在启动一个PyTorch训练工程之前,除了准备好数据集,还需要配置和初始化以下内容:
1、设定随机种子(random seed): 在训练神经网络时,使用相同的随机种子可以确保实验的可重现性,避免每次运行程序得到不同的结果。一般来说,在程序的开头处使用 torch.manual_seed(seed) 指定随机种子即可。
2、定义网络结构:根据实验需求,需要定义神经网络的结构,包括输入层、隐藏层、输出层以及激活函数等。
3、定义损失函数(loss function):损失函数是机器学习中的重要组件,用以衡量模型预测结果与真实结果的差异。常见的损失函数包括均方误差(MSE)、交叉熵(Cross-Entropy)等。
4、初始化网络参数:通过对神经元权重矩阵、偏置向量等参数进行初始化,可以提高神经网络的性能。PyTorch中可以使用torch.nn.init 模块下的函数进行参数初始化。
5、设置优化器(optimizer)和学习率(learning rate):在神经网络的训练过程中,需要使用优化算法对损失函数进行优化,加速神经网络的学习。目前常用的优化算法包括随机梯度下降(SGD)、Adam、Adagrad 等,而学习率则决定了每次参数更新的步长,需要根据实验需求进行设置。
总之,在启动一个PyTorch训练工程之前,需要先将以上内容进行初始化和配置,以保证训练过程的正确性和稳定性。
1、定义模型:首先需要定义神经网络模型的架构,包括每一层的输入输出大小、激活函数、参数个数等等。
2、定义损失函数:在训练模型时,需要定义一个损失函数来衡量模型预测结果与真实标签之间的差距。
3、定义优化器:在训练模型时,需要使用一个优化器来更新模型参数,使得损失函数值逐渐降低。PyTorch中提供了多种优化器,如SGD、Adam、Adagrad等。
4、定义超参数:优化算法中有一些需要手动指定的超参数,如学习率、权重衰减系数、动量系数等等。这些超参数需要在训练前进行设定,并根据实验结果进行调整。
5、加载数据集:在训练模型时需要加载训练集和验证集,并对数据进行预处理、数据增强等操作。
6、定义训练循环:在训练模型时需要定义一个训练循环,包括对每一批数据的前向传播、反向传播、参数更新等操作。
以上步骤是PyTorch中进行优化算法准备的基本步骤,不同的任务可能需要根据具体需求进行调整。
import ...
# 初始化参数
def get_args():...
class Worker:
def __init__(self, args):
self.opt = args
# 判定设备
self.device = torch.device('cuda:0' if args.is_cuda else 'cpu')
# 将模型和数据移到GPU或CPU上进行训练和推理。如果args.is_cuda为True,则将设备设置为cuda:0,否则设置为cpu。
kwargs = {
'num_workers': args.num_workers,
# 这个参数表示工作程序数量。但要注意进程数量过高可能会导致系统资源占用过多,而影响其他进程的运行。
# 如果在训练期间使用GPU加速,则需要将此变量设置为较高值以确保数据加载不成为主要瓶颈。如果在CPU上训练,则最好将其设置为使用 CPU 核心的数量。
'pin_memory': True,
} if args.is_cuda else {}
# 载入数据
train_dataset = datasets.ImageFolder(
args.train_dir,
# 指定了训练数据的目录,args.train_dir是一个参数,代表了训练数据的目录路径,该路径会被传递给训练代码中的相关函数,使得数据可以被正确地读取和使用。
transform=transforms.Compose([
transforms.RandomResizedCrop(256),
# 对图片进行随机大小裁剪,并将其调整为256x256的大小。
transforms.ToTensor()
# 是一个数据预处理操作,用于将PIL图像或numpy.ndarray数组转换为PyTorch张量(Tensor)格式。
# 在转换过程中,图像的像素值将被缩放到0到1之间,并且通道顺序将被调整为PyTorch所需的顺序(即将通道维度从最后一维移到第二维)。
# transforms.Normalize(opt.data_mean, opt.data_std)
])
)
val_dataset = datasets.ImageFolder(
...
