
É um projeto fictício criado pela comunidade DS para que possamos desenvolver nossas habilidades com analise de dados, estátistica, modelagem de dados e modelos de machine learning. Os dados utilizados no projeto se encontram no kaggle (https://www.kaggle.com/c/rossmann-store-sales).
Com o intuito de realizar reformas em algumas lojas, o CFO precisava ter uma previsão a cerca da sua receita para os proximos 6 meses, para saber quanto de Budget ele teria disponível para realizar as reformas.
Diante dessa situação o diretor pediu ao time de dados uma solução que venha fazer essa previsão de forma mais precisa, rápida e prática, podendo acessar de qualquer lugar com um simples smartphone
Os dados foram disponibilizados pela empresa na plataforma Kaggle:
https://www.kaggle.com/c/rossmann-store-sales/data
Abaixo segue a descrição para cada um dos 15 atributos:
| Atributos | Descrição |
|---|---|
| id | um Id que representa um (Store, Date) concatenado dentro do conjunto de teste |
| Store | um id único para cada loja |
| Sales | o volume de vendas em um determinado dia |
| Customers | o número de clientes em um determinado dia |
| Open | um indicador para saber se a loja estava aberta: 0 = fechada, 1 = aberta |
| StateHoliday | indica um feriado estadual. Normalmente todas as lojas, com poucas exceções, fecham nos feriados estaduais. Observe que todas as escolas fecham nos feriados e finais de semana. a = feriado, b = feriado da Páscoa, c = Natal, 0 = Nenhum |
| SchoolHoliday | indica se (Store, Date) foi afetada pelo fechamento de escolas públicas |
| StoreType | diferencia entre 4 modelos de loja diferentes: a, b, c, d |
| Assortment | descreve um nível de sortimento: a = básico, b = extra, c = estendido |
