This is the backend for our capstone project in the VMWare Ascent Program (Bootcamp) - july / septempter 2022
My group was in charge of the search feature, developed in Java / SpringBoot & Elasticsearch (ELK stack)
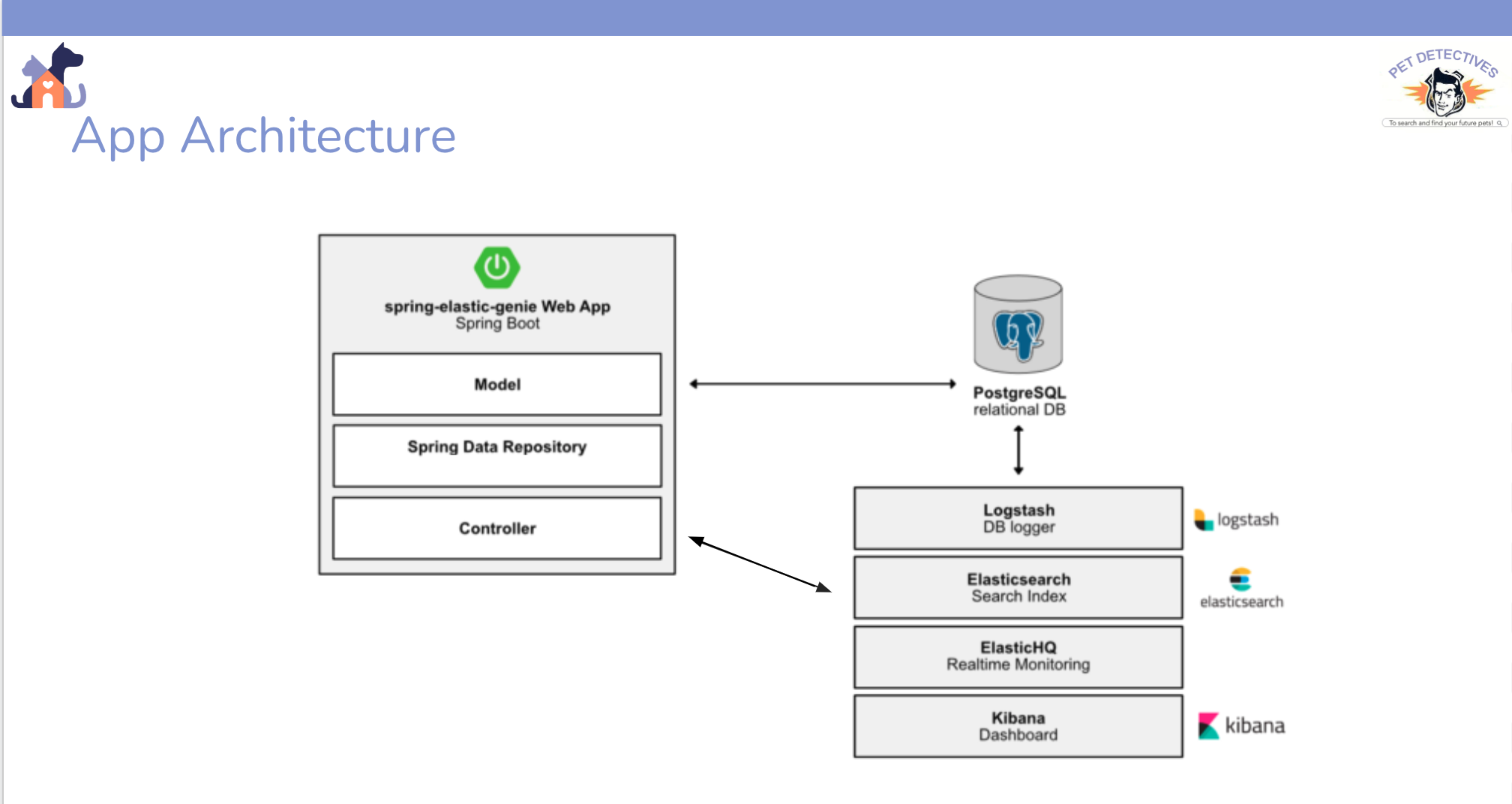
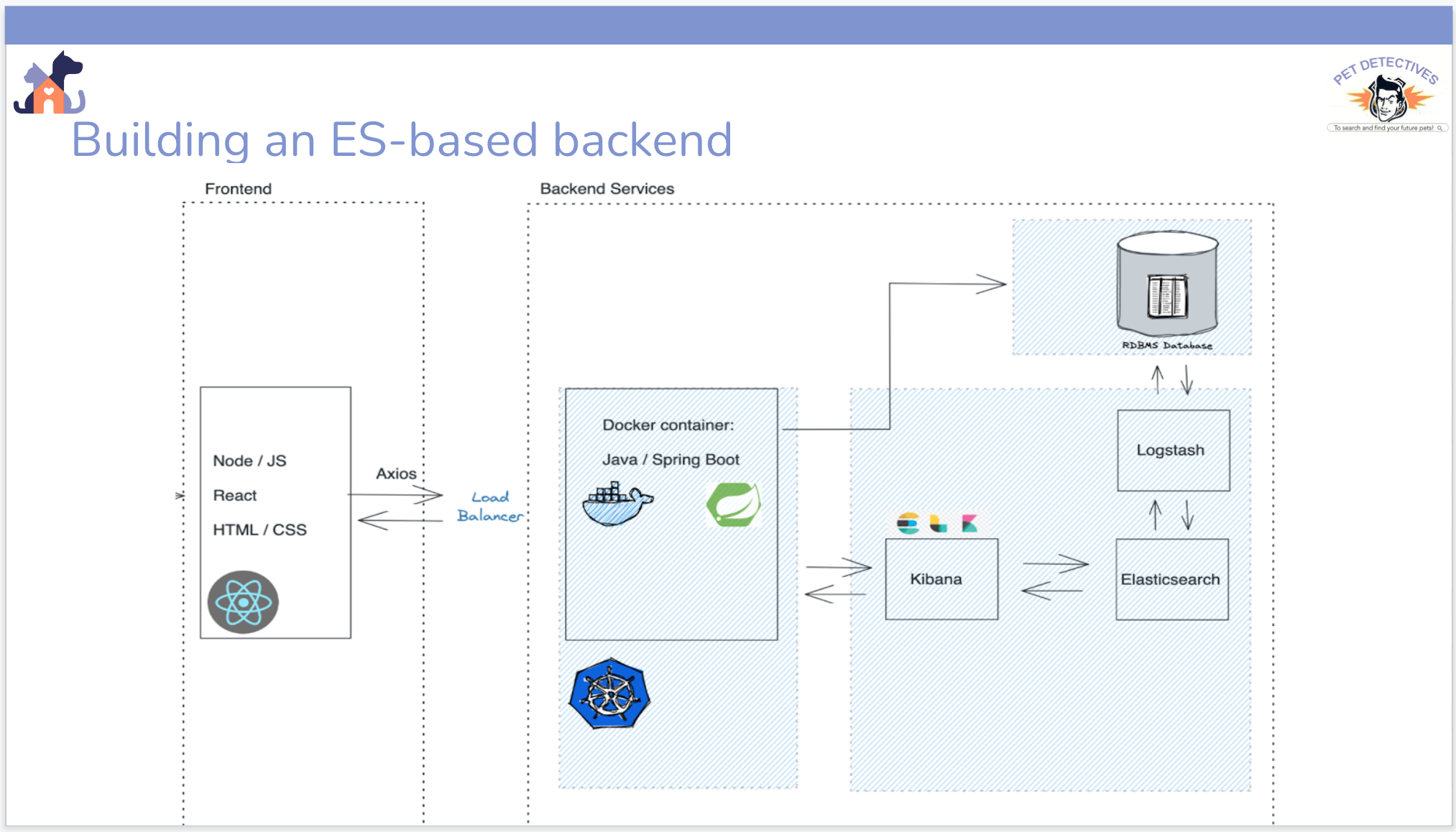
I was in charge of developing an autocomplete feature for the search.
In Elasticsearch there are different ways to build an autocomplete feature. For example, we can configure a field, such as breed for example, as a ‘completion suggester’ in our index mapping. Alternatively, we could simply search all documents every time a character is typed, and populate our dropdown element with data from the returning JSON objects. It was this latter approach we implemented.
The magic happens in the queries we build. I used Kibana's visual interface extensively for testing. My main challenge at this point was to build a query that retrieved pets filtered for ‘up for adoption’, while conducting a fuzzy search in multiple fields and preserving each matching score.
A fuzzy query returns data similar to the searched term using the Damerau–Levenshtein edit distance algorithm: https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-fuzzy-query.html
The edit distance is the number of one-character changes needed to turn one term into another (by deleting, inserting or transposing two adjacent characters). To find similar terms, the fuzzy query creates a set of all possible variations, or expansions, of the search term within a specified distance. The query then returns exact matches for each expansion.