)
self.train_loader = DataLoader(
dataset=train_dataset,
# 将定义数据集用于模型训练,这个操作将数据集传递给模型训练器,这样它就可以使用数据来训练我们的模型。
batch_size=args.batch_size,
# batch_size是指每一次模型训练时,输入的数据分成的小块的大小。这个值决定了一次训练中跑多少个样本。
shuffle=True,
# shuffle=True在模型训练中的作用是使每个epoch中的训练数据顺序随机化,从而增加训练的随机性和稳定性。这样可以防止模型在顺序训练过程中出现输入相关的过拟合现象。
**kwargs
)
self.val_loader = DataLoader(
...
)
# 挑选神经网络、参数初始化
...
self.model = net.to(self.device)#将模型(net)移动到指定的设备(device)上进行训练
# 优化器
self.optimizer = optim.AdamW(
self.model.parameters(),
# 它返回可训练参数的生成器。在模型训练中,它通常用于传递给优化器(optimizer)的参数,以便调整模型参数以最小化损失函数(loss function)。
lr=args.lr
# lr=args.lr 是将命令行参数中传入的学习率赋值给 lr 变量,其中 args.lr 是命令行参数中指定的学习率。
# 这个代码会在模型训练时使用指定的学习率,以控制模型参数的调整速度。
)
# 损失函数
self.loss_function = nn.CrossEntropyLoss()