| CompetitionDistance | distância em metros até a loja concorrente mais próxima |
| CompetitionOpenSince[Month/Year] | apresenta o ano e mês aproximados em que o concorrente mais próximo foi aberto |
| Promo | indica se uma loja está fazendo uma promoção naquele dia |
| Promo2 | Promo2 é uma promoção contínua e consecutiva para algumas lojas: 0 = a loja não está participando, 1 = a loja está participando |
| Promo2Since[Year/Week] | descreve o ano e a semana em que a loja começou a participar da Promo2 |
| PromoInterval | descreve os intervalos consecutivos de início da promoção 2, nomeando os meses em que a promoção é iniciada novamente. Por exemplo. "Fev, maio, agosto, novembro" significa que cada rodada começa em fevereiro, maio, agosto, novembro de qualquer ano para aquela loja |
O projeto foi criado através do método CRSIP-DM, aplicando os seguintes passos:
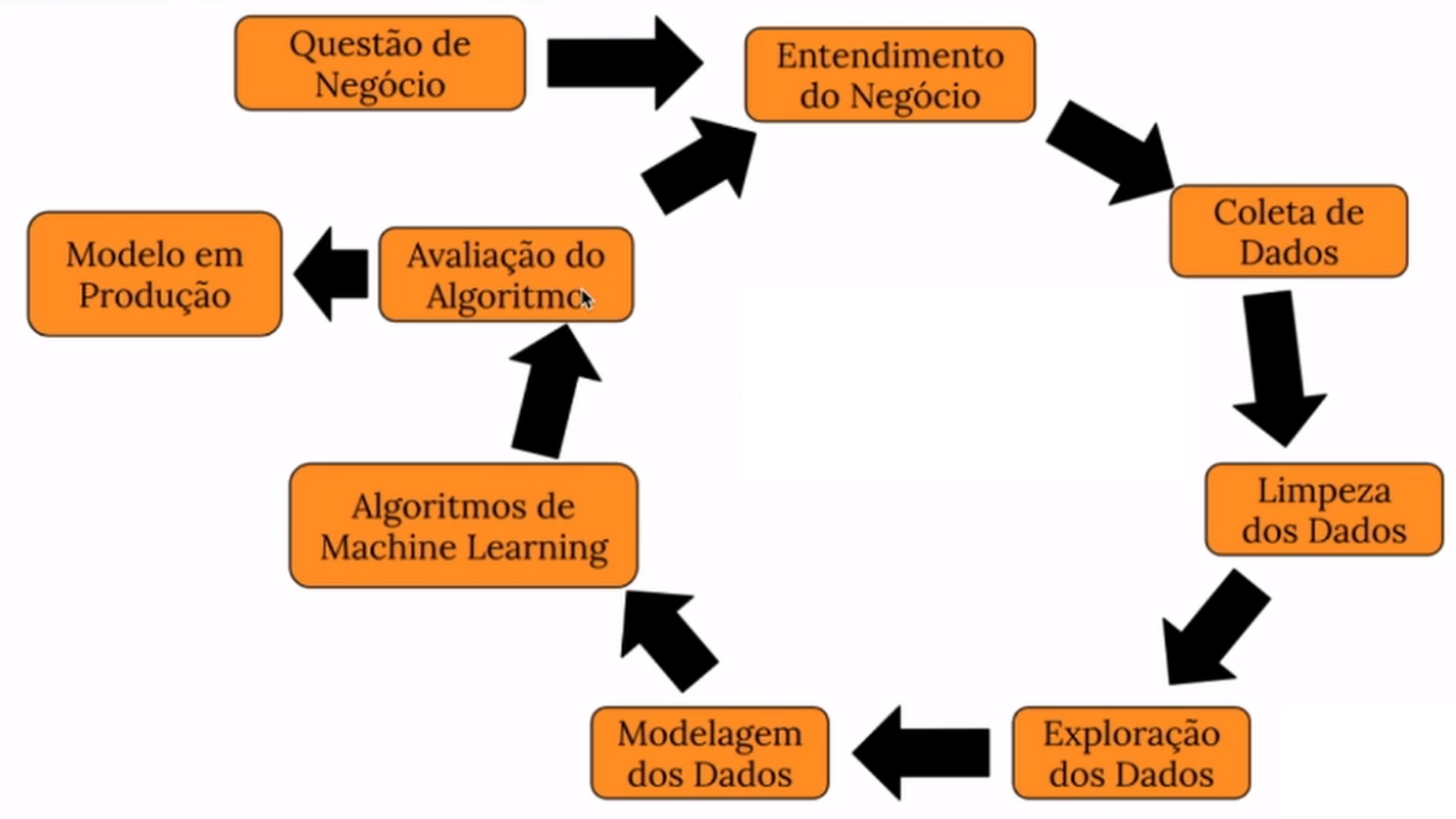
Recebimento do problema a ser resolvido. Qual a previsão de vendas de cada loja em 6 semanas? Para determinar quanto do budget vai para reformas das lojas.
Entender se a questão de negócio levantada faz sentido para solucionar o problema.
No mundo real seria o passo onde fariamos consultas SQL e joins, mas nesse caso apenas fizemos um donwnload no Kaggle https://www.kaggle.com/c/rossmann-store-sales
Nessa etapa foi realizado a descrição dos dados, feature engineering, seleção de features baseadas no negócio.
Nessa etapa criamos algumas hipóteses para nos orientar na exploração dos Dados e encontrar insights, para entender melhor a correlação entre as variáveis com a variavel resposta no aprendizado do modelo. Foram feitas analises univariadas, biváriadas e multivariadas, utilizando os dados numéricos e categóricos do conjunto.