This is how when you type b-e-l-g, you can find similar matches from different fields like breed, and description…
 … and eventually Bertrand, the iguana, shows up as a match!
… and eventually Bertrand, the iguana, shows up as a match!
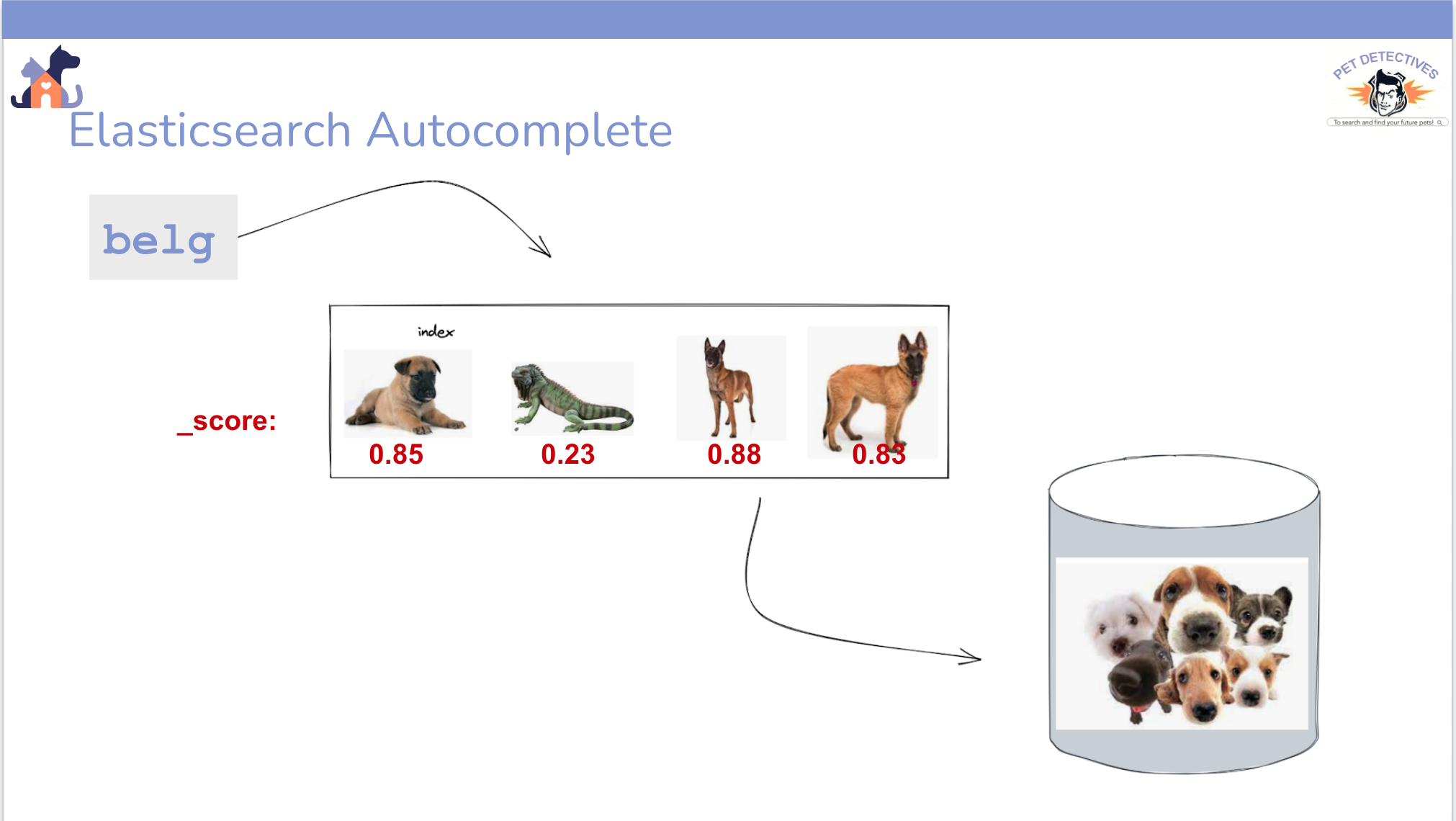
Finally, we can also apply a function score to our query. That is essential when we are also filtering data, because a simple boolean match would ignore scores. In our autocomplete, I used a default script score to wrap the query, but I could have defined any mathematical expression, any weights, or even combined functions. Practically speaking, the score allows us to sort the data retrieved by relevance.