information still underperform in VLM inference.
- Throughput speedup alone is not enough; stable end-to-end latency matters in practice.
- Vision-aware control, as used in ViSkip, becomes increasingly important as batch size grows.
If you find MMSpec useful, please cite:
@article{shen2025mmspec,
title={MMSpec: Benchmarking Speculative Decoding for Vision-Language Models},
author={Hui Shen and Xin Wang and Ping Zhang and Yunta Hsieh and Qi Han and Zhongwei Wan and Ziheng Zhang and Jingxuan Zhang and Jing Xiong and Ziyuan Liu and Yifan Zhang and Hangrui Cao and Chenyang Zhao and Mi Zhang},
year={2025},
note={Preprint}
}This repository builds on prior speculative decoding systems including EAGLE and Medusa, and consolidates them into a unified VLM benchmarking framework.