# 定义模型训练过程中的损失函数,即交叉熵损失函数,用于计算模型预测输出和真实标签之间的差异。
# warm up 学习率调整部分
...
def train(...):...
def val(...):...
if __name__ == '__main__':
# 初始化
...
worker = Worker(args=args)
# 创建了一个名为worker的Worker对象,并将args作为参数传递给它的构造函数,以便在本地或远程计算机上进行多进程训练。
# Worker对象是 PyTorch 的 DistributedDataParallel 组件的一部分,它利用多进程并行计算来加速模型训练过程,并帮助在多个GPU、多个计算机上训练模型。
# 训练与验证
for epoch in range(1, args.epochs + 1):...输入以下命令
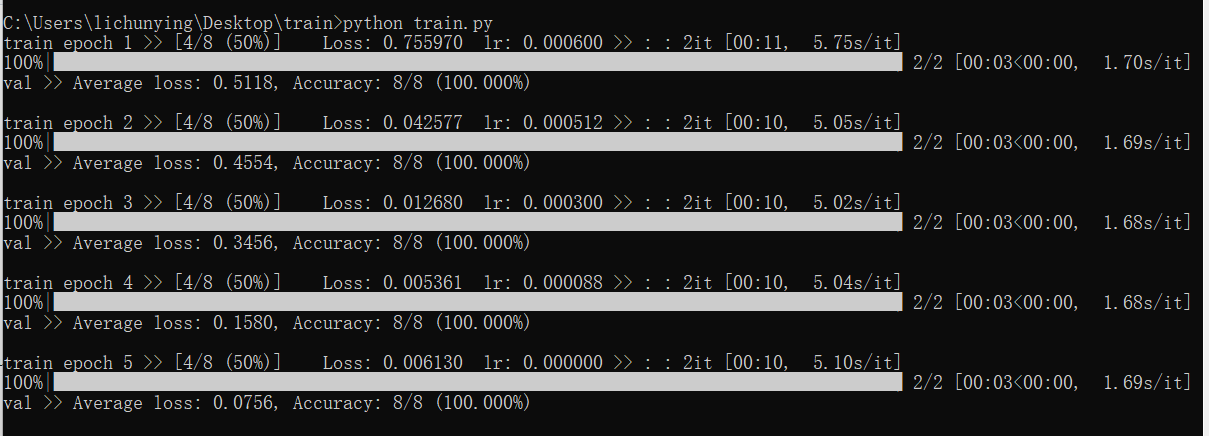
python train.py 训练结果
更改为以下参数
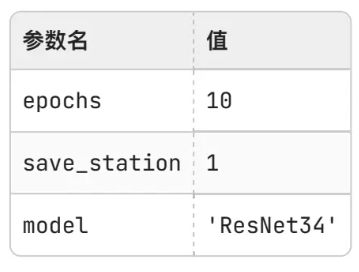
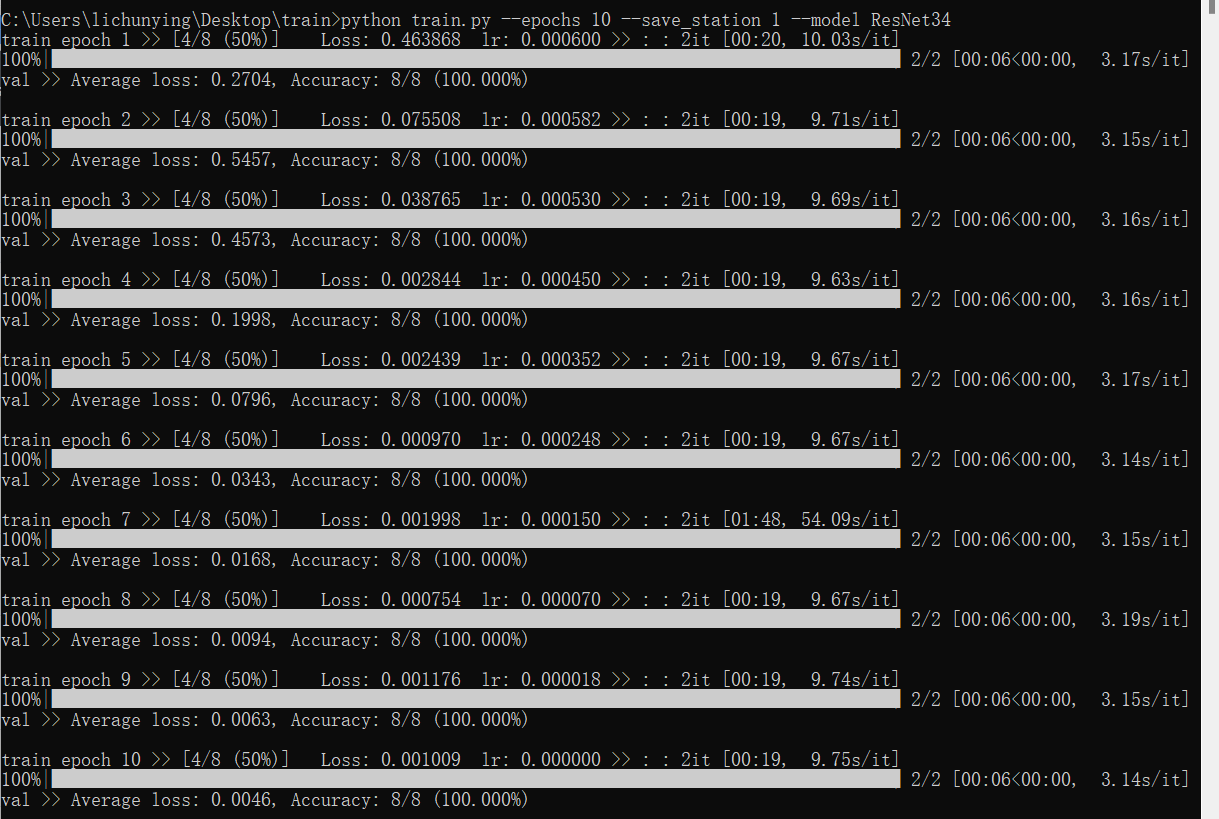
输入以下命令(参数更改后)
python train.py --epochs 10 --save_station 1 --model ResNet34参数更改后的训练结果
1、知道了启动一个Pytorch训练工程之前,除了数据集之外还需要进行的初始化以及在Pytorch 中怎么做好优化的初试准备。
2、了解了如何在终端启动训练并补充命令的参数设置。
3、代码注释的可能不够简洁明了,有点啰嗦。注释一般写在代码上方或右侧,而我写在了代码的下方。