- Lojas com maior sortimento devem vender mais
- Lojas com concorrentes mais próximos devem vender menos
- Lojas com concorrentes mais antigos devem vender mais
- Lojas onde os produtos custam menos por mais tempo (promoções ativas) devem vender mais
- Lojas com mais dias de promoção devem vender mais
- Lojas com promoções mais estendidas devem vender mais
- Lojas abertas no feriado de Natal devem vender mais
- Lojas devem vender mais ao longo dos anos
- Lojas devem vender mais no segundo semestre
- As lojas devem vender mais após o dia 10 de cada mês
- Lojas devem vender menos nos finais de semana
- Lojas devem vender menos durante as férias escolares
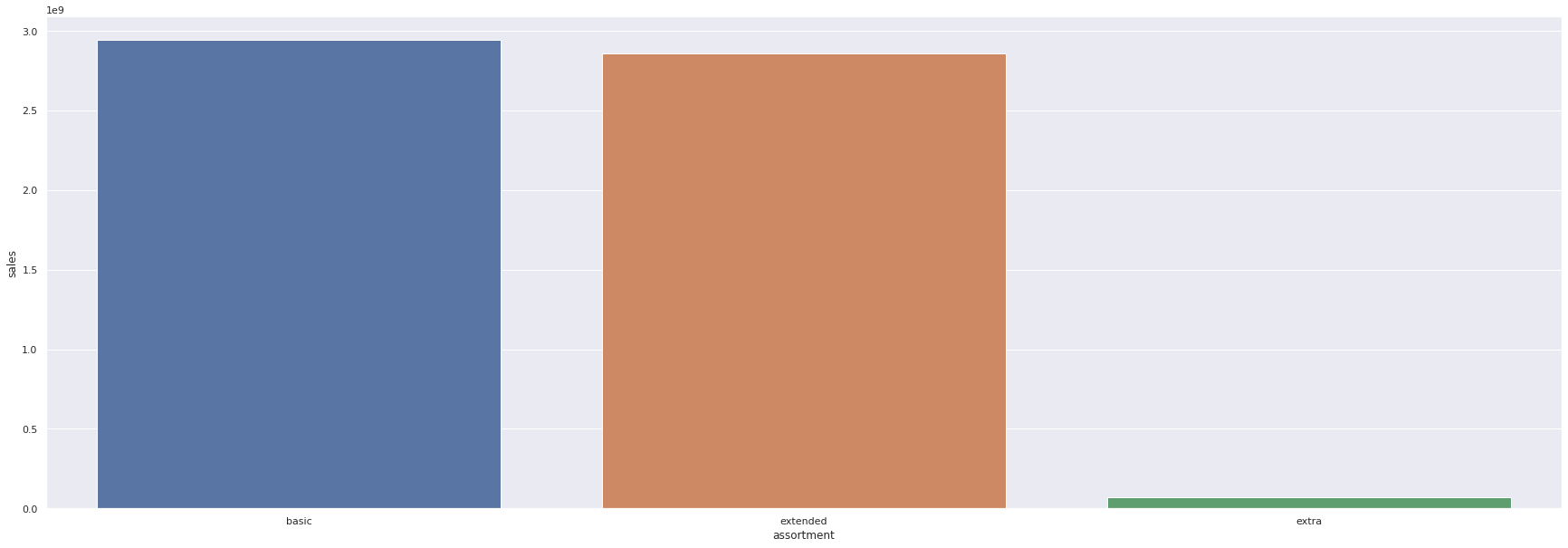
H1. Lojas com maior sortimentos deveriam vender mais.
FALSA Lojas com MAIOR SORTIMENTO vendem MENOS
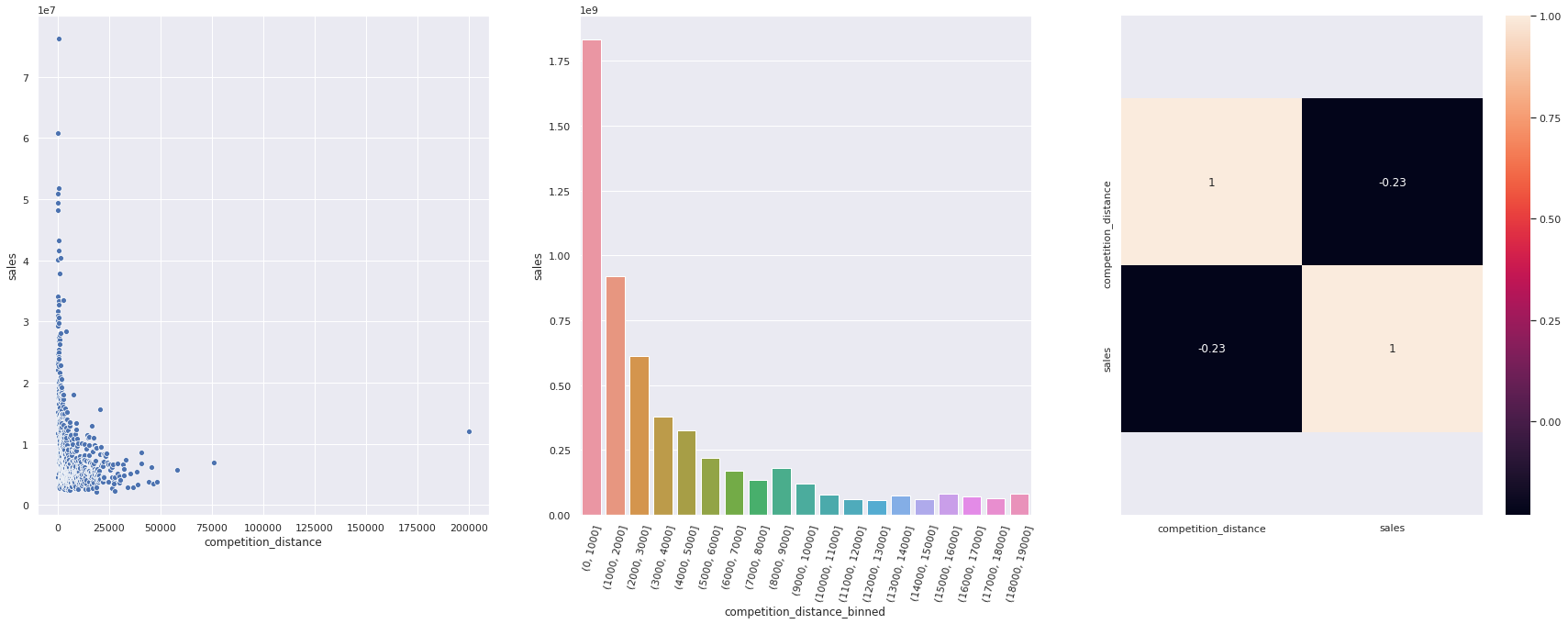
H2. Lojas com competidores mais proximos deverima vender menos.
FALSA Lojas com competidores MAIS PROXIMOS vendem MAIS
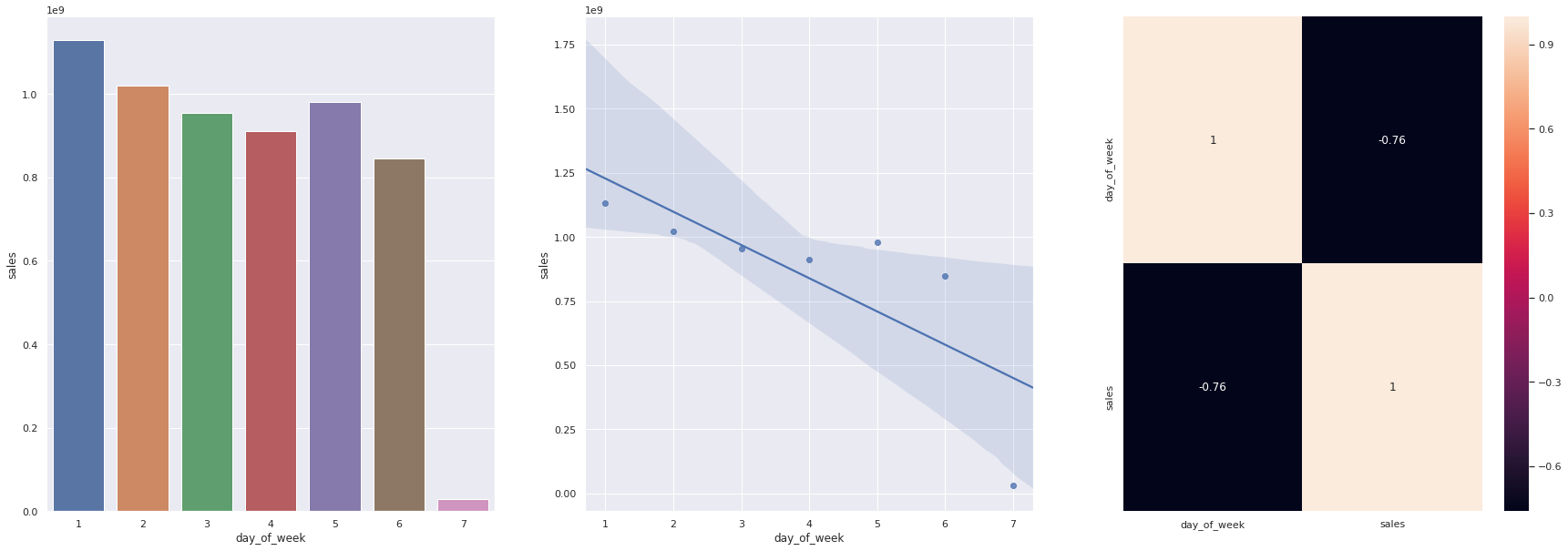
H11. lojas deveriam vender menos aos finais de semana.
VERDADEIRA Lojas vendem MENOS aos finais de semana
Nesta etapa, os dados foram preparados e transformados para o início das aplicações dos modelos de machine learning. Foram utilizadas técnicas de Rescaling e Transformation, através de encodings e nature transformation.
Nesta etapa,foi relizado testes e treinamento em 5 modelos,Random Forest Regressor,XGBoost Regressor, Linear Regression - Lasso, Linear Regressor e Average Model.
Usamos o Average Model como base para compararmos os demais modelos suas respctivas performance e escolha do melhor modelo.
| Model Name | MAE | MAPE | RMSE |
|---|---|---|---|
| Random Forest Regressor | 679.559752 | 0.099934 | 1835.141019 |
| Lasso | 1891.702084 | 0.289165 | 2744.462517 |
| Linear Regressor | 1867.086951 | 0.292756 | 2671.056821 |
| Average Model | 1354.800167 | 0.292756 | 1835.141019 |
| XGBoost Regressor | 6682.680599 | 0.949504 | 7329.927461 |
Também foi aplicada a técnica de Cross Validation para garantir a performance real sobre os dados selecionados.
| Model Name | MAE CV | MAPE CV | RMSE CV |
|---|---|---|---|
| Random Forest Regressor | 838.34 +/- 218.54 | 0.12 +/- 0.02 | 1257.62 +/- 319.71 |
| Linear Regression - Lasso | 2116.39 +/- 341.51 | 0.29 +/- 0.01 | 3057.77 +/- 504.27 |
| Linear Regressor | 2081.73 +/- 295.64 | 0.3 +/- 0.02 | 2952.53 +/- 468.38 |
| XGBoost Regressor | 7047.0 +/- 587.66 | 0.95 +/- 0.0 | 7713.13 +/- 688.72 |
Apesar do modelo XGBoost ter a pior performance no nosso caso, ele foi escolido pois apresenta menor consumo de memória, e ajustando os parametros conseguimos melhorar a sua performance
Hyperparamenter Fine Tunning:
Com o algorítimo XGBoost escolhido na etapa anterior, foi realizada uma análise através do método Randon Search para escolher os melhores valores para cada parâmetro do modelo e encontrar a performance final do XGBoost.
*Os parametros que apresentaram uma melhor performance para o nosso modelo
| n_estimators | eta | max_depth | RMSE | subsample | min_child_weight |
|---|---|---|---|---|---|
| 1500 | 0.03 | 0.12 +/- 0.01 | 9 | 0.1 | 8 |
Desempenho dos dados de teste:
| Model Name | MAE | MAPE | RMSE |
|---|---|---|---|
| XGBoost Regressor | 827.99 +/- 133.09 | 0.12 +/- 0.01 | 1188.78 +/- 189.26 |
Tradução e interpretação de erros:
Nesta etapa o objetivo foi demonstrar o resultado do projeto, onde avaliamos a performance do modelo com viés de negócio, demonstando o resultado financeiro que pode-se esperar do modelo desenvolvido.
| Store | Predictions | Worst_scenario | best_scenario | MAE | MAPE |
|---|---|---|---|---|---|
| 1 | R$162,809.16 | R$162,523.01 | R$163,095.30 | 286.144119 | 0.065905 |
| 2 | R$177,899.85 | R$177,521.56 | R$178,278.15 | 378.295770 | 0.077857 |
| 3 | R$259,576.80 | R$259,078.56 | R$260,075.05 | 498.242727 | 0.071121 |
| 4 | R$341,557.31 | R$340,627.11 | R$342,487.50 | 930.195835 | 0.088787 |
| 5 | R$176,115.39 | R$175,708.34 | R$176,522.44 | 407.050476 | 0.095524 |
Após a execução com sucesso do modelo, foi publicado em um ambiente de nuvem para outras pessoas ou serviços estarem consultando as previsões do modelo e poderem usar os resultados para tomadas de decisões. A plataforma em nuvem escolhida foi o Render (www.render.com).
A etapa final do projeto foi criar um bot no aplicativo de mensagens Telegram, que possibilita consultar as previsões de cada loja de qualquer lugar e a qualquer momento.