
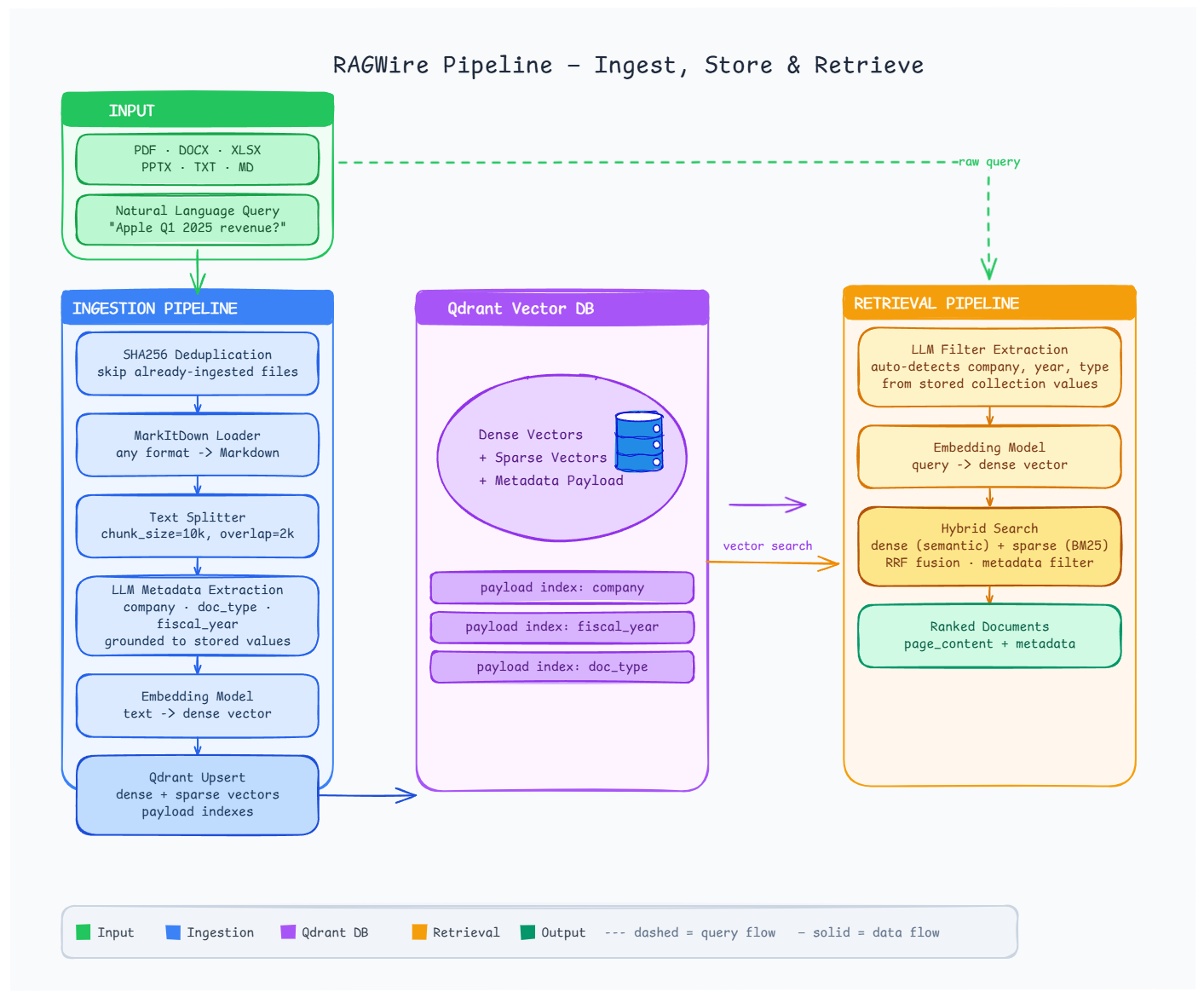
Production-grade RAG toolkit for document ingestion and retrieval

- Document Loading — PDF, DOCX, XLSX, PPTX and more via MarkItDown
- LLM Metadata Extraction — extracts company, doc type, fiscal period using your LLM; fully customisable via YAML
- Smart Text Splitting — markdown-aware and recursive chunking strategies
- Multiple Embedding Providers — Ollama, OpenAI, HuggingFace, Google, FastEmbed
- Qdrant Vector Store — dense, sparse, and hybrid search
- Advanced Retrieval — similarity, MMR, and hybrid search with metadata filtering
- SHA256 Deduplication — at both file and chunk level
- Directory Ingestion — ingest an entire folder with one call, with optional recursive scan
- Env Var Substitution — use
${VAR}inconfig.yamlfor secrets
pip install ragwire
# With Ollama support (local, no API key)
pip install "ragwire[ollama]"
# With all providers
pip install "ragwire[all]"from ragwire import RAGWire
rag = RAGWire("config.yaml")
# Ingest a list of files (shows tqdm progress bar)
stats = rag.ingest_documents(["data/Apple_10k_2025.pdf"])
print(f"Chunks created: {stats['chunks_created']}")
# Or ingest an entire directory
stats = rag.ingest_directory("data/", recursive=True)
# Retrieve
results = rag.retrieve("What is Apple's total revenue?", top_k=5)
for doc in results:
print(doc.metadata.get("company_name"), doc.page_content[:200])Copy config.example.yaml to config.yaml and edit. Secrets can be injected via environment variables:
vectorstore:
url: "https://your-cluster.qdrant.io"
api_key: "${QDRANT_API_KEY}"
llm:
provider: "openai"
model: "gpt-5.4-nano"
api_key: "${OPENAI_API_KEY}"Full example:
embeddings:
provider: "ollama"
model: "qwen3-embedding:0.6b"
base_url: "http://localhost:11434"
llm:
provider: "ollama"
model: "qwen3.5:9b"
num_ctx: 16384
vectorstore:
url: "http://localhost:6333"
collection_name: "my_docs"
use_sparse: true
retriever:
search_type: "hybrid"
top_k: 5
auto_filter: false # set true to enable LLM-based filter extraction from every query# Ollama (local)
embeddings:
provider: "ollama"
model: "qwen3-embedding:0.6b"
# OpenAI
embeddings:
provider: "openai"
model: "text-embedding-3-small"
# HuggingFace (local)
embeddings:
provider: "huggingface"
model_name: "sentence-transformers/all-MiniLM-L6-v2"
# Google
embeddings:
provider: "google"
model: "models/embedding-001"from ragwire import (
MarkItDownLoader,
get_splitter,
get_markdown_splitter,
get_embedding,
QdrantStore,
MetadataExtractor,
hybrid_search,
mmr_search,
)
# Load a document
loader = MarkItDownLoader()
result = loader.load("document.pdf")
# Split text
splitter = get_markdown_splitter(chunk_size=10000, chunk_overlap=2000)
chunks = splitter.split_text(result["text_content"])
# Embeddings
embedding = get_embedding({"provider": "ollama", "model": "qwen3-embedding:0.6b"})
# Vector store
store = QdrantStore(config={"url": "http://localhost:6333"}, embedding=embedding)
store.set_collection("my_collection")
vectorstore = store.get_store()ragwire/
├── core/ # Config loader + RAGWire orchestrator
├── loaders/ # MarkItDown document converter
├── processing/ # Text splitters + SHA256 hashing
├── metadata/ # Pydantic schema + LLM extractor
├── embeddings/ # Multi-provider embedding factory
├── vectorstores/ # Qdrant wrapper with hybrid search
├── retriever/ # Similarity, MMR, hybrid retrieval
└── utils/ # Logging
| Error | Fix |
|---|---|
| Qdrant connection refused | docker run -p 6333:6333 qdrant/qdrant |
markitdown[pdf] missing |
pip install "markitdown[pdf]" |
| Ollama model not found | ollama pull <model-name> |
fastembed missing |
pip install fastembed (needed for hybrid search) |
| Embedding dimension mismatch | Set force_recreate: true in config once, then back to false |
MIT © 2026 KGP Talkie Private Limited
- 🌐 Website: kgptalkie.com
- 📖 Docs: laxmimerit.github.io/RAGWire
- 💻 GitHub: github.com/laxmimerit/ragwire
- 📧 Email: udemy@kgptalkie